파일럿 프로젝트를 통한 배치경험기!
• 최유성

들어가며
안녕하세요 !
우아한 테크캠프 2기를 통해 1월에 결제정산개발팀에 합류하게 된 최유성입니다.
입사 후 총 5주간 신입 개발자의 팀 적응을 위한 파일럿 프로젝트를 진행하였습니다.
지금부터 그 5주간의 파일럿 프로젝트에 대한 경험을 공유하겠습니다.
시작!

입사한 첫날 긴장한 저를 위해 팀에서 준비한 선물이 있었는데요, 그 선물은 바로 파일럿 프로젝트였습니다. ㅎㅎ..
파일럿 프로젝트의 주제는 상태 비교 작업을 위한 배치 어플리케이션의 구현!
처음 실무를 접해본 신입개발자분들에게는 익숙하지 않은 주제일 텐데요, (저만 그랬나요..?) 저 또한 배치라는게 있구나 정도만 알고 있었지 만들거나 공부해 본적이 없었습니다.
그래서 저처럼 배치를 처음 접해보는 개발자들에게 도움을 드리고자 제가 어떤식으로 배치 어플리케이션에 접근하였는지 공유하겠습니다.!
 [결제정산개발팀에서 준비한 프로젝트…]
[결제정산개발팀에서 준비한 프로젝트…]
개발에 들어가기 앞서 2일 정도는 배치가 무엇이고 Spring Batch로 구현했을 때의 장점이 무엇인지 알아보는 시간을 가졌습니다.
제가 이해한 배치는 대용량의 데이터을 가지고 정해진 작업을 순차적으로 수행하는 것입니다.
이런 대용량의 작업을 웹 어플리케이션으로 처리한다면 서버의 자원을 I/O작업에 다 써버려 사용자의 요청을 처리하는 web기능을 잘 수행하지 못할 것입니다.
그래서 배치 어플리케이션을 통해 이러한 문제를 해결할 수 있는데요, Spring Batch는 이러한 배치 작업을 할 때 유용하게 쓰일 수 있는 인터페이스와 스프링의 기능을 제공합니다.
뿐만 아니라 사용자가 비즈니스 로직에 집중할 수 있도록 부가적인 기능들도 지원합니다!
(좀 더 깊은 내용을 알고 싶으신 분들은 jojoldu님의 배치시리즈! 추천합니다!!)
1주차 ) Job과 Step 설계
* JOB
첫 시작은 JOB 을 나누는 작업을 진행하였습니다.
배치에서 JOB은 하나의 배치 작업 단위이고, 서로 상관관계가 있는 작업들이 뭉쳐 하나의 JOB을 이루게 됩니다.
저는 프로젝트의 요구사항을 보고 세가지의 JOB으로 나누었습니다.
1.FILE -> Mysql table 저장
- CSV(배민)와 EXCEL(배달이)로 된 데이터를 읽어 entity로 변환하여 하나의 테이블에 원천 데이터 형태 그대로 저장한다.
2.배민 거래내역 Compact Job
- 배민의 데이터를 성공과 실패로 나누어 읽어 메모리상에 올려놓는다.
- 두 데이터를 비교조건에 맞추어 중복데이터를 제거한다.
- 당월 주문 다음달 취소는 성공데이터로 전월 주문 당월 취소는 취소데이터로 처리한다.
3.상태비교 JOB
- 비교작업을 거친 배민의 데이터를 기준으로 배달이의 데이터를 비교하여 누락결과와 서로 상태가 다른 데이터를 저장한다.
- 배민데이터의 성공,실패 건수와 비교결과를 csv파일로 출력한다.
* Step
Step은 Job안에 존재하는 하나의 역할입니다.
밑에 코드에서 생성하는 Step을 하나 보시면 Reader, Processor, Writer로 이루어져 있습니다.
이름 그대로 데이터를 읽고 가공하고 쓰는 작업을 합니다.
저는 첫번째 Job의 첫번째 Step에게 배민 파일을 DB에 저장하는 역할을 부여하였습니다.
@Bean
@JobScope
public Step saveBaeminApprovalDataStep() { //-> 배민 파일 읽어 저장
return stepBuilderFactory.get("saveBaeminDataStep")
.<HistoryDto, OrderHistory>chunk(chunkSize)
.reader(baeminHistoryItemReader()) // MultiResourceItemReader
.processor(baeminHistoryItemProcessor()) // dto에서 -> entity로 변환
.writer(orderHistoryJpaItemWriter()) // JpaItemWriter
.build();
}
이 역할을 수행하기 위해서는 3가지 작업이 필요한데요,
1. 파일을 읽는 작업
@Bean
public MultiResourceItemReader<? extends HistoryDto> baeminHistoryItemReader() {
MultiResourceItemReader<HistoryDto> itemReader = new MultiResourceItemReader<>();
itemReader.setDelegate(CustomFileReader.getBaeminReader();
itemReader.setResources(downloadResources(...));
return itemReader;
}
- multiItemReader에 커스텀하게 구현한 FlatFileItemReader 구분자로 세팅하였고, 다운받은 파일을 리소스로 설정하였습니다.
- 여러 파일을 읽어야 하기 때문에 MultiResourceItemReader를 사용했습니다.
2. 파일을 읽어 넘어온 DTO를 Entity객체로 변환하는 작업
3. 디비에 넘어온 Entity를 저장하는 작업
@Bean
public JpaItemWriter<OrderHistory> orderHistoryJpaItemWriter() {
JpaItemWriter<OrderHistory> writer = new JpaItemWriter<>();
writer.setEntityManagerFactory(entityManagerFactory);
return writer;
}
- JpaItemWriter는영속성 관리를 위해 EntityManager를 할당이 필수로 해주어야 합니다.
처음에는 csv파일을 읽고 쓰는 작업을 하기위해 custom하게 ItemReader를 구현해야 하나? 라는 생각에 막막했습니다.
그런데 이미 Spring Batch에서 많은 형태의 데이터를 읽을 수 있도록 여러 ItemReader가 구현되어져 있어 편하게 가져다 쓸 수 있었고 ItemWriter 또한 JDBC와 ORM 모두 제공하기 때문에 사용자가 원하는 방식으로 데이터베이스에 쉽게 저장할 수 있었습니다.
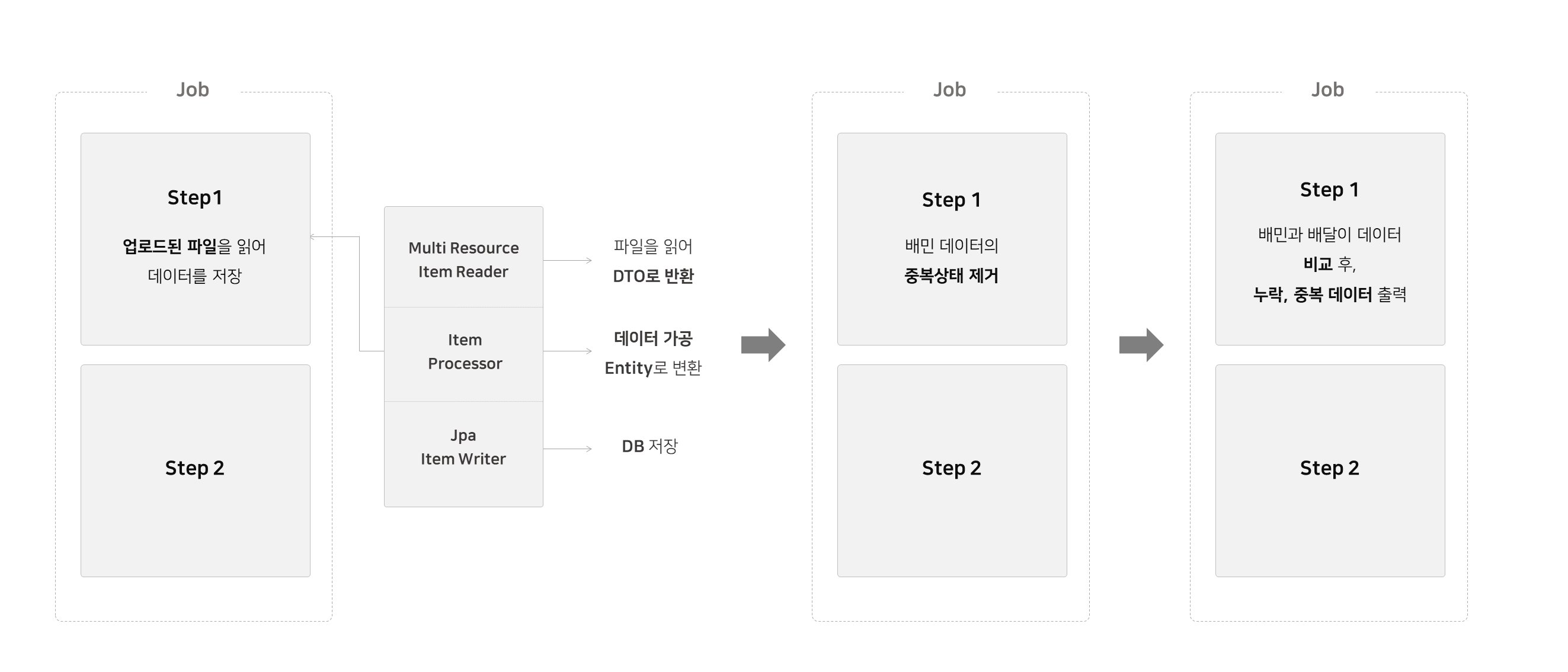
2주차 ) 상태 비교 작업
비교 작업은 DB에서 데이터를 읽어 메모리상에 올려놓고 진행하였습니다.
우선 데이터의 양이 300만건 정도라 메모리에 올려도 무리가 없었고, 지금 현재 요구사항에서는 배치 어플리케이션에 대한 동시요청을 고려 안해도 된다는 점에서 이런 선택을 하게 되었습니다.
@Bean
public Job compareResultJob() {
return jobBuilderFactory.get(JOB_NAME)
.incrementer(new RunIdIncrementer())
.start(importBaeDalHistoryStep()) // 배달이의 데이터를 메모리에 저장
.next(importBaeminHistoryStep()) // 배민의 데이터를 메모리에 저장
.next(compareOrderHistoryStep()) // 비교작업 수행
.next(reportOrderCompareResultStep()) // 결과를 파일로 출력.
.build();
}
각 step을 진행하기 위해서 아래와 같은 비교 클래스를 만들었습니다.
@Slf4j
@Getter
@NoArgsConstructor
public class HistoryCollectionDto {
private Map<String, BaeDalHistory> baeDalHistories = new HashMap<>();
private List<BaeminHistory> baeminHistories = new ArrayList<>();
...
//비교작업을 수행
public List<CompareResult> compareHistories() {
return baeminHistories.stream()
.filter(this::matchHistroies)
.map(this::convertResult)
.collect(Collectors.toList());
}
private boolean matchHistroies(BaeminHistory baeminHistory) {
BaeDalHistory history = baeDalHistories.get(baeminHistory.getOrderNumber());
OrderStatus status = baeminHistory.getOrderStatus();
return history == null || history.isNotEqualStatus(status);
}
private CompareResult convertResult(BaeminHistory baeminHistory) {
if (!baeDalHistories.containsKey(baeminHistory.getOrderNumber())) {
return baeminHistory.toOmissionResult(); // 누락데이터 결과로 변환
}
return baeminHistory.toDifferentResult(); //상태 다름 결과로 변환
}
}
- 두 데이터를 컬렉션으로 띄우고 배민의 데이터를 기준으로 비교를 진행합니다. 상태가 다르거나 누락이 있는 데이터는 비교 결과 리스트로 변환하여 반환합니다.
사실 처음에는 메모리에 올리는 것이 혹여 문제가 될까하여 쿼리로 모든 비교 조건을 담아 구현하였었는데,
뒤로 갈수록 쿼리가 너무 복잡해져 메모리에 올려 CollectionDto에서 비교하는 방향으로 바꿨습니다.
쿼리가 아닌 코드로 비교 로직을 구현하니 개발 초기에는 생각지 못했던 조건들이 추가 되었을때 쉽게 확장을 할 수 있었고,
유지보수도 쉽다는 장점이 생겨났습니다.
3주차) 파일관리
이번 프로젝트를 구현하면서 서버를 두 개로 나누어 배포 하였습니다.
하나는 파일을 업로드하고 결과 파일을 다운로드 할 수 있는 API서버, 또 다른 하나는 비교작업을 진행할 배치서버입니다.
개발을 진행할 때는 로컬에서 진행하다 보니 두 서버간 파일 공유의 문제가 없었는데, 막상 배포를 하려하니 각각의 서버에서 파일을 공유하지 못하는 문제가 발생했습니다.
저는 이런 문제를 해결하기 위해 S3를 활용하여 파일을 공유할 수 있는 환경을 만들었습니다.
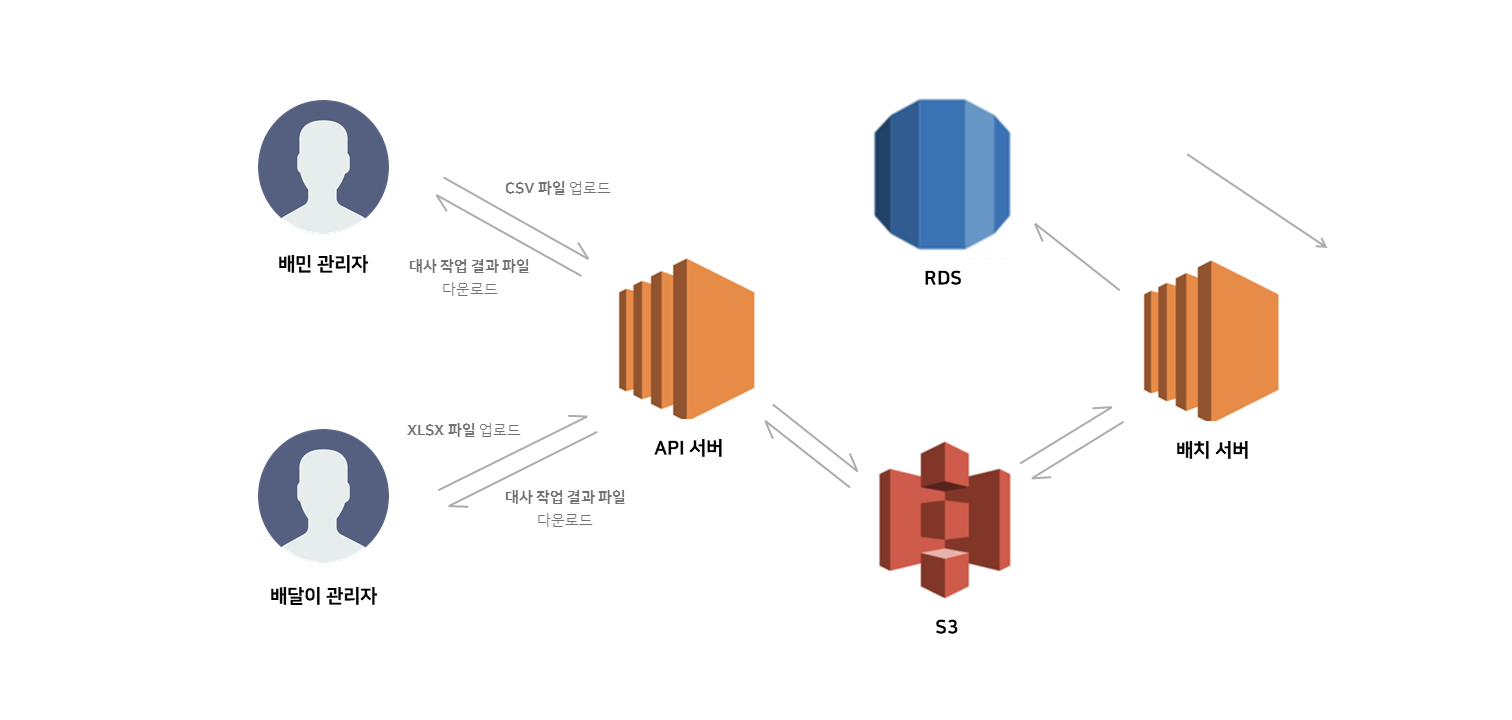
- Gradle Multi Module을 활용하여 각각의 서버를 모듈별로 관리하였습니다.
- 배포는 Beanstalk을 활용하여 모듈별로 진행하였습니다.
각각의 관리자가 api서버에 파일을 업로드하면 해당 파일을 s3에 저장합니다.
그 후 배치가 돌아갈 때 해당 날짜에 맞는 파일을 s3에서 다운받아 비교작업을 진행 후 결과파일을 만들어냅니다.
그리고 마지막으로 다시 s3에 결과 파일을 업로드 하도록 구성하였습니다.
사실 이렇게 S3를 사용하고 나니 한가지 문제가 발생했는데, 그 문제는 로컬환경과 테스트환경에서 같은 저장소를 사용하여야 한다는 것이었습니다.
이번 파일럿 프로젝트는 혼자 하는 프로젝트여서 문제가 없었지만 만약 협업상황이었다면 많은 불편함이 생길 것입니다.
(리뷰 단계에서 개선 결과를 소개합니다.)
4주차) 코드 리뷰
4주차에는 프로젝트에 대한 리뷰를 받는 시간을 가졌습니다.
나름 비교 결과가 제대로 맞아 안심하고 있었는데.. 결과만 잘 나온다고 끝이 아니였습니다.
“왜 이런식으로 구현하였나요?”,“이건 왜 사용했나요?”,“테스트 코드는 왜 객체지향적이지 못한가요?”등 다양한 피드백이 나왔습니다. 그 중 기억에 남는 몇가지를 소개합니다.
RunIdcrementer를 왜 쓰나요?
@Bean
public Job saveOrderHistoryJob() throws Exception {
return jobBuilderFactory.get(JOB_NAME)
.incrementer(new RunIdIncrementer()) // <-- 이건 왜쓰나요??
.start(saveBaeDalDataStep())
.next(saveBaeminApprovalDataStep())
.next(saveBaeminCancelDataStep())
.build();
}
“jobParameter가 같아서 저거 안넣으면 안돌아 가던데요..”
Job은 JobKey가 같으면 실행이 되지 않습니다. JobKey는 Job과 Job Parameter로 만들어집니다.
그래서 항상 다른 JobParameter를 주어야 실행되는데요, 저는 이러한 문제를 해결하려고 RunIdIncrementer를 사용하였습니다.
incrementer에 RunIdIncrementer객체를 넣어 build하게 되면 RunIdIncrementer의 특정 파라미터(run.id) 값을 계속 증가시켜 Job을 실행하기 원할 때 항상 실행할 수 있게 됩니다.
한편 같은 파라미터로는 Job이 실행되지 않는다는 것은 Spring Batch의 장점 중 하나입니다.
예를 들어 집계함수를 실행한 이후 이를 모르는 누군가가 다시 집계함수를 실행하려고 해도, 이 장점 덕에 Job이 실행되지 않아 집계 데이터가 덮어써지는 것을 방지할 수 있습니다.
저는 이런 장점을 완전히 무시하고 있었습니다. 팀원분들의 조언을 통해 Spring Batch를 썼을 때의 이점들에 대해 다시한번 생각해 볼 수 있었습니다.
jobParameters = new JobParametersBuilder()
.addString("startTxDate", "2019-12")
.addString("nextTxDate", "2019-01-01")
.addLong("time", System.currentTimeMillis())
.toJobParameters();
JobExecution jobExecution = jobLauncherTestUtils.launchJob(jobParameters);
- 테스트 코드를 수행할때는 현재 시간을 파라미터에 추가하여 수행할 수 있도록 합니다.
s3의 분리!
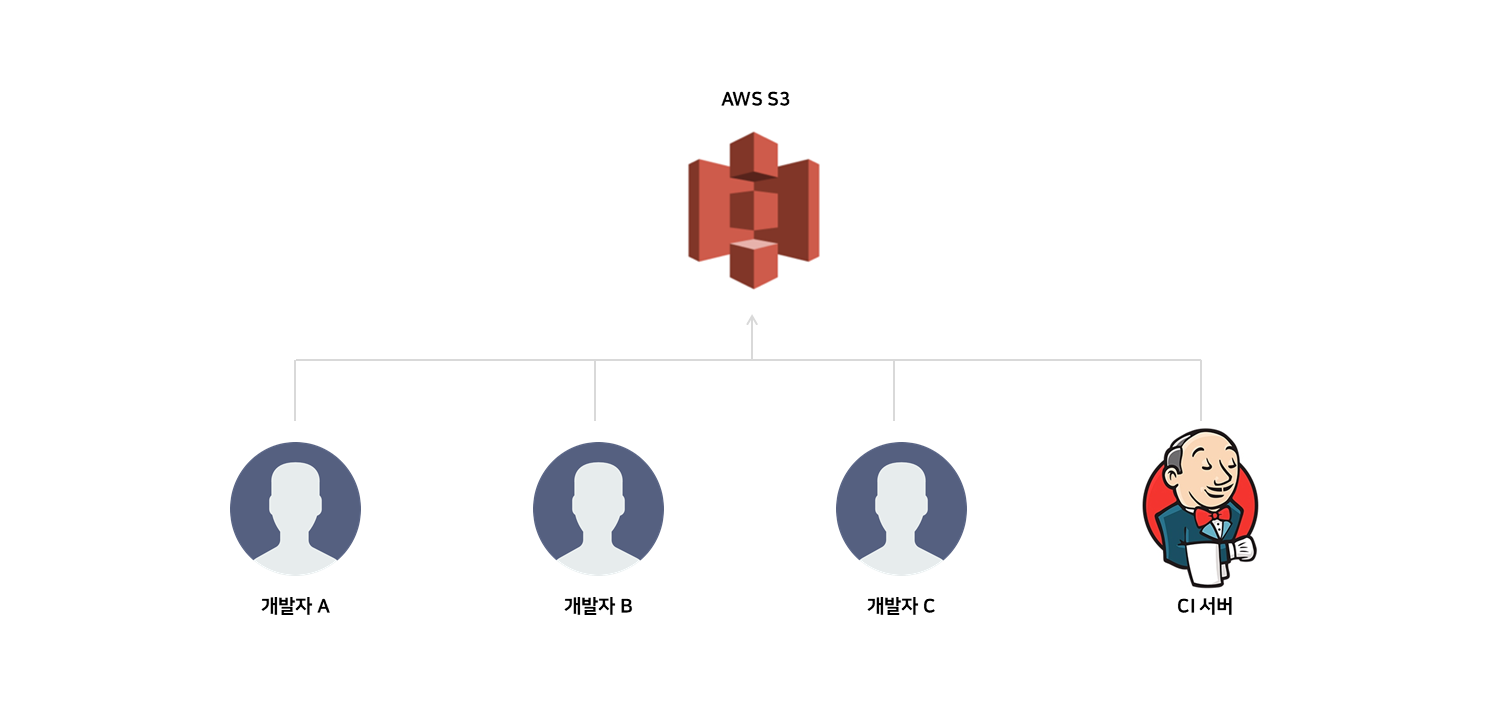
위에서 말씀드린 S3 구성 문제에 대해서도 지적받았습니다.
저는 로컬환경과 테스트 환경에서도 S3를 사용하였는데, 이렇게 될 경우 프로젝트에 참여하는 모든 사람들이 같은 저장소를 쓴다는 문제가 발생합니다.
협업하는 모든 개발자가 같은 저장소를 사용하면 개발 중 동시에 같은 파일을 올려 충돌이 발생할 수 있고 잘못된 결과를 받을 수도 있기 때문입니다.
어떤식으로 해야 격리할 수 있을까 고민하던 중 해결책으로 S3Mock을 찾았습니다.
S3Mock은 로컬환경에 가상의 파일 서버를 생성해 실제 S3 bucket처럼 사용할 수 있도록 하는데요,
- 먼저 S3Mock서버를 통해 생성된 가상 환경에 미리 설정해 놓은 값들을 넣어 실행합니다.
- 로컬환경과 테스트환경에서는 AmazonS3Client가 S3Mock서버를 바라보도록 설정합니다.
- Bean으로 생성하여 프로젝트에 참여하는 모든 개발자들이 독립적인 파일 저장소를 가질 수 있도록 합니다.
@Slf4j
@Configuration
@Profile({"local","test"})
@RequiredArgsConstructor
public class MockS3FileConfiguration {
private final S3MockResource S3MockResource;
@Bean("s3Mock")
public S3Mock s3MockApi() {
S3Mock s3Mock = new S3Mock.Builder().withPort(...);
s3Mock.start();
return s3Mock;
}
@Bean
@DependsOn(value = {"s3Mock"})
public AmazonS3Client amazonS3Client() {
AwsClientBuilder.EndpointConfiguration endpoint =
new AwsClientBuilder.EndpointConfiguration(S3MockResource.getUrl(),
S3MockResource.getKey());
AmazonS3Client client = (AmazonS3Client) AmazonS3ClientBuilder.
...
.withEndpointConfiguration(endpoint)
.build();
putInitS3Object(client);
return client;
}
private void putInitS3Object(AmazonS3Client client) {
client.createBucket(S3MockResource.getBucket());
client.putObject(S3MockResource.getBucket(), "baemin_2019-01.csv",..);
......
}
}
이렇게 사용하니까 clone하여 배치를 실행할 때 다른 설정을 할 필요가 없게 되었고, 각자 독립적인 테스트 환경을 갖추게 되어 개발에 집중할 수 있었습니다.
마치며..
파일럿 프로젝트를 처음 시작했을 때 시도해보지도 않고 고민만 하다 많은 시간을 허비했습니다.
팀장님께서 그런 제 모습을 보시고 하신 말씀! “일단 해보세요” !!
해보지도 않고 지레 안될거라 겁을 먹었던 제 자신이 정말 부끄러웠습니다.
팀원분들 중 한 분이 신입 개발자가 가장 많이 성장할 수 있는 시간 중 하나는 삽질할 때라고 말씀해주셨는데요, 이제는 정말 우아한 형제들에서 몸으로 열심히 배워나가야 할 때인거 같습니다!.
마지막으로 이 글이 저처럼 배치를 처음 접하는 분들에게 도움이 되었으면 좋겠습니다…. 끄읏!