누군가에게는 빼빼로데이. 누군가에게는?
• 임동규

호기심 가득
11월 11일 빼빼로데이. 많은 인터넷 서비스 회사들이 빼빼로데이를 맞이하여 여러 이벤트를 준비한 것처럼, 배민 또한 이벤트를 준비했습니다.
아침 11시부터 선착순 1,111명에게 11,000원 할인쿠폰을 발급하는 이벤트.
선착순 이벤트의 특성상 짧은 시간에 과도한 부하가 걸리기 마련이고, 이 때 시스템 장애로 이어진 경우가 있다보니, 치도스 공격이라는 말까지 있었는데요. 이 기억때문인지 뽐뿌에서는 배민고시라는 말까지 나오며 이번 이벤트에 대한 설왕설래가 있었습니다. 그리고 슬프게도… 이번 이벤트에 배달의 민족 서비스는 분명히(어쩌면 반드시) 이벤트 트래픽을 버티지 못하고 다운될 것이라는 예측이… ㅠㅠ

 [고객들의 기대에 부응해야 하는 것인가? ^^;]
[고객들의 기대에 부응해야 하는 것인가? ^^;]
시스템 구성
위에서도 언급했듯이, 배달의민족 이벤트의 특성은 트래픽이 수초 이내에 급격히 상승했다가 소멸된다는 특징이 있습니다. 이러한 트래픽의 형태는 AWS에서 제공하는 Auto-Scale 마저도 무용지물로 만들어 버립니다. Auto-Scale이 될 시점이면 이미 이벤트는 끝나버리기 때문이죠.
따라서 단순히 트래픽에 따른 서버 증가가 아닌, 이러한 이벤트를 처리하기 위한 별도 시스템을 구성하기로 결정했고, 이 시스템의 구성 목표는 순간 트래픽을 유연하게 처리하면서도 기존 서비스 시스템에 최소한의 영향을 미쳐 이벤트로 인한 서비스 지연 등의 장애 포인트를 없애는 것으로 잡았습니다.
시스템은 다음과 같이 크게 세 개의 파트로 분리했습니다.
- 첫째: 이벤트에 참여하기 위한 전단계로 회원인증이 필수단계인데 기존 서비스의 인증체계와 분리한 독립 인증체계를 구성
- 둘째: 이벤트 메인 시스템으로 인증된 사용자가 이벤트에 참여하고 참여한 기록을 저장
- 셋째: 이벤트에 참여한 기록을 통해 당첨자에게 쿠폰을 발급하고 당첨사실에 대해 안내하는 후처리 시스템
Node.js와 Redis의 조합은 Node 인스턴스 하나로 25,000 tps를 버틸 수 있는 것으로 알려져 있는데요. 물론, 25,000 tps라는 숫자는 몰려드는 트래픽을 처리하기 위한 process라는 것이 지극히 단순한 경우이지만 충분히 기대해볼만 하다고 생각했습니다. 다만 인증 파트가 기존 서비스에 연동되어야 한다는 부분은 부담이 될 수 밖에 없었습니다.
인증과 이벤트 메인 시스템은 AWS ElasticBeanstalk 위에 Node.js로 구성했고, 인증과 이벤트 참여 여부에 대한 검사는 AWS ElastiCache(Redis)를 활용했습니다. 이벤트에 참여한 기록에 대한 것은 AWS SQS를 이용해 저장하고 후처리는 AWS ElasticBeanstalk Worker로 구성했습니다.
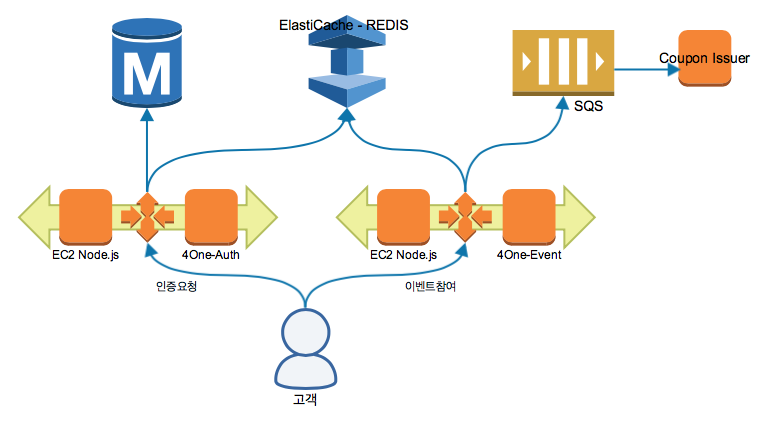 [시스템 구성도]
[시스템 구성도]
위 그림에서 전면에 이벤트 트래픽을 그대로 받아드리는 Node.js는 총 5대의 Instance로 구성했고, 뒤에 인증정보와 이벤트 참여 정보를 저장하는 Redis는 마스터 노드 하나와 리플리케이션 노드 두대로 구성했습니다. 전면의 Node.js에서는 값을 참조할 경우는 Read Replication을 참조하고 인증이나 이벤트 관련 정보를 저장할 때는 Master Node를 보도록 구성했고요. (하지만 이 구성의 맹점은 여기에 있었으니, 뒤에서 공유하겠습니다. ㅠㅠ)
이렇게 시스템 구성을 끝내고, 부하테스트 환경을 통해 이벤트 시스템에 부하를 가하면서 시스템의 상태를 점검하고 튜닝하는 과정을 진행했으나… 테스트 환경에서는 ELB의 Warm-up이 되어있지 않은 이유로 50만 트래픽까지 부하를 주지는 못하고 그 이하 수준에서 종료하게 됩니다. (여기서도 얻은 한 가지 교훈은 부하테스트를 하려면, 테스트환경의 ELB도 AWS쪽에 pre warm-up을 신청해 놔야 한다는… -_-;)
엥? 끗?! 1.89초
드디어 이벤트 당일. 이벤트 시간이 점점 다가올수록 처음 느긋함과는 다르게 조금씩 긴장이 되기 시작했습니다.
시스템 점검은 완료했고 요청했던 ELB의 warm-up도 완료되었다고 연락을 받은 후, CTO실 사람들뿐 아니라, 유관부서의 담당자들이 점점 자리에 몰려들기 시작하고… 다른 구성원들도 혹시 있을지 모르는 과부하 발생으로 인한 장애에 대비하게 됩니다. 다들 각자 모니터에 CloudWatch와 NewRelic를 띄워 놓고, 모니터링을 진행하던 두 눈에 힘을 주기 시작했습니다. ^^;
미리 이벤트를 찔러(?) 보는 고객들의 요청으로 인해 트래픽이 증가하기 시작하고…
이제 십여초 전…
이벤트에 참여하려는 고객들의 인증 요청을 시작으로 트래픽이 급격히 상승하기 시작합니다. 그리고 몇 초가 지나자, 시스템 전체적으로 트래픽이 수직 상승하며 이벤트가 진행중임을 실감하게 만들었습니다.
그리고… 11시 정각… 1초, 2초… 엥??
약간의 환호와 ‘버텼어!!’라는 외침과 함께 이벤트가 종료됩니다.
- 1.89초 - 이벤트가 마감되기까지 걸린 시간
- 100배 - 이벤트 시스템이 받아낸 초당 트래픽은 평소 최대치의 100배
이벤트가 원활하게 수행된 정도가 아니라, 좀 싱거울 정도로 허무하게 몇 초만에 마무리되고 시스템은 바로 평상시 모드로 돌아오게 됩니다. 흐흐흐. 아래는 해당 시간 트래픽 변동에 대한 그래프입니다.
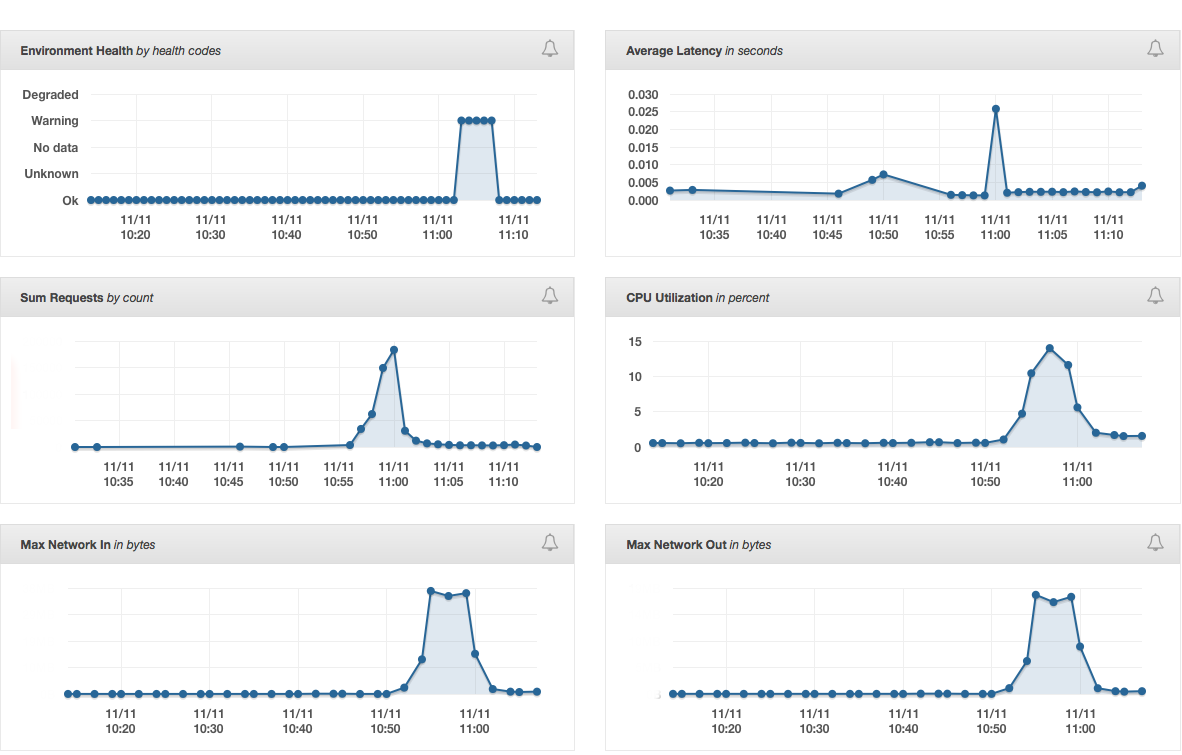
너무나 평온하게 끝난 이벤트. 11,000원 할인이기에 작년과 재작년에 진행했던 블랙프라이드데이보다 더 많이 사람들이 몰릴 거라 예상했는데, 성공적으로 끝낸 기쁨에 다들 축하하며.. 그렇게 11월 11일의 오전 시간이 지나갑니다.
아뿔싸…ㅠ
이렇게 아름답게 끝났어야 했는데… 이쁘기만 했던 이벤트 트래픽 그래프 뒤로 숨어있는 폭탄이 있었는데요. 이벤트에 당첨된 회원들에게 쿠폰을 발급하려는데 문제가 생겼습니다..
어? 1,111명 보다 많은데?? 1,111명보다 많은 수가 이벤트 당첨 기록에 남아 있었습니다. 뭐지??
일단 당첨은 당첨이니, 마케팅실과 협의하여 초과된 당첨에 대해서도 쿠폰은 발행하고, 문제가 된 부분을 찾기 시작합니다. 소스코드를 여러 번 살펴봐도 잘못된 점이 보이질 않았는데요. 한참을 살펴 본 후, 원인을 찾아냅니다. 문제는 소스코드가 아닌, 시스템 구성에 있었습니다.
앞에 이야기한 것처럼 Redis를 마스터노드 하나와 리플리케이션 노드 둘로 구성했는데요. 이 Redis의 주요한 기능 중의 하나는, 당첨자를 제한하기 위한 카운터였습니다. 이벤트에 당첨된 고객이 나오면 카운터를 증가시켰고 이벤트에 참여하려는 회원은 반드시 이 카운터를 참조해 기회가 있는지 조회하는 구조였죠. 이 때, 카운터 증가는 마스터 노드에 하고 참조는 리플리케이션 노드에서 수행하게 됩니다.
바로 이 부분이 문제였습니다.
워낙 짧은 시간에 많은 요청이 있었기 때문에, 마스터 노드에 증가된 카운터 값이 미처 리플리케이션 노드에 복제되기 전에 밀고 들어온 이벤트 참여자의 경우 카운터 제한에 걸리지 않고 참여할 수 있었던 거죠.
결국 이 정도의 트래픽 러쉬에서는 카운터와 같은 기능은 복제를 쓰지 말고 마스터를 참조해야 한다는 큰 깨달음을 얻었습니다.
이런 경험을 통해 분명 또 다른 포인트를 배웠지만, 정말 처음부터 끝까지 완벽하게 수행하고 싶었던 욕심이 있었기에 한편으로는 너무나 맘이 아프고 안타까운 오점을 남기고 말았네요. ^^
블랙후라이드데이 시즌3
참. 마지막으로 공지사항 하나.
올해도 블랙후라이드데이 시즌3가 진행됩니다. 많은 관심 부탁 드립니다. ^^;