DB분산처리를 위한 sharding
소개
저희는 신사업부문에서 Thiiing(띠잉)서비스를 만들고 있는 송재욱/전병두입니다.
이번에는 두 명이 함께 기술블로그를 작성했습니다. :)
서비스 오픈전에 아름다운 J곡선 그래프를 바라는 마음은 모두 같을 겁니다.
그런 서비스 성장에 있어 중요한 순간에 서버가 바틀넥이 돼서 발목을 잡으면 안되겠죠. 그래서 예측 가능한 서버 확장 방안에 대해서도 사전에 준비를 해놓길 바랐었습니다.
달리는 기차에 바퀴를 갈아끼는 것이 서비스 운영 유지보수라는 얘기가 있죠.
하물며 DB를 유지보수 하는 것은 더욱 조심스럽고 두려운 작업이 아닐 수 없습니다.
그래서 준비한 것이 DB샤딩입니다. 데이터가 급격히 증가하게 되거나 트래픽이 특정 DB로 몰리는 상황을 대비해, 빠르고 유연하고 안전한 DB증설이 필요하기 때문입니다.
이번 글에서는 저희가 구축한 DB샤딩 방식에 대해 공유하겠습니다.
DB sharding
하나의 DB에 데이터가 늘어나면 용량 이슈도 생기고, 느려지는 CRUD는 자연스레 서비스 성능에 영향을 주게 됩니다. 그래서 DB 트래픽을 분산할 목적으로 샤딩을 고려해 볼 수 있습니다.
DB를 분산하면 특정 DB의 장애가 전면장애로 이어지지 않는다는 장점은 보너스입니다.(물론 보통 HA구성으로 페일오버되도록 설계합니다만..)
저희는 모듈러샤딩과 레인지샤딩을 적용했습니다.
아래서 자세히 설명하겠지만, 모듈러샤딩과 레인지샤딩은 장단점이 명확하며 어떨때는 상호배타적인 성격을 갖는다는 생각이 들기도 하는데요.
따라서 DB마다 예측 가능한 데이터 성질에 따라 방식을 선택하는 것이 중요합니다.
요구사항
모듈러샤딩과 레인지샤딩의 공통된 요구사항은 아래와 같습니다.
- 라우팅을 위해 구분할 수 있는 유일한 키값이 있어야 한다.(편의상 아래부터는 PK 또는 샤딩키라고 부릅니다.)
- 올바른 DB를 찾을 수 있도록 라우팅이 돼야 한다.
- 설정으로 쉽게 증설이 가능해야 한다.
Modular sharding
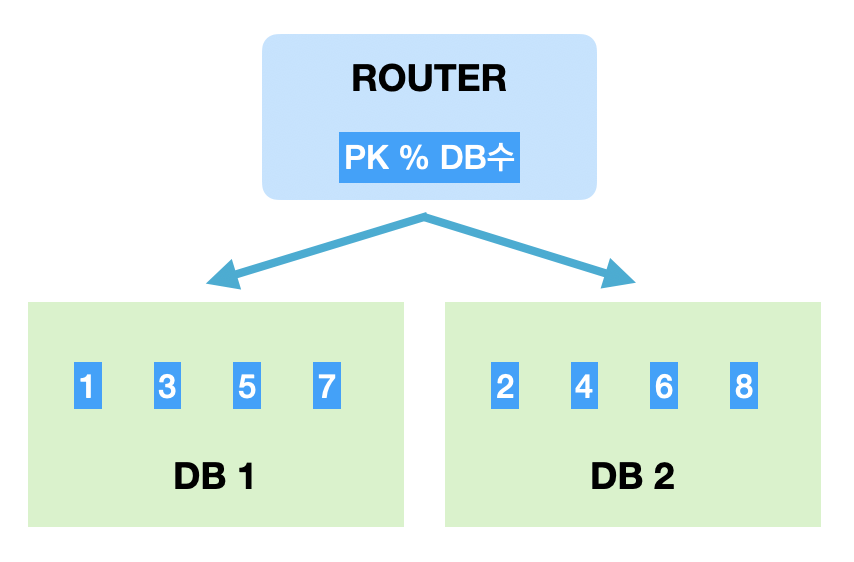 모듈러샤딩은 PK를 모듈러 연산한 결과로 DB를 특정하는 방식입니다. 간략한 장단점은 아래와 같습니다.
모듈러샤딩은 PK를 모듈러 연산한 결과로 DB를 특정하는 방식입니다. 간략한 장단점은 아래와 같습니다.
- 장점 : 레인지샤딩에 비해 데이터가 균일하게 분산됩니다.
- 단점 : DB를 추가 증설하는 과정에서 이미 적재된 데이터의 재정렬이 필요합니다.
모듈러샤딩은 데이터량이 일정 수준에서 유지될 것으로 예상되는 데이터 성격을 가진 곳에 적용할 때 어울리는 방식입니다.
띠잉 서비스의 콘텐츠 관리 정책을 예로 들면, 서비스 오픈 시점에는 콘텐츠의 유지기간이 24시간으로 제한돼 있었습니다.
따라서 데이터가 항상 쌓이기만 하는 상황은 아니었고, 이런 경우 모듈러 샤딩을 적용하기에 알맞습니다. (여담으로 현재는 이 정책이 완화되어 무기한 보존이 가능합니다.)
물론 데이터가 꾸준히 늘어날 수 있는 경우라도 적재속도가 그리 빠르지 않다면 모듈러방식을 통해 분산처리하는 것도 고려해볼 법 합니다.
무엇보다 데이터가 균일하게 분산된다는 점은 트래픽을 안정적으로 소화하면서도 DB리소스를 최대한 활용할 수 있는 방법이기 때문입니다.
Range sharding
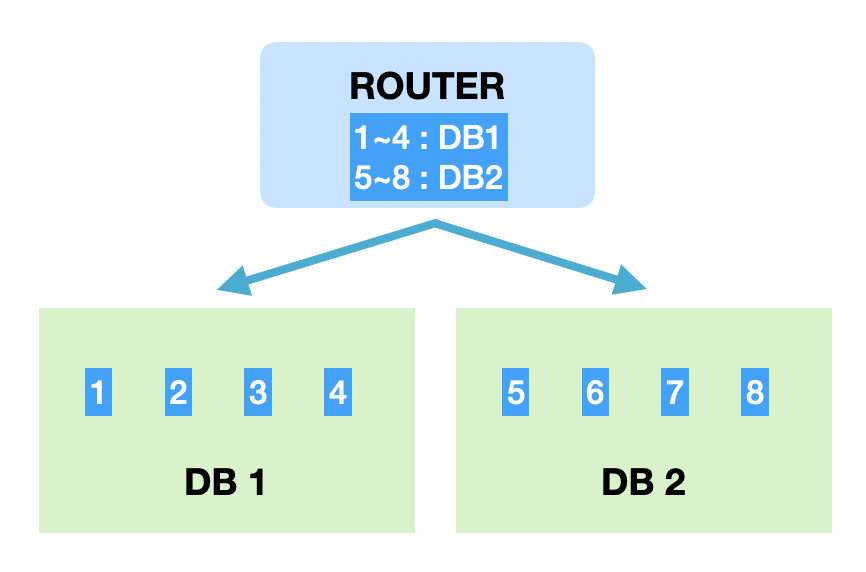 레인지샤딩은 PK의 범위를 기준으로 DB를 특정하는 방식입니다. 간략한 장단점은 아래와 같습니다.
레인지샤딩은 PK의 범위를 기준으로 DB를 특정하는 방식입니다. 간략한 장단점은 아래와 같습니다.
- 장점 : 모듈러샤딩에 비해 기본적으로 증설에 재정렬 비용이 들지 않습니다.
- 단점 : 일부 DB에 데이터가 몰릴 수 있습니다.
레인지샤딩의 가장 큰 장점은 증설작업에 드는 비용이 크지 않다는 점입니다. 데이터가 급격히 증가할 여지가 있다면 레인지방식도 좋은 선택일겁니다. 다만 단점을 무시할 수 없는데요. 주로 활성유저가 몰린 DB로 트래픽이나 데이터량이 몰릴 수 있기 때문입니다. 기껏 분산처리를 했는데 이런 상황이 발생하면 또다시 부하분산을 위해 해당 DB를 쪼개 재정렬하는 작업이 필요하고, 반대로 트래픽이 저조한 DB는 통합작업을 통해 유지비용을 아끼도록 관리해야 합니다.
Router
모듈러와 레인지방식이 어떤 기준으로 데이터를 분산시킬지에 대한 명세를 정의한 것이라면, 실제로 분산된 DB에 접근하기 위한 논리적인 작업은 라우터가 담당하게 됩니다.
구현
앞서 DB샤딩 기본 개념과 요구사항을 살펴봤는데요. 이제부터는 구현에 집중한 내용입니다.
이 글에서는 친구관계를 저장하는 friend DB에 샤딩을 적용한 사례를 예시로 듭니다.
코드는 설명이 용이하도록 일부 수정된 부분이 있어 실제 구현내용과 다소 차이가 있을 수 있습니다.
Sharding Strategy
샤딩 전략은 RANGE, MODULAR 두 가지로 정의합니다.
ShardingStrategy
public enum ShardingStrategy implements IdentityComparable<ShardingStrategy> { // [1]
RANGE, MODULAR
}
[1] IdentityComparable은 enum의 비교연산을 쉽게 하기 위해 띠잉 서버에서 만들어 사용중인 인터페이스입니다.
yaml 설정
운영시 설정정보 변경만으로 쉽게 샤딩을 적용할 수 있도록 yaml을 정의합니다.
데이터소스 설정
datasource: // [1]
friend:
shards: // [2]
- username: ${username}
password: ${password}
master:
name: master-friend
url: ${friend_1_master_url}
slaves: // [3]
- name: slave-friend-1
url: ${friend_1_slave_1_url}
- username: ${username}
password: ${password}
master:
name: master-friend-2
url: ${friend_2_master_url}
slaves:
- name: slave-friend-1
url: ${friend_2_slave_1_url}
...
[1] DB 접속 정보를 가진 데이터소스를 우선 등록합니다.
[2] friend DB의 샤드를 두 개로 나눴습니다. shards 프로퍼티에는 샤딩될 DB마다 HA구성으로 설정합니다.
[3] slave DB는 여러 대 가질 수 있도록 slave-[moduleName]-[index]형태의 이름을 가지며 RoundRobin으로 밸런싱해줍니다.
레인지샤딩 룰 설정
friend DB에 레인지샤딩을 적용한 예시 입니다.
...
sharding: // [1]
friend:
strategy: RANGE // [2]
rules: // [3]
- shard_no: 0
range_min: 0
range_max: 1000
- shard_no: 1
range_min: 1001
range_max: 9223372036854775807
[1] 데이터소스 별 샤딩룰 정의를 시작합니다.
[2] friend DB의 샤딩 전략을 RANGE로 선택했습니다.
[3] 샤딩 전략을 RANGE 로 선택했으므로 샤드 넘버(shard_no)마다 샤딩키의 범위를 지정하게 됩니다.
각 shard_no의 range_max에 1을 더한 값은 다음 shard_no의 range_min이 됩니다. 그래서 마지막 샤딩 설정의 range_max는 샤딩키의 max값으로 설정해 주면 좋습니다.
그러면 증설을 미리 하지 못해서 발생되는 문제를 회피할 수 있고, 증설을 예약하듯 미리 설정하는 것도 가능하게 됩니다.
모듈러샤딩 룰 설정
friend DB에 모듈러샤딩을 적용한 예시 입니다.
...
sharding:
friend:
strategy: MODULAR // [1]
mod: 2 // [2]
[1] friend DB의 샤딩 전략을 MODULAR로 선택했습니다.
[2] 샤딩 전략을 MODULAR 로 선택한 경우는 설정이 간단합니다. 모듈러 연산을 위한 값을 적어주면 되는데, 이 값은 현재 DB 수와 같습니다.
Property
앞서 yaml에서 설정한 정보를 매핑하기 위한 Property 클래스를 정의합니다.
ShardingDataSourceProperty
@Getter
@Setter
public class ShardingDataSourceProperty {
private List<Shard> shards;
@Getter
@Setter
public static class Shard {
private String username;
private String password;
private Property master;
private List<Property> slaves;
}
@Getter
@Setter
public static class Property {
private String name;
private String url;
}
}
ShardingProperty
@Getter
@Setter
public class ShardingProperty {
private ShardingStrategy strategy;
private List<ShardingRule> rules;
private int mod;
@Getter
@Setter
public static class ShardingRule {
private int shardNo;
private long rangeMin;
private long rangeMax;
}
}
Config
FriendConfig
friend DB의 DataSource를 생성하는 빈입니다.
@Configuration
@EnableJpaRepositories( ... )
@ConfigurationProperties(prefix = "datasource")
public class FriendConfig {
private ShardingDataSourceProperty friend; // [1]
@Bean
public DataSource friendDataSource() {
DataSourceRouter router = new DataSourceRouter(); // [2]
Map<Object, Object> dataSourceMap = new LinkedHashMap<>(); // [3]
for (int i = 0; i < property.getShards().size(); i++) {
ShardingDataSourceProperty.Shard shard = property.getShards().get(i);
DataSource masterDs = dataSource(shard.getUsername(), shard.getPassword(), shard.getMaster().getUrl());
dataSourceMap.put(i + SHARD_DELIMITER + shard.getMaster().getName(), masterDs); // [4]
for (ShardingDataSourceProperty.Property slave : shard.getSlaves()) {
DataSource slaveDs = dataSource(shard.getUsername(), shard.getPassword(), slave.getUrl());
dataSourceMap.put(i + SHARD_DELIMITER + slave.getName(), slaveDs);
}
}
router.setTargetDataSources(dataSourceMap); // [5]
router.afterPropertiesSet(); // [6]
return new LazyConnectionDataSourceProxy(router); // [7]
}
...
}
[1] yaml에 설정한 프로퍼티(datasource.[module].shards)를 갖습니다.
[2] DataSourceRouter는 AbstractRoutingDataSource를 확장하여 만든 클래스 입니다. 타겟 데이터소스를 등록하고 실제 라우팅을 처리하는 클래스입니다. 아래서 자세히 설명합니다.
[3] 여러 데이터소스 정보를 담기 위한 map입니다.
[4] 데이터소스 map의 키는 “샤드 넘버 + delimiter + 샤드 이름” 형태를 가진 lookup key입니다.
이 키를 이용해 DataSourceRouter에서 데이터소스를 추출하여 사용합니다.
[5] 라우터에 데이터소스 map을 등록합니다.
[6] AbstractRoutingDataSource의 afterPropertiesSet()을 호출합니다.
[7] LazyConnectionDataSourceProxy는 커넥션의 효율적인 활용 뿐만 아니라 멀티 데이터소스(샤딩 및 MHA 구성에 따른)를 구성하기 위해서 필요한 클래스입니다.
데이터소스의 Connection 획득이 실제 쿼리 호출 시에 이루어지도록 함으로써 라우터(아래 DataSourceRouter 참고)가 determineCurrentLookupKey() 메소드를 통해 타겟 데이터소스를 결정할 수 있게 합니다.
ShardingTarget
샤딩 타겟을 정의합니다.
public enum ShardingTarget implements IdentityComparable<ShardingTarget> {
FRIEND, ...
}
ShardingConfig
샤딩 타겟별 설정 정보를 담기 위한 객체 입니다.
@Setter
public class ShardingConfig {
private static Map<ShardingTarget, ShardingProperty> shardingPropertyMap = new ConcurrentHashMap<>(); // [1]
...
public static Map<ShardingTarget, ShardingProperty> getShardingPropertyMap() {
return shardingPropertyMap;
}
}
[1] 샤딩 타겟별 설정 정보를 관리하기 위한 map입니다.
FriendShardingConfig
위에서 정의한 shardingPropertyMap에 샤딩 타겟과 해당 설정 정보를 추가합니다. 샤딩을 적용할 타겟마다 같은 방식으로 추가해줍니다.
@Configuration
@ConfigurationProperties(prefix = "sharding")
@Setter
public class FriendShardingConfig {
private ShardingProperty friend;
@PostConstruct
public void init() {
ShardingConfig.getShardingPropertyMap().put(ShardingTarget.FRIEND, friend); // [1]
}
}
[1] 샤딩타겟은 구분을 위한 키이며, yaml에 있는 sharding.friend를 값으로 설정합니다.
ThreadLocal
UserHolder로 명명한 ThreadLocal holder는 API요청마다 DB접근 전후에 설정 및 해제되는 임시 저장소입니다. 이 샤딩정보(샤딩타겟과 샤딩키)를 이용해 데이터소스 라우팅에 활용됩니다.
public class UserHolder {
private static final ThreadLocal<Context> userContext = new ThreadLocal<>(); // [1]
...
public static void setSharding(ShardingTarget target, long shardKey) { // [2]
getUserContext().setSharding(new Sharding(target, shardKey));
}
public static void clearSharding() { // [3]
getUserContext().setSharding(null);
}
public static Sharding getSharding() {
return getUserContext().getSharding();
}
...
@Getter
@Setter
public static class Context {
...
private Sharding sharding;
}
@Getter
@Setter
public static class Sharding { // [4]
private ShardingTarget target;
private long shardKey;
Sharding(ShardingTarget target, long shardKey) {
this.target = target;
this.shardKey = shardKey;
}
}
[1] ThreadLocal을 만듭니다.
[2] 샤딩 타겟 모듈과 샤딩키를 전달받아 ThreadLocal에 저장합니다.
[3] 저장된 샤딩 정보를 ThreadLocal에서 초기화합니다. ThreadLocal의 사용이 끝나는 지점에서 반드시 초기화해줘야 합니다. 이전에 사용했던 스레드가 재활용되는 경우 ThreadLocal 정보가 유지되기 때문입니다.
[4] ThreadLocal에 샤딩정보를 보관하기 위한 클래스입니다.
Router
라우터는 샤딩타겟과 샤딩키를 이용해 정확한 데이터소스를 찾도록 판단하는 클래스입니다.
DataSourceRouter
public class DataSourceRouter extends AbstractRoutingDataSource { // [1]
private Map<Integer, MhaDataSource> shards; // [2]
@Override
public void setTargetDataSources(Map<Object, Object> targetDataSources) { // [3]
super.setTargetDataSources(targetDataSources);
shards = new HashMap<>();
for (Object item : targetDataSources.keySet()) {
String dataSourceName = item.toString();
String shardNoStr = dataSourceName.split(SHARD_DELIMITER)[0]; // [4]
MhaDataSource shard = getShard(shardNoStr); // [5]
if (dataSourceName.contains(MASTER)) {
shard.setMasterName(dataSourceName);
} else if (dataSourceName.contains(SLAVE)) {
shard.getSlaveName().add(dataSourceName);
}
}
}
@Override
protected Object determineCurrentLookupKey() { // [6]
int shardNo = getShardNo(UserHolder.getSharding()); // [7]
MhaDataSource dataSource = shards.get(shardNo);
...
return TransactionSynchronizationManager.isCurrentTransactionReadOnly() ? dataSource.getSlaveName().next() : dataSource.getMasterName(); // [8]
}
private MhaDataSource getShard(String shardNoStr) {
int shardNo = 0;
if (StringUtils.isNumeric(shardNoStr)) {
shardNo = Integer.valueOf(shardNoStr);
}
MhaDataSource shard = shards.get(shardNo);
if (shard == null) {
shard = new MhaDataSource();
shard.setSlaveName(new RoundRobin<>(new ArrayList<>()));
shards.put(shardNo, shard);
}
return shard;
}
private int getShardNo(UserHolder.Sharding sharding) { // [9]
if (sharding == null) {
return 0;
}
int shardNo = 0;
ShardingProperty shardingProperty = ShardingConfig.getShardingPropertyMap().get(sharding.getTarget());
if (shardingProperty.getStrategy().isRange()) {
shardNo = getShardNoByRange(shardingProperty.getRules(), sharding.getShardKey());
} else if (shardingProperty.getStrategy().isModulus()) {
shardNo = getShardNoByModular(shardingProperty.getMod(), sharding.getShardKey());
}
return shardNo;
}
private int getShardNoByRange(List<ShardingProperty.ShardingRule> rules, long shardKey) { // [10]
for (ShardingProperty.ShardingRule rule : rules) {
if (rule.getRangeMin() <= shardKey && shardKey <= rule.getRangeMax()) {
return rule.getShardNo();
}
}
return 0;
}
private int getShardNoByModular(int modulus, long shardKey) { // [11]
return (int) (shardKey % modulus);
}
@Setter
@Getter
private class MhaDataSource { // [12]
private String masterName;
private RoundRobin<String> slaveName;
}
}
[1] 다중 데이터소스를 사용하는 환경에서 라우터를 구현하기 위해 AbstractRoutingDataSource를 상속받습니다.
그리고 setTargetDataSources(..)와 determineCurrentLookupKey()를 오버라이딩합니다.
[2] 샤드 넘버와 MhaDataSource를 저장하기 위한 map을 선언합니다.
[3] setTargetDataSources(..)는 매 라우팅 시점에 호출되는 것이 아니라 서버 구동시점에 데이터소스를 만드는 과정에서만 호출됩니다. targetDataSources 파라미터는 데이터소스 이름(“샤드 넘버 + delimiter + 샤드 이름”)과 DataSource 객체를 넘겨받습니다.
[4] targetDataSources의 키(조합된 형태의 데이터소스 이름)에서 규칙에 따라 샤드 넘버를 추출합니다.
[5] 샤드 넘버를 이용해 MhaDataSource 객체를 가져오고(없으면 생성), 이어서 데이터소스 이름을 기준으로 master/slave를 판단합니다. 이 과정에서 알 수 있듯이 yaml에 설정하는 명명규칙이 중요함을 알 수 있습니다.
[6] 데이터소스를 결정해야 하는 시점에 콜백됩니다. 규칙에 따라 데이터소스를 판단하기 위해서 이 메소드를 오버라이딩합니다.
여기서는 우선 타겟 샤드를 선택하고, 이어서 master/slave를 판단하게 됩니다.
[7] 앞서 보관했던 ThreadLocal과 샤딩 설정 정보를 통해 샤드 넘버를 얻어옵니다.
[8] 데이터소스의 이름(MhaDataSource의 value)을 lookup key로 리턴하게 됩니다.
현재 트랜잭션의 readOnly 속성을 기준으로 master/slave 여부를 판단하며, 이 때 slave가 여러개일 때는 RoundRobin 알고리즘을 통해 그 중 하나의 slave 데이터소스를 선택하게 됩니다.
[9] 타겟 샤드 넘버를 선택하기 위한 메소드입니다.
앞서 ShardingConfig.shardingPropertyMap에 ShardingTarget을 키로 해서 샤딩룰 설정 정보(ShardingProperty)를 저장했었습니다. 이를 기반으로 레인지/모듈러 방식에 따라 타겟 샤드 넘버를 결정합니다.
샤딩을 적용하지 않은 모듈의 DB라면 default 0을 반환토록 합니다.
[10] 레인지샤딩인 경우 yaml에 설정했던 샤딩키 범위로 타겟 샤드를 선택합니다.
[11] 모듈러샤딩인 경우 yaml에 설정했던 mod 값과 샤딩키의 모듈러 연산 결과로 타겟 샤드를 선택합니다.
[12] 샤드마다 HA구성을 위해 master/slave 데이터소스의 이름을 담는 inner 클래스 입니다. 이때 slave는 여러 개를 등록할 수 있으며 부하를 분산할 목적으로 RoundRobin을 사용합니다.
참고로 RoundRobin클래스는 아래와 같이 만들어 쓰고 있습니다.
public class RoundRobin<T> {
private final List<T> list;
private final Iterator<T> iterator;
private int index;
public RoundRobin(List<T> list) {
this.list = list;
index = 0;
this.iterator = new Iterator<>() {
@Override
public boolean hasNext() {
return true;
}
@Override
public T next() {
T value = list.get(index);
index = (index + 1) % list.size();
return value;
}
};
}
public T next() {
return iterator.next();
}
public void add(T item) {
list.add(item);
}
}
@Sharding
AOP에서 샤딩이 적용됐는지 확인하기 위한 조건으로 쓰기 위해 @Sharding 어노테이션을 추가합니다.
@Retention(RetentionPolicy.RUNTIME)
@Target(ElementType.TYPE)
public @interface Sharding {
ShardingTarget target(); // [1]
}
[1] 어노테이션 추가 시 ShardingTarget을 지정해 줍니다.
RepositoryService
저희는 JPA Repository와 Service 계층 사이에 RepositoryService라는 계층을 추가하여 사용하고 있습니다.
이를 통해 모든 DB 접근은 RepositoryService 클래스를 통하게 되고, DB 요청과 관련된 처리(트랜잭션, 캐시 등)가 이 레벨로 일원화된 구조 입니다.
아래는 friend DB에 접근하는 FriendRepositoryService 예시 입니다.
@Service
@CacheConfig(cacheManager = "friendCacheManager")
@Transactional(value = "friendTransactionManager", isolation = Isolation.READ_COMMITTED, propagation = Propagation.REQUIRES_NEW, readOnly = true) // [1]
@Sharding(target = ShardingTarget.FRIEND) // [2]
@RequiredArgsConstructor
public class FriendRepositoryService implements ApplicationContextAware {
...
private final FriendRepository friendRepository;
@Transactional(value = "friendTransactionManager", isolation = Isolation.READ_COMMITTED) // [3]
public void save(long userId, FriendEntity entity) { // [4]
friendRepository.save(entity);
...
}
@Cacheable(value = FRIEND, key = "{#userId, #friendUserId}", unless = "#result == null")
public Optional<FriendEntity> findFriend(long userId, long friendUserId) { // [5]
return friendRepository.findByUserIdAndFriendUserId(userId, friendUserId);
}
...
}
[1] DB 접근 시 부여할 디폴트 트랜잭션 설정입니다.
기본적으로 find*(..) 메소드들의 경우 readOnly=true설정으로 slave DB를 바라보도록 하며, propagation이 REQUIRES_NEW인 이유는 호출측인 Service레벨에서 트랜잭션이 물려 들어오는 경우에도 새로운 트랜잭션을 생성해 readOnly=true 설정을 탈 수 있도록 하기 위함입니다.
[2] friend DB에 샤딩을 적용하기 위해 @Sharding 어노테이션을 target과 함께 추가해줍니다.
[3] master DB에 접근해야 하는 쿼리인 경우 readOnly=false(default)인 트랜잭션을 명시적으로 선언해줌으로써 DataSourceRouter에서 master 데이터소스가 선택됩니다.
[4] 여기서 중요한 부분은 첫번째 파라미터가 샤딩키로 사용된다는 점 입니다. 이는 샤딩 적용된 DB접근시 샤딩키를 어떻게 판단할지에 관해 저희 서비스 내부에서 정의한 규약입니다.
friend DB는 userId를 기준으로 샤딩을 적용하고 있습니다. 따라서 userId 필드를 첫번째 파라미터로 지정해서 샤딩키로 사용합니다.
[5] find*(..)도 마찬가지로 샤딩키인 userId를 첫번째 파라미터로 넘깁니다.
RepositoryServiceAspect
@Component
@Aspect
@RequiredArgsConstructor
public class RepositoryServiceAspect {
@Pointcut("execution(public * com.woowahan.thiiing.core.repository.service..*.*(..))") // [1]
private void repositoryService() {
}
@Around("repositoryService() && @within(sharding) && args(shardKey,..)") // [2]
public Object handler(ProceedingJoinPoint pjp, Sharding sharding, long shardKey) throws Throwable {
UserHolder.setSharding(sharding.target(), shardKey); // [3]
Object returnVal = pjp.proceed();
UserHolder.clearSharding(); // [4]
return returnVal;
}
}
[1] RepositoryService를 위한 Pointcut입니다.
[2] repositoryService() Pointcut에 걸리면서 @Sharding 어노테이션이 붙은 것에 Around를 적용합니다.
그리고 RepositoryService에서 호출되는 메소드의 첫번째 파라미터는 샤딩키가 됩니다.
앞서 말씀드렸듯이 샤딩키를 알기 위한 저희 팀내 규약입니다.
[3] RepositoryService의 메소드 실행 전에 ShardingTarget과 샤딩키를 ThreadLocal에 임시 보관합니다.
[4] 후처리로 ThreadLocal을 초기화합니다.
유니크 샤딩키 생성
샤딩에서 중요한 또다른 기능이 유니크한 샤딩키 생성입니다.
저희가 샤딩을 적용한 friend DB의 경우는 이미 존재하는 userId를 샤딩키로 잡았기 때문에 유니크한 샤딩키 생성에 대해서는 고려하지 않았습니다.
만약 콘텐츠 DB에 샤딩을 적용하면서 콘텐츠의 id 값을 샤딩키로 잡고자 한다면, 콘텐츠 생성 시점에는 유니크한 id가 없기 때문에 샤딩키를 위한 id generator를 별도로 구현해 줘야 합니다.
동작 예
friend DB에 레인지샤딩을 적용하여 테스트한 결과는 아래와 같습니다.
-
userId <= 1000 : 샤드 0에 저장
-
userId > 1000 : 샤드 1에 저장

이후 DB샤딩하는 방법
- 물리 DB를 추가합니다. 아직은 서비스 적용전 상태입니다.
- 프로젝트 내 yaml설정에 데이터소스 정보(연결정보, 샤딩룰)를 추가해 논리적 연결을 만들어 줍니다.
- 프로젝트를 배포합니다.
Remote Config를 이용해 서버 배포없이 설정을 적용하는 방법도 있지만, DB증설이 빈번히 발생하는 작업은 아니어서 프로젝트 내 yaml로 관리하고 있습니다.
참 쉽죠?
마무리
- 송재욱
서버 개발자라서 온전히 챙겨야 할 이슈들이 있습니다. 더불어 실무자이기에 맞닥뜨리고 싶지 않은 장애 상황도 있습니다.
서비스 오픈전에 그런 점들을 고민했었고, 그 중에는 트래픽을 분산시킬 수 있는 확장 가능한 DB샤딩 방안에 대해서도 준비가 되면 마음의 안정감을 가지고 오픈할 수 있겠다는 생각이 들었습니다. 미리 준비된 상태가 아니었다면 마음 한 켠에 걱정스런 짐을 얹고 있었을텐데, 이 작업을 마친후 다른 기능 개발하는데에도 꽤 가벼운 마음이 들었던 기억이 납니다.
이러한 준비가 서비스를 안정적으로 운영할 수 있는 하나의 무기를 가지게 됐다는 생각이 들었거든요. :) - 전병두
개인적으로 DB 샤딩 기능을 개발하면서 “서비스 운영 중에 설정 추가만으로 쉽게 샤드 추가 작업이 가능해야 한다”는 요구사항을 설정하고 이를 달성하기 위한 방안을 고민, 구현하여 의도한대로 동작하는 것을 보며 큰 재미와 보람을 느낄 수 있었습니다. 프로젝트를 하면서 되도록 외부 솔루션/라이브러리에 대한 의존성을 줄이고 공수가 허락하는 한에서는 필요한 기능을 자체 구현해보고자 팀원분들과 노력했는데요. 그런 분위기 덕분에 챌린지도 많았지만 그만큼 서비스 개발을 더 재밌게 할 수 있었던 것 같습니다.
광고
띠잉앱을 설치해서 사용해보세요 :)
IOS
Android
띠잉 공식 SNS도 운영하고 있어요.
Instagram
Facebook