Legacy DB의 JPA Entity Mapping (복합키 매핑 편)
• 손현태

안녕하세요. 우아한형제들에서 배달의민족 서비스의 광고시스템을 개발하고 있습니다. 시스템을 점진적으로 Spring Boot / JPA 기반으로 이관하면서 경험했던 내용을 공유하고자 합니다.
Legacy DB의 JPA Entity Mapping (복합키 매핑 편)
어느 회사든 Legacy System 라고 불리는 회사의 주요 비즈니스를 책임지는 시스템이 있을 것입니다. 저희 배달의민족도 마찬가지구요. 회사의 주요 비즈니스를 책임지고 있지만, 사업의 더큰 확장을 위해서는 개선이 필요할 시점이 오는데요. 저희팀에서는 Legacy System 을 점진적으로 분리해서 신규시스템으로 이관하는 전략을 선택 했습니다.
그래서 저희는 꾸준히 Spring Boot / JPA (기존 RDBMS는 유지) 를 이용해서 시스템을 분리해 내고 있는데요. 분리하면서 가정 먼저 해야 했던게 레거시 테이블에 대해서 Entity 매핑하고 나서 JOIN 으로 얽혀 있는 코드들을 API로 격리 시키는 작업이 필요했습니다.
그 중에서 Entity Id 매핑방법에 대해서 저희팀의 경험을 공유 드리고자 합니다.
-
JPA를 사용할때는 흔히 처음부터 하는 개발에 적합하다고들 하는데요. 레거시 테이블들에도 매핑할 수 있고, 그중 하나의 시행 착오에 대해서 공유 드릴려고 합니다. 기존의 레거시 테이블들이 많을 때, JPA 를 어떻게 도입할지 방향성을 잡는데 도움이 되었으면 좋겠습니다.
-
기존 테이블들은 복합키(Composite Key)를 많이 사용하고 있어고 테이블간의 관계는 식별관계 매핑을 많이 사용하고 있었습니다. 따라서 복합키를 사용하는 Entity 들이 상당히 많았습니다.
-
JPA 좀 공부하면 알겠지만, 복합키 매핑이 Entity 매핑할때, 코드량이 증가하는걸 알 수 있을 것입니다. (포기 하지 말아요… 이건 한번만 해두면 후에 편해요.)
레거시 RDB 의 테이블 PK 생성 전략
배달의민족 기존 레거시 광고시스템은 데이터와 테이블중심으로 설계되어서 운영되고 있었습니다. 따라서 PK 생성하는 룰이 존재 했었으며, MS-SQL 의 IDENTITY 는 거의 사용하지 않는 상황이였습니다. 그리고 복합키(Composite Key)를 정말 많이 사용하고 있었는데요. 좌절하지 않고 테이블 매핑에만 일주일 이상 들여가며 방법을 찾아 갔습니다.
테이블 연관관계를 설정할 때, 복합키를 가진 테이블과 연관관계를 만들때는 다음과 같이 2 가지의 방법이 있습니다.
- 식별관계 매핑
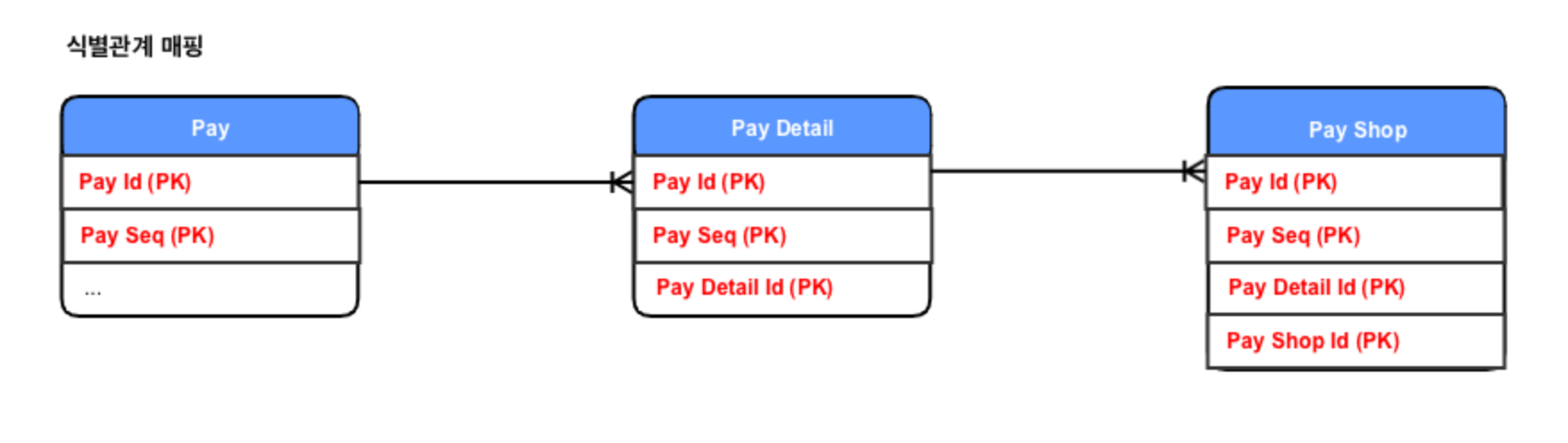
부모 테이블의 기본키를 자식 테이블로 전파하면서 자식 테이블의 기본키 컬럼이 점점 늘어난다. JOIN 할때 SQL 이 복잡해지고 기본 키 인덱스가 불필요하게 커질 수 있다. 그리고 구조적인면에서도 유연한 구조를 가지지 못한다.
식별관계를 사용할 때 기본키로 비즈니스 의미가 있는 자연 키 컬럼을 조합하는 경우가 많다.
하지만, 장점도 있다. 기본 키 인덱스를 활용하기 좋고, 부모 테이블의 기본 키 컬럼을 자식, 손자 테이블들이 가지고 있으므로 특정 상황에 조인 없이 하위 테이블만으로 검색을 완료 할 수 있다.
- 비식별관계 매핑
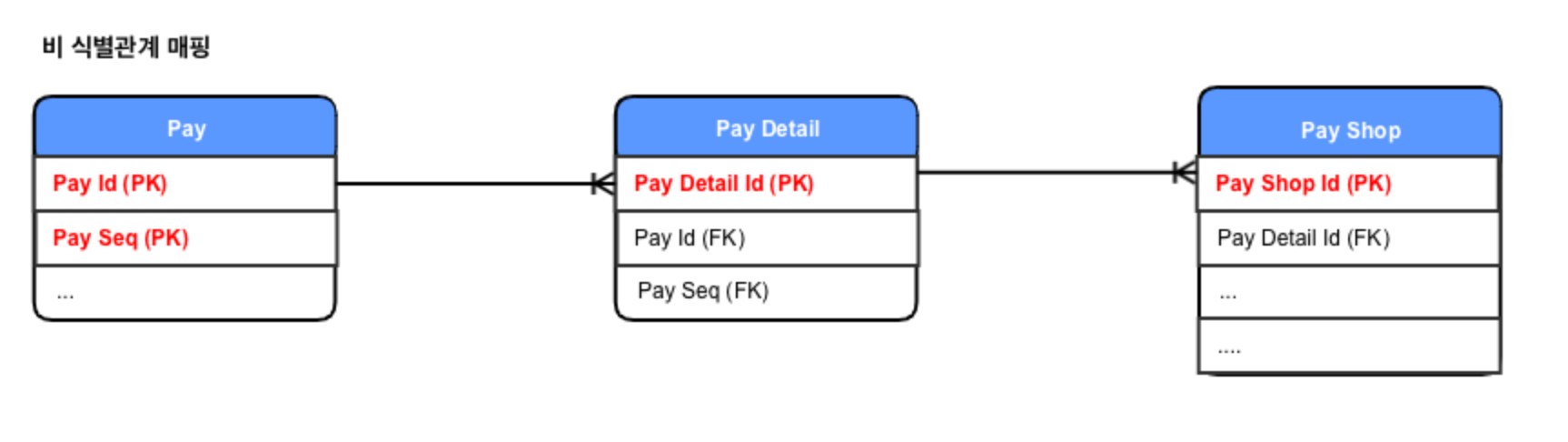 )
)
아래에 설명하겠지만, 복합키를 사용하면 JPA에서는 별도의 IdClass 를 생성해야 한다. 따라서 컬럼이 하나인 기본 키를 매핑하는 것보다 많은 노력이 필요하다.
비식별 관계에서 기본키는 대부분 대리키를 사용한다. 이때 JPA 에서는@GenerateValue를 사용하면 편리하게 생성 할 수 있다.
저희 Legacy 시스템에서는 대부분 식별관계 매핑을 사용하고 있었습니다. (이때 까진 몰랐어요. 복합키 매핑의 그렇게 복잡할 지는…) 아무래도 기존 Legacy 시스템이 테이블 및 데이터 중심의 개발방법 이여서 식별관계 매핑을 사용하는 장점은 분명이 있습니다. (예를 들어 특정 Pay_Id 값으로 Pay_Shop 테이블에서 조회할때 테이블 JOIN이 많이 단순해 집니다.)
JPA를 이용하여 복합키 매핑을 하는 방법은 크게 2가지가 존재하는데요. 어떻게 하는지에 대해서 좀더 정리 해 보려고 합니다.
JPA를 이용한 복합키(Composite Key) 매핑 방법
앞서 설명드린 것처럼 저희 레거시 테이블들은 식별관계 매핑을 사용했기 때문에 위에 설명드린 테이블들의 관계를 예제 코드로 보여 드리겠습니다.
본문 내용의 길이상 Pay_Shop 테이블만 본문에 추가하도록 하고 나머지소스는 github 에 소스를 공개 해두었습니다.
@EmbededId 를 통한 매핑
책에서도 안내하고 있지만, @EmbededId는 @IdClass 방식 보다 좀더 객체지향 방식입니다. 그래서 처음에는 호기롭게 @EmbededId 를 사용해서 아래와 같이 코드를 작성 했었습니다.
PayShop.java
@Getter
@Entity
@NoArgsConstructor
public class PayShop {
@EmbeddedId
private PayShopId id;
private String shopName;
@MapsId(value = "payId")
@ManyToOne(fetch = FetchType.LAZY)
private Pay pay;
public PayShop(PayShopId id,
String shopName) {
this.id = id;
this.shopName = shopName;
}
public void setPay(Pay pay) {
if (pay != null) {
pay.getPayShops().remove(this);
}
this.pay = pay;
this.pay.getPayShops().add(this);
}
}
@MapsId 를 통해서
Pay에 있는 id 값을 자동으로 할동되게 할 수 있음.
PayShopId.java
@Getter
@EqualsAndHashCode(onlyExplicitlyIncluded = true)
@Embeddable
@NoArgsConstructor
public class PayShopId implements Serializable {
/**
* 테이블에서 정의하는 컬럼 사이즈
*/
public static final int SHOP_NUMBER_SIZE = 12;
@EqualsAndHashCode.Include
private PayDetailId payDetailId;
@EqualsAndHashCode.Include
@Column
private String shopNumber;
public PayShopId(PayDetailId payDetailId,
String shopNumber) {
Preconditions.checkArgument(shopNumber.length() <= SHOP_NUMBER_SIZE);
this.payDetailId = payDetailId;
this.shopNumber = shopNumber;
}
}
위 예제와 같이
shopNubmer라는 값의 컬럼사이즈를 초과해서 입력받아지지 않도록 체크를 할 수 있다.
PayDetailId.java
@EqualsAndHashCode(onlyExplicitlyIncluded = true)
@Embeddable
@NoArgsConstructor
public class PayDetailId implements Serializable {
@EqualsAndHashCode.Include
private PayId payId;
@EqualsAndHashCode.Include
@Column
private Long payDetailId;
public PayDetailId(PayId payId,
Long payDetailId) {
this.payId = payId;
this.payDetailId = payDetailId;
}
}
PayId.java
@Getter
@EqualsAndHashCode(onlyExplicitlyIncluded = true)
@Embeddable
@NoArgsConstructor
public class PayId implements Serializable {
/**
* 결제번호 (비즈니스적으로 유의미한 번호)
*/
@EqualsAndHashCode.Include
@Column
private Long payNumber;
@EqualsAndHashCode.Include
@Column
private Long paySeq;
public PayId(Long payNumber,
Long paySeq) {
this.payNumber = payNumber;
this.paySeq = paySeq;
}
}
코드는 아주 객체지향스럽고 깔끔하고 멋졌지만, 비즈니스적으로 유의미한 값인 PayNumber 를 사용하기 위해서는 객체 그래프 탐색을 깊이 해야만 하고 IdClass 속에 깊이 감춰져 있어서 명시적으로 보이지 않는 점이 있습니다. 그리고 객체의 구조가 복잡합니다.
코드로 보여 드리면 만약 payShop 객체에서 PayNumber 를 가져올려면 다음과 같이 복잡하게 그래프탐색을 해야합니다. (JPQL 을 이용하여 ID 컬럼의 값을 읽어 올때도 동일한 문제 발생)
payShop.getId().getPayDetailId().getPayId().getPayNumber();
@IdClass 를 통한 매핑
그래서 우리는 @IdClass 통한 매핑을 사용하였습니다. 긴 설명보단 아래의 예제 소스로 설명드리는게 더 빠를 듯 합니다.
PayShop.java
@Getter
@Entity
@Table(name = "pay_shop")
@IdClass(PayShopId.class)
@NoArgsConstructor
public class PayShop {
@Id
private Long payNumber;
@Id
private Long paySeq;
@Id
private Long payDetailId;
@Id
private String shopNumber;
private String shopName;
@ManyToOne(fetch = FetchType.LAZY, optional = true)
@JoinColumns(value = {
@JoinColumn(name = "payNumber", updatable = false, insertable = false),
@JoinColumn(name = "paySeq", updatable = false, insertable = false),
@JoinColumn(name = "payDetailId", updatable = false, insertable = false)
}, foreignKey = @ForeignKey(value = ConstraintMode.NO_CONSTRAINT))
private PayDetail payDetail;
public PayShop(Long payNumber,
Long paySeq,
Long payDetailId,
String shopNumber,
String shopName) {
this.payNumber = payNumber;
this.paySeq = paySeq;
this.payDetailId = payDetailId;
this.shopNumber = shopNumber;
this.shopName = shopName;
}
/**
* 연관관계 매핑 메소드
*/
public void setPayDetail(PayDetail payDetail) {
if (payDetail != null) {
payDetail.getPayShops().remove(this);
}
this.payDetail = payDetail;
this.payDetail.getPayShops().add(this);
}
}
위 코드를 보면 연관관계를 맺은 객체의
@JoinColumn을 보면 각 필드에updatable = false, insertable = false가 붙어 있다.
이 부분은 연관관계만 맺는 역할 만 하고 실제 값은 @Id 컬럼을 실제 매핑에 이용하게 된다.
그래서 우리는 생성자를 통해서 @Id 컬럼의 값들을 할당하고 따로 연관관계도 맺어주어야 했다.
PayShopId.java
@EqualsAndHashCode(onlyExplicitlyIncluded = true)
@NoArgsConstructor
public class PayShopId implements Serializable {
@EqualsAndHashCode.Include
@Id
private Long payNumber;
@EqualsAndHashCode.Include
@Id
private Long paySeq;
@EqualsAndHashCode.Include
@Id
private Long payDetailId;
@EqualsAndHashCode.Include
@Id
private String shopNumber;
}
전체코드를 보시면 아시겟지만, payNumber, paySeq, payDetailId, shopNumber 가 계속 중복으로 Entity 마다 작성되는 반면에 기존의 테이블 구조와 일치하는 느낌을 받으실 겁니다.
그래서 우리는 @IdClass 방법을 선택함
| @EmbededId | @IdClass | |
|---|---|---|
| 장점 | - 객체지향적이다. (예제의 shopNumber 컬럼체크) - @MapsId를 이용한 객체생성 편리 |
- 비즈니스적으로 의미있는 PK 값이라면 명시적으로 필드를 노출할 수 있다. - 식별관계 매핑을 여러 테이블에서 사용할때, 객체 연관관계를 단순하게 유지 가능 |
| 단점 | - 복합키구조가 2개이상 테이블에 식별관계로 매핑이 될때 복잡도가 증가한다. | - 컬럼에 대한 필드선언이 중복이 발생한다. - @MapsId 활용이 불가능하여 객체 생성할때 주의를 요함 |
위 예제에서도 보았듯이 shopNumber 란 의미있는 ID값을 얻기 위해서는 Entity Class 에서 바로 보이지 않는다는 단점과 너무 IdClass 들이 중첩구조로 겹겹이 쌓여진다는 단점이 있었습니다.
단순한 하나의 복합키만 존재한다고 하면 @EmbededId 를 사용하라고 권하고 싶습니다. 하지만 복합키를 통한 식별관계 매핑이 여기저기 존재한다면, @IdClass를 이용하라고 권하고 싶습니다.
이는 중복을 조금더 허용하더라도 Legacy Table 의 설계 의도를 Entity 에 녹여서 명시적인 객체구조를 가져갈수 있었습니다. 그리고 심플한 구조(엔터프라이즈 환경에서는 무엇보다 심플함이 최고!)를 가질 수 있어 기존의 운영중이 테이블과 이질감이 느껴지지 않는 방법을 선택하게 되었습니다.
하지만, 위 표에 설명드렸듯이 단점도 분명히 존재합니다만 현재 우리가 운영중인 광고시스템의 테이블들을 JOIN 으로 사용하는 부분들을 API 로 철저하게 분리 및 격리한 후에 시스템을 재개발 할 예정입니다. 이후 신규 시스템에서는 비식별관계를 사용하고 기본 키는 Long 타입의 대리키를 사용할 것입니다.
마치며
처음에 블로그에 글을 공유하려고 했을 때의 의도가 잘 전달이 되었는지 모르겠네요. 사실 글을 정리하다 보니 아래 참고자료에 명시한 책의 내용을 그냥 정리하는 수준이지 않을까 하는 생각이 들기도 했습니다.
하지만, 실제로 기존에 쿼리중심의 Legacy System 을 점진적으로 이전하기 위해서는 엔티티 매핑과정은 거쳐야할 과정이고 그 과정에서 부딪힐 수 있는 고민거리를 공유 한다는것에 의미를 부여하고 싶습니다.
혹자는 JPA를 도입하려면 완전히 새롭게 개발하는게 편하다고 하는데요. 네, 맞습니다. 그 방법이 가장 깔끔합니다만, 달리는 마차를 통째로 바꾸는건 리스크가 많기 때문에 신중을 기해야 하죠. 저희 팀에서는 점진적으로 새로운 기술스택의 신규시스템으로 이전 할수도 있다는걸 보여드리고 싶었습니다. (이런걸 교살자 패턴(strangler pattern) 이라고 하더군요.)
오늘 내가 작성한 코드가 내일의 레거시이긴 하지만… 지금도 Legacy System 을 운영하면서 고통받는 개발자들에게 한줌 희망이 되었으면 좋겠습니다.
본문 내용중의 잘못된 점이나 궁금한 점은 적극적인 피드백 부탁 드립니다.