Aurora MySQL를 운영하면서 알면 좋을 것 같은 미세한 팁
들어가며
안녕하세요. 우아한형제들에서 DBA로 근무하고 있는 유영근입니다.
저희는 AWS환경에서 RDS로 수많은 요청을 처리하고 저장하며 Aurora MySQL을 주력으로 사용하고 있습니다.
한정된 사람구하기 힘든 DBA로 수많은 DBMS를 효율적으로 운영하고 있으며 입사 이후 DB를 운영하면서 겪었던 몇가지 사례를 공유하고자 글을 쓰게 되었습니다.
Aurora MySQL 데이터베이스의 특성을 이해하기
Aurora는 MySQL을 기반으로 개발되었지만 RDS MySQL 이나 On-Premise 환경에서와는 달리 운영을 하면서 기존 MySQL과 달리 주의해야하는 부분도 많이 있습니다. 여기서는 운영을 하면서 배웠던 몇가지 사례만 공유하고자 글을 쓰게 되었습니다.
- CacheWarming
- binlog 사용하기
첫번째 미세한 팁. Aurora CacheWarming을 알아봅니다.
운영을 하면서 DB의 워크로드에 맞춰서 DB 인스턴스의 사양을 조절하며 트래픽에 대응할 수 있는것이 클라우드의 장점입니다.
DB 또한 대규모 이벤트 대응을 할때는 Scale-Up과 Scale-Out을 빠른 시간에 진행하고, 이벤트가 종료되면 평소 트래픽 사양으로 변경할 수 있습니다.
또한 Aurora는 Cache Warming 기능을 강조하고 있습니다.
Aurora 페이지 캐시는 데이터베이스가 아닌 별도의 프로세스로 관리되기 때문에 데이터베이스와 상관없이 유지됩니다. 예상과 달리 데이터베이스에 결함이 발생하더라도 페이지 캐시가 메모리에 남아있기 때문에 데이터베이스를 재시작할 때 버퍼 풀이 가장 최신 상태로 워밍됩니다.
하지만 저희도 이 기능만을 믿고 테스트를 하지 않은 채 한 서비스에서 사용되는 DB 인스턴스 사양을 변경한 적이 있었고 사양을 높였음에도 버퍼 캐시가 비워져 Select Latency 가 증가하고 Buffer Cache Hit Ratio가 떨어지는 현상이 있었습니다.
시간이 지나면서 데이터가 메모리에 적재되면서 해소되었으나 굉장히 바쁜 DB였다면 전체적인 서비스의 응답시간이 떨어져 장애로 이어질 수 있는 상황이었습니다.
Aurora 인스턴스를 관리하면서 운영중에 불가피한 Failover 상황 뿐 아니라 인스턴스의 사양 변경, Reader 인스턴스의 추가 등 다양한 작업을 무중단으로 진행해야하는데 그래서 어떤 상황일 때 Cache Warming 이 동작하지 않는지 정확하게 확인하기 위하여 테스트를 진행하였습니다.
MySQL 의 Cache Warming
Cache Warming 이 Aurora에만 있는 신기능은 아닙니다. MySQL 에도 5.6버전 부터 warmup을 피하기 위해 InnoDB의 버퍼 풀에 있는 디스크 페이지를 파일로 dump 한 후
MySQL 이 재시작 될 때 dump 된 파일을 다시 버퍼 캐시로 올려서 버퍼 풀의 상태를 계속해서 유지할 수 있습니다.
또한 MySQL 은 수동으로 버퍼 풀을 dump 하고 운영중에 Load 하는 것도 가능합니다.
따라서 배치와 같은 대량의 DB 데이터 변경 작업을 진행하기 전 기존 버퍼풀의 데이터가 밀려나는 것을 방지하기 위해 dump를 하여 운영중의 버퍼 상태를 저장하고, 작업이 끝나면 다시 Load하는 등 상황에 따라 유연하게 대처가 가능합니다.
MySQL 버퍼 풀 Dump
SET GLOBAL innodb_buffer_pool_dump_now=ON;
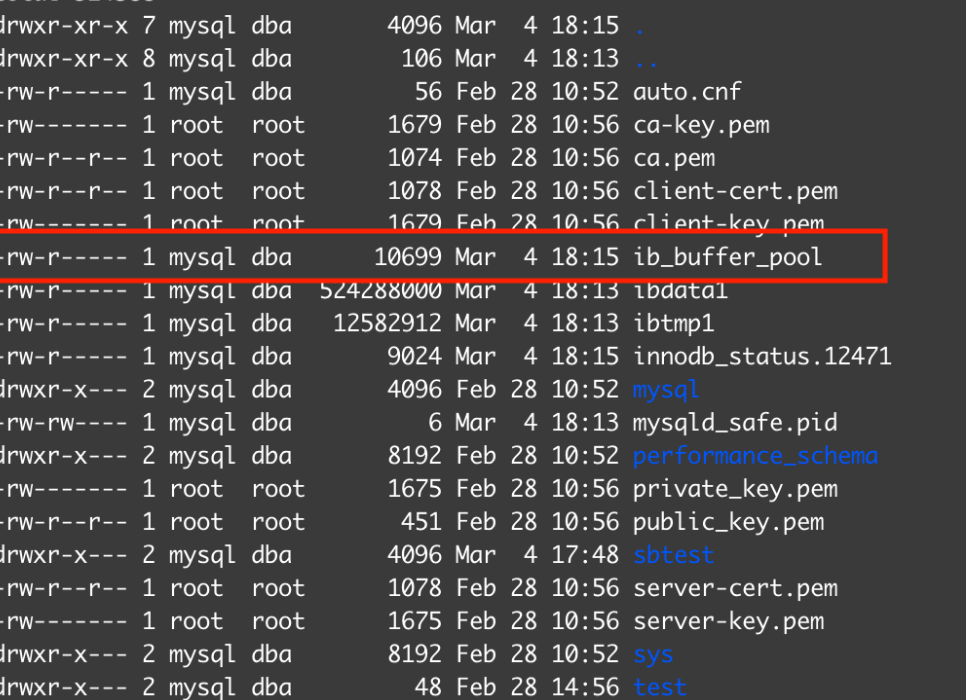 MySQL 5.7에서 버퍼 캐시 Dump 시 다음과 같이 버퍼내의 데이터 페이지를 파일로 저장합니다.
MySQL 5.7에서 버퍼 캐시 Dump 시 다음과 같이 버퍼내의 데이터 페이지를 파일로 저장합니다.
Dump 된 파일을 버퍼 풀로 Load
SET GLOBAL innodb_buffer_pool_load_now=ON;
mysql> show status like 'innodb_buffer_pool_load_status';
+--------------------------------+--------------------------------------------------+
| Variable_name | Value |
+--------------------------------+--------------------------------------------------+
| Innodb_buffer_pool_load_status | Buffer pool(s) load completed at 190305 9:17:59 |
+--------------------------------+--------------------------------------------------+
1 row in set (0.00 sec)
MySQL RDS의 버퍼 캐시 dump
MySQL RDS에서도 해당 기능을 지원하며 직접적으로 파일시스템에 접근할 권한이 없기 때문에 다음의 저장 프로시저 명령어로 버퍼 캐시를 디스크로 내릴 수 있습니다.
mysql> CALL mysql.rds_innodb_buffer_pool_dump_now();
mysql> CALL mysql.rds_innodb_buffer_pool_load_now();
Aurora 의 Cache Warming
그럼 Aurora MySQL은 어떨까요? Aurora 도 MySQL 을 기반으로 만든거라 Cache Warming 이 동작하지만 기존의 MySQL 에서 사용하던 버퍼 풀 덤프 관련 파라미터 그룹을 따로 설정할 수 없고 master 권한으로도 수동으로 덤프와 복원도 불가능합니다.
Aurora 의 DB 아키텍처 구조 상 Cache Layer 가 SQL 엔진과 완전히 분리되어 warm up 을 생략할 수 있다고 설명하고 있습니다.
Cache warming across db restarts: Aurora follows a service-oriented architecture, due to which the Aurora’s cache survives a database restart or shutdown. It helps the database to resume fully loaded operations faster than others with no ‘warm up’ required.
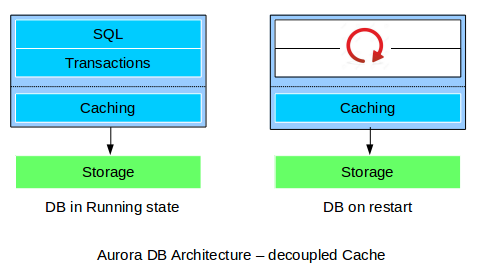
하지만 특정 케이스에서는 인스턴스 재시작 후 warm up을 피할 수 없었고 이 상황에 대한 정확한 문서가 없었습니다.
따라서 눈물을 머금고 테스트를 통해 Cache Warming 이 언제 발생하는지 확인해보았습니다.
먼저 주로 발생하는 재시작 상황을 재현을 하고 같은 쿼리를 날려서 Disk에서 읽었는지 버퍼에서 읽었는지를 체크하였습니다.
정확한 테스트를 위해 Query Cache는 비활성화 하고 테스트를 진행하였습니다.
다음의 case에 대해 Aurora Cache Warming 이 동작하는지 테스트
- Writer 재시작
- Reader 재시작
- Reader 인스턴스 추가
- Failover 시
- 인스턴스 스펙 변경 시
- 스냅샷 복원 시
테스트 결과
| case | Cache Warming(Writer) | Cache Warming(Reader) |
|---|---|---|
| Writer 재시작 | O | X |
| Reader 재시작 | O | O |
| Reader 추가 | O | X |
| Failover | O (리더의 캐시를 들고 감) | X |
| 인스턴스 스펙 변경 | X | X |
| 스냅샷 복원 | X | X |
테스트로부터 배운 것 :
- Writer가 재시작 되면 Reader의 연결도 끊어지고 Reader의 캐시도 비워집니다.
- Failover 발생 시 기존 Reader 인스턴스가 Writer로 승격이 되어도 Reader의 캐시를 들고갑니다. 기존 Writer 의 캐시는 비워집니다.
- Reader 인스턴스를 추가하는 경우 신규 Reader는 Cache Warming 이 되지 않는 것을 알 수 있었습니다.
- Reader 인스턴스를 추가 시 최초 실행되는 쿼리들은 Select Latency 가 기존보다 높을 수 있습니다.
Writer의 Cache가 비워지는 작업은 무중단 서비스라도 바쁜 시간대를 피해서 진행하는 것이 좋으며 필요하다면 자주쓰는 테이블이라도 수동으로 COUNT(*) 등의 쿼리를 통해 Cache Warming 작업을 하면 도움이 됩니다.
두번째 미세한 팁. Aurora 에서 binlog 사용하기
MySQL을 사용하면서 빠질 수 없는 것이 binlog 일 것입니다. binlog로 복제구성은 물론 binlog 파싱을 통한 데이터 스트리밍 등 여러가지로 활용방안이 무궁무진 한데요. binlog를 활용의 최정점 끝판왕도 구경해봅니다.
MySQL Aurora는 복제에 binlog - relaylog 방식을 사용하지 않는다는 것은 다 알고 계실 것입니다. Aurora와 MySQL을 구분하는 가장 큰 장점으로 내세우고 있죠.
하지만 Aurora를 쓰면서도 binlog를 사용해야하는 경우가 있다는 것입니다. 우아한형제들에서 관리하는 RDS들도 기본적으로 다음과 같은 이유로 binlog를 켜서 남기고 있는데요.
- 특정 쿼리가 실행된 시간을 찾을 때
- 외부 복제 구축용
특정 쿼리가 실행된 시간을 찾을 때는 잘못된 쿼리가 실행되어 데이터 복원 시점을 찾아야하는 등 용도로 사용하고 있으며, 외부 복제 세트를 구축해야 하는 용도로도 사용하고 있습니다.
Aurora MySQL의 Reader가 복제본인데 왜 외부 복제 (External Replication)를 사용하나요?
서로 다른 Aurora MySQL 클러스터간 복제를 하는 경우에는 전통적인 binlog 방식으로 복제 환경을 구성해야 하는데요.
주로 다음과 같은 경우에 사용하고 있습니다.
- 서로 다른 계정에서 Aurora 클러스터간 데이터 동기화가 필요한 경우
- RDS MySQL , Maria DB 를 사용중인 환경에서 무중단으로 Aurora로 DBMS 마이그레이션을 진행하는 경우
- Aurora MySQL 5.6 에서 5.7 버전으로 무중단 Upgrade를 해야하는 경우
등등등… 피치 못할 사정으로 binlog 복제를 사용하게 됩니다.
AWS 메뉴얼에서도 해당 사항을 가이드하고 있습니다.
binlog를 이용한 외부 복제를 하는 작업은 매우 간단합니다.
기존 Onpremise 환경에서 MySQL을 운영해보셨다면 xtrabackup을 이용하여 slave를 구성하셨을 텐데, AWS환경에서는 스냅샷을 이용하여 복제를 만들 수 있습니다.
작업순서는 대략 다음과 같습니다.
먼저 사전 작업으로 원본 클러스터 파라미터 그룹에 binlog가 활성화 되어있는지 확인합니다.
mysql> show global variables like 'log_bin';
+---------------+-------+
| Variable_name | Value |
+---------------+-------+
| log_bin | ON |
+---------------+-------+
1 row in set (0.01 sec)
복제본에서 사용할 파라미터 그룹도 원본RDS와 동일하게 생성해두는것이 좋습니다.
binlog가 꺼져있으면 클러스터 파라미터 그룹에 binlog_format 값을 수정합니다. 해당 작업은 DB재시작이 필요합니다.
- 원본 RDS 측에서 복제용 환경 작업
-- binlog retention 설정 (3일)
mysql> CALL mysql.rds_set_configuration('binlog retention hours', 72);
-- 복제용 임시 계정 생성
mysql> CREATE USER 'repl'@'%' IDENTIFIED BY '비밀번호';
mysql> GRANT REPLICATION CLIENT, REPLICATION SLAVE ON *.* TO 'repl'@'%';
-
원본 RDS 스냅샷 생성
-
원본 스냅샷을 복원하여 새로운 클러스터 생성
-
복원한 스냅샷의 복구 지점 확인 Writer 의 Recent Event 에서 확인가능 (Binlog position from crash recovery is mysql-bin-changelog.001102 70375984)
-
복원한 RDS 측(Slave) 에서 다음 명령을 실행하여 복제 구성
-- master 정보 등록 (기존 change master to 구문 대체 )
mysql> CALL mysql.rds_set_external_master ('원본의writer endpoint', PORT, 'repl', 'password', 'mysql-bin-changelog.001102', 70375984, 0);
-- 복제 시작
mysql> CALL mysql.rds_start_replication;
복원 시 parameter group 은 원본과 동일하게 설정합니다.
Aurora와 binlog 그 불편한 관계
하지만 Aurora에서 binlog 를 사용하는 경우 Master 쪽에 부하가 가게 되는데요. 테스트를 한 결과를 공유해봅니다.
우선 단순히 binlog 만을 남겼을 때의 성능 변화 지표입니다. 테스트를 위해 query cache는 OFF 하고 테스트를 진행하였습니다.
- sysbench tpcc 스크립트 사용하여 thread 당 300초간 부하 테스트 진행
- data size 100GB
- r5.xlarge
- Aurora MySql 2.04.6 에서 진행
binlog OFF
| thread수 | 4 | 8 | 16 | 32 | 64 | 128 |
|---|---|---|---|---|---|---|
| qps | 6118.63 | 9369.51 | 14324.24 | 21227.08 | 23783.92 | 23216.17 |
| latency | 18.58 | 24.33 | 31.6 | 42.81 | 76.35 | 156.23 |
binlog ON (Type: Rows / GTID_mode = off)
| thread수 | 4 | 8 | 16 | 32 | 64 | 128 |
|---|---|---|---|---|---|---|
| qps | 5975.40 | 9145.84 | 13903.45 | 20353.92 | 22113.67 | 21440.05 |
| latency | 18.87 | 24.88 | 32.77 | 44.7 | 82.32 | 170 |
단순히 binlog 만을 남기는 경우에는 성능 저하는 크지 않습니다.
그럼 다음은 외부 복제를 이용하여 slave를 붙인 상태에서의 지표입니다.
복제 구성 Aurora-Aurora
| threads수 | 4 | 8 | 16 | 32 | 64 | 128 |
|---|---|---|---|---|---|---|
| qps | 5220.48 | 7050.15 | 9367.37 | 11423.06 | 13959.42 | 16112.59 |
| latency | 21.74 | 32.4 | 48.52 | 79.64 | 130.12 | 225.83 |
테스트 결과
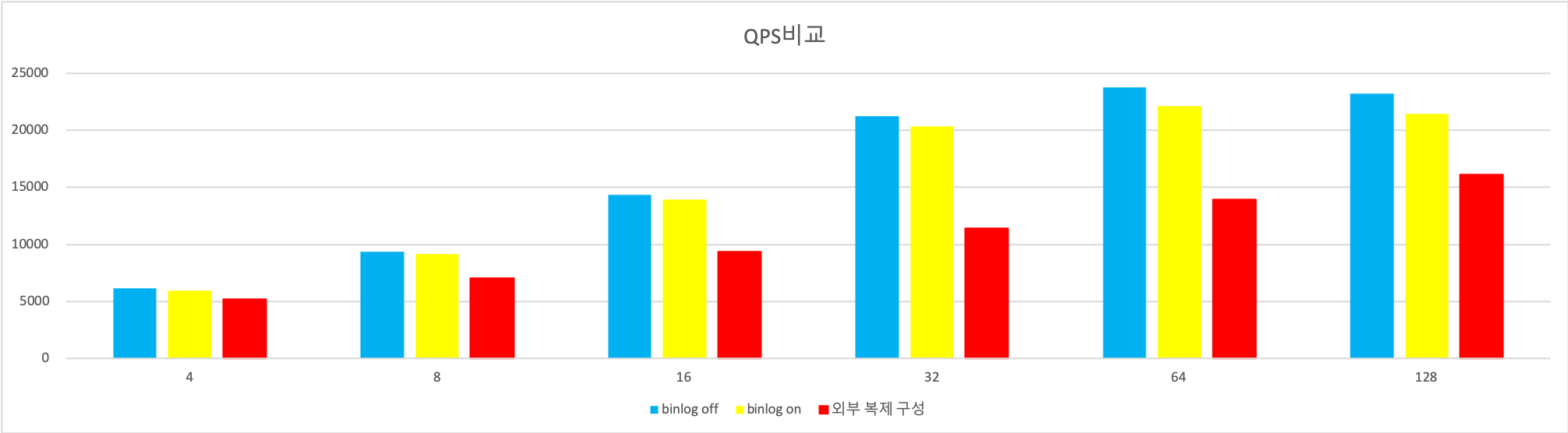
Aurora MySQL에 binlog를 이용한 복제를 걸었을때 Master Aurora의 성능하락이 눈에 띄게 발생을 합니다. 특히 특정 구간에서는 QPS가 절반가까이 떨어지는 것도 확인 할 수 있었습니다.
테스트로부터 배운 것 :
- binlog와 Aurora는 궁합이 그렇게 좋지는 않습니다.
- 그래도 써야할 때는 master의 부하량을 테스트 등으로 산정하고 QPS가 떨어지는 것을 고려하여 인스턴스 스펙을 결정합니다.
- 추가) 이 테스트는 Aurora Version 2.04.6에서 진행하였으며 최근 Aurora Version에서 조금씩 binlog관련 성능 개선이 이루어지고 있는 것 같습니다.
그래도 Aurora에서 binlog를 뛰어넘는 뭔가 나와줘야 할 것 같습니다.
마치며
이제는 클라우드 환경에서 DB를 운영하는 것이 어색하지 않을 정도로 많은 회사에서 사용하고 있습니다.
기존 DBA의 역할도 조금씩 변화하는 것이 느껴집니다.
하지만 회사의 소중한 데이터를 보호하는 DBA로써 항상 지켜야 할 것은 눈으로 직접 확인해 본 결과를 신뢰하고, 많은 테스트를 진행해봐야 한다는 점은
변하지 않을 것 같습니다.
내년 초부터 수많은 AWS-RDS의 인증서 교체 작업이 예정되어 있네요 (눈물) 저희와 함께 하실 DBA분이 계신다면 언제든지 환영합니다!
이만 물러가겠습니다.