간단하게 만드는 이상한 알람
• 이재웅

안녕하세요. 우아한형제들에서 DBA로 근무하고 있는 이재웅입니다.
오늘은 간단한 이상점 탐지를 이야기 하려고 합니다.
장애 사례를 한가지 들어볼께요.
오전 8시 서버 배포 이후 DB의 CPU 사용률이 전일 대비 10% 정도 높아졌습니다.
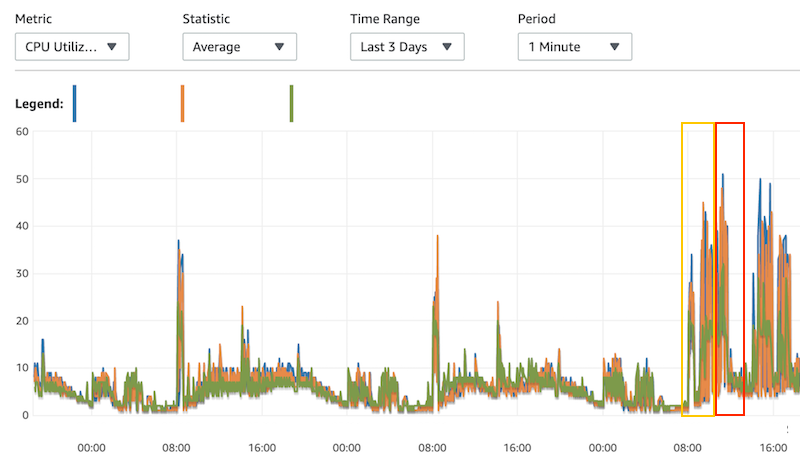
그래서 특이점을 인지 못했고 서비스에도 영향은 없었습니다.
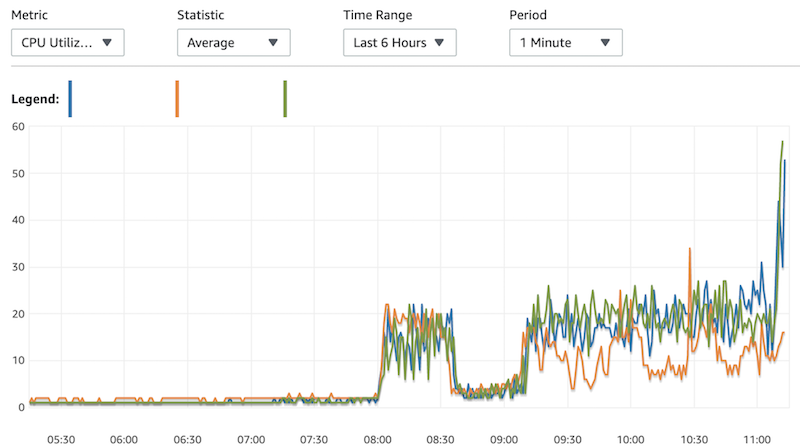
이렇게 3시간쯤 계속 평소보다 약간 높은 부하를 유지하다 점심 피크 때 몰린 트래픽으로 인해 순식간에 DB 부하가 심해져 장애가 발생하였습니다.
이런 경우 CPU 사용률 50%, 70% 임계치 알람이 설정되어 있었지만 급격히 늘어나는 트래픽에 알람 인지 후 조치할 시간이 충분하지 못했습니다.
또한 부하 원인이 SlowQuery 인 경우 튜닝한 쿼리를 배포하여 조치하는 경우 배포 작업으로 시간이 소요됩니다.
배포 이후 DB 리소스 사용량의 이상점을 조기에 감지하여 경고 알람이라도 받을 수 있다면 여러 유관부서들이 장애 징후를 인지하고 사전 조치 또는 장애 대응 시 원인 파악 및 해결이 빠를 수 있습니다.
이상점 감지는 간단합니다.
게임을 비롯한 인터넷 서비스들은 보통 리소스 사용량에 패턴을 가지고 있습니다.
이러한 패턴은 주로 내부적인 시스템 요인에 의해서 달라질 수 있는데 외부 요인에 대한 이상점도 관심을 가져야 됩니다.
DB 앞단의 다른 시스템 장애로 인해 DB로 트래픽이 오지 못할 경우 DB 리소스 사용량은 평소보다 낮을 것입니다.
국가대표 경기가 있다면 배달 주문은 늘어날 것이고 DB 리소스 사용량이 평소보단 조금 상승할 것입니다. 미리 설정해둔 임계치 알람에 도달하지 않더라도요.
이러한 이상 징후를 알고 싶은겁니다.
AWS Cloudwatch 에는 Anomaly Detection 기능이 있습니다.
저희도 기능이 출시하자마자 여러 메트릭에 사용하였습니다만 유효하게 사용된 케이스보다 오탐이 발생하는 케이스가 더 많았습니다.
다만 이러한 오탐이 발생할 경우 조정이 필요한데 Anomaly Detection 은 이러한 조정 장치가 아쉬웠습니다. (특정 날짜를 학습에 제외하는 기능만 제공)



간단하게 통계를 이용하여 이상점를 확인하도록 만들어보겠습니다.
현재 시간대의 CPU 사용률과 전일 같은 시간대의 CPU 사용률을 비교합니다.
두 집단의 평균을 비교하여 이상점를 판단합니다.
두 집단을 비교하는건 독립된 집단이냐, 동일 집단의 전/후를 비교하느냐에 따라 다릅니다.
독립된 집단의 경우 각 집단의 평균을 구한 뒤 비교하고,
동일 집단의 전/후, 즉 대응집단(Paired)은 집단 내 동일 그룹간 차이를 평균으로 구해 비교합니다.
오늘과 전일 같은 시간대의 경우 동일 그룹의 전/후로 볼 수도 있습니다.
쉽게 A반과 B반의 중간고사 성적을 비교하거나, 동일 소비자들에게 광고를 보여주기 전/후의 구매 건 수 차이를 비교합니다.
이 경우 두 집단은 완전히 독립된 집단이 아니라고 가정하고 대응표본t검정으로 비교합니다. (시간별로 동일그룹으로 판단)
우선 가설을 정의합니다.
귀무가설(h0) : 두 집단간 유의한 차이가 없다.
대립가설(h1) : 두 집단간 유의한 차이가 있다.
검정은 R이나 SPSS 등 통계툴을 사용하셔도 되고 python, nodejs 등으로 하셔도 됩니다만 배치로 계속 실행할 경우 python이 편합니다.
우선 excel 도 가능하니 excel 에서 먼저 해볼께요.
excel 에서 데이터 분석을 하려면 [개발도구->Excel 추가 기능->분석 기능 체크 -» 데이터->데이터 분석] 순서로 진행하시면 데이터 분석 기능을 사용할 수 있습니다.
동일한 시간대 A/B 두 집단의 CPU 사용률 데이터가 있습니다.
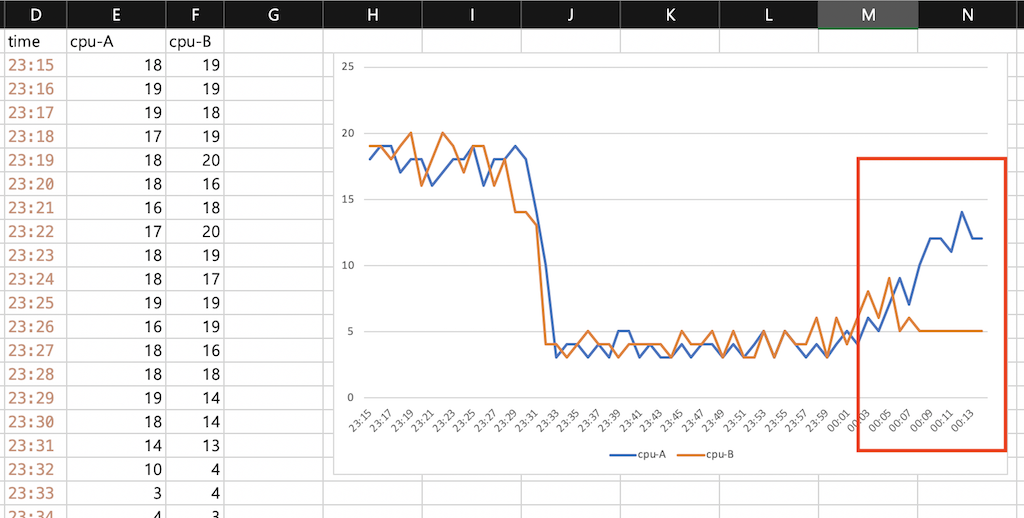
그래프를 보시면 00:10 이후부터 두 집단 간 갭이 생깁니다.
대응집단 t검정을 한 결과입니다.
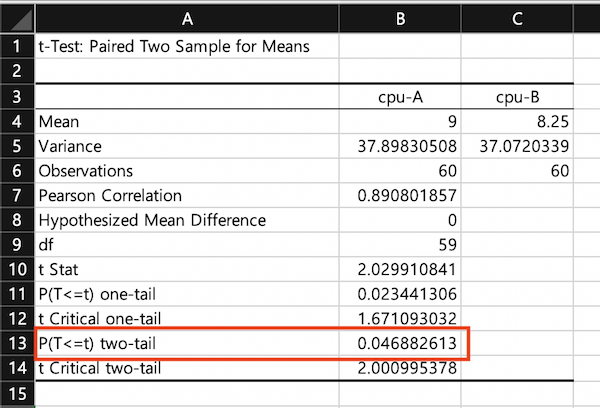
단순히 평균만 봐서는 큰 차이가 없는거 같지만 유의확률은 0.046으로 95% 신뢰구간을 벗어나므로 두 집단 간 차이가 있다 라고 볼 수 있습니다.
또한 동일한 테스트를 python 의 scipy 모듈을 이용하면 간단하게 통계 결과를 확인할 수 있습니다.
from scipy import stats
a = [ 12.0,12.0,14.0,11.0,12.0,12.0,10.0,7.0,9.0,7.0,5.0,6.0,4.0,5.0,4.0,3.0,4.0,3.0,4.0,5.0,3.0,5.0,4.0,3.0,4.0,3.0,4.0,4.0,3.0,4.0,3.0,3.0,4.0,3.0,5.0,5.0,3.0,4.0,3.0,4.0,4.0,3.0,10.0,14.0,18.0,19.0,18.0,18.0,16.0,19.0,18.0,18.0,17.0,16.0,18.0,18.0,17.0,19.0,19.0,18.0 ]
b = [ 5.0,5.0,5.0,5.0,5.0,5.0,5.0,6.0,5.0,9.0,6.0,8.0,6.0,4.0,6.0,3.0,6.0,4.0,4.0,5.0,3.0,5.0,3.0,3.0,5.0,3.0,5.0,4.0,4.0,5.0,3.0,4.0,4.0,4.0,4.0,3.0,4.0,4.0,5.0,4.0,3.0,4.0,4.0,13.0,14.0,14.0,18.0,16.0,19.0,19.0,17.0,19.0,20.0,18.0,16.0,20.0,19.0,18.0,19.0,19.0 ]<br>
# 집단별 요약
desc_a = stats.describe(a)
desc_b = stats.describe(b)
print("a/b-> 평균: {0:.3}/{1:.3}, 분산: {2:.3}/{3:.3}".format(desc_a.mean, desc_b.mean, desc_a.variance, desc_b.variance))
# 대응표본 t 검정
t = stats.ttest_rel(a,b)
print("t-dep-test p-value: {0:.12f}, {1}".format(t.pvalue, t.statistic))
결과
a/b-> 평균: 9.0/8.25, 분산: 37.9/37.1
t-dep-test p-value: 0.046882612987, 2.0299108413418567
역시나 p-value 가 0.04688로 유의확률 0.05보다 작으므로 귀무가설을 기각하고 대립가설인 두 집단 간 유의한 차이가 있다. 를 채택합니다.
즉, 두 집단 간 평균에 유의한 차이가 있다 라고 판단합니다.
이러한 테스트를 주기적으로 실행하여 전일 또는 전주와 비교하여 트래픽에 변화가 있는지 탐지를 합니다.
이 방법으로 모든 이상점를 찾을 수 있는가? 또는 잘못된 탐지를 하진 않는가 하면 물론 오탐은 발생하고 놓치는 케이스도 있을겁니다.
이러한 통계는 결정이 아닌 참고용으로 사용하는게 좋습니다.
평균과 분산이 극히 낮은 상태에서는 미세한 차이로도 두 집단의 차이가 있다라는 결과가 나올 수 있습니다.
사람이 인지하기엔 아주 작은 수치의 차이라서 무시할 수준이지만 검정에선 다를 수 있습니다.
그래서 가능한 많은 케이스를 테스트하여 실제 알람으로 설정하기에 적합한 모델을 찾는게 좋습니다.
특정 임계치 이하에선 유의확를 기준을 다르게 가져간다던지, 두 집단 간 평균 차이를 5% 이상을 전제로 둘 수도 있습니다.
위 테스트는 아주 간단하게 진행했지만 실제 사용할 때는 보완해야 것들이 많습니다.
여기선 CPU 사용률 만을 사용했지만 다른 변수들을 더 넣어서 일원분산분석이나 회귀분석으로 이상점를 보실 수도 있습니다.
시계열회귀분석 등을 이용해 예측치를 볼 수 있겠지만 보통 장애 시점에선 트랜드가 올라가면서 장애가 난다기보단 약간의 이상점이 발생한 뒤 급격한 트래픽이 장애로 이어져 예측치가 효과가 있을까 하는 생각도 듭니다. 장기적인 트랜드를 보는 용도라면 좋겠지만요.
인프라의 안정성에 대한 신뢰는 목표가 아닌 기본입니다.
매일 왕복 1시간씩 지하철로 출퇴근한다고 가정해봅시다.
신호대기로 5분 지연과 열차고장으로 인한 1시간 지연은 다를거예요. 또한 신호대기 지연은 자주 발생하지만 열차 고장으로 인한 1시간 지연은 드뭅니다.
두 가지 케이스 중 어느 케이스가 고객이 관용하기 쉬울까요? 일년 발생 비율이 극히 미비하다고 가정할 경우에도요.
장애가 나더라도 고객이 느끼기 어렵게 빠르게 조치를 해야 됩니다.
임계치 알람은 잠재된 위험을 알지 못합니다. 49%와 50%는 1% 차이지만 사고의 플래그는 달라집니다
DB에서 이런 이상 트래픽을 감지하기 위해 시도하는건 서비스 대부분의 트래픽은 DB로 오게 되고 저희는 모든 DB를 관리하고 모니터링합니다.
이를 이용하면 특정 서비스의 이상을 DB로부터 알 수 있지 않을까?
정확한 외부 요인을 몰라도 우선 서비스의 불안정을 감지할 수 있을까?
이로 인해 장애를 예방하거나 다가올 장애에 대비할 시간과 정보를 확보하고 해결 시간을 조금이라도 줄일 수 있지 않을까?
라는 의문에서 출발했습니다.