우리는 불편함을 어떻게 마주하고 있는가
• 박제현

안녕하세요. 신사업부 띠잉셀 박제현입니다.
띠잉 서비스를 개발하면서 어떤 고민을 하며 시스템을 개선했는지, 그리고 그 고민을 해결하는 과정에서 얻은 것은 무엇이었는지 가볍게 공유하고자 합니다.
뭔가 불편하다.
띠잉 서비스는 작년 10월에 오픈했습니다. 오픈 후엔 여느 서비스들처럼 여러 기능도 개선하고 추가 개발을 진행하는데 몰두했어요. 새로운 기능 개발과 버그 수정, 백로그에 쌓인 티켓들까지 많은 일이 쏟아졌습니다. 이런 작업들은 비즈니스 요구에 따라 원하는 시기에 서로 충돌 없이 진행되어야 했고요.
어찌저찌 개발하고 배포하고, 한참 정신없이 작업하던 중에… 무언가 하나둘씩 불편한 점들이 느껴졌습니다.

어떤 부분이 불편한 거지…? 나름대로 잘 하고 있는 것 같긴 한데 뭘 더 개선할 수 있을까? 지금이 최적화된 시스템일까? 지금 우리에게 가장 중요한 것은 뭐지?
계속 생각하다 보니 명확하게 드러나지 않았던 불편한 것들이 보이기 시작했습니다. 오픈을 위해 달려오면서 현실에 타협했던 것들이었죠. 당시 서비스 규모 대비 과한 비용을 지출하고 있던 인프라 비용도 신경 쓰이기 시작했고 하루에 여러 번 배포하거나 급하게 롤백할 때 초조하게 진행 상황만 바라보던 상황들도 꺼림칙했습니다.
그래서 팀원과 한참을 논의하면서 과연 우리가 무엇이 맘에 걸리는 것인지 하나하나 정리하기 시작했어요.
개선 포인트
- 낮은 리소스 사용률
서비스 런칭할 때는 대규모의 트래픽을 감당할 수 있도록 전사적으로 추천되는 인스턴스 타입을 사용하고, 안정성과 고가용성이 고려된 아키텍처를 구성했습니다. 그런데 오픈 후 사용자 트래픽이 꾸준히 증가하긴 했지만 대규모로 구성된 모든 리소스를 알차게 사용할 정도까지는 되지 않아(..) 리소스 활용에 대해 고민하게 되었죠. 비용을 고려하면서 최적화를 해야 했습니다. - 배포 시간
기본적으로 하나의 모듈을 배포할 때 배포 소요 시간은 7분 30초 정도였습니다. 기능 배포뿐 아니라 스케일 아웃, 롤백 등에 드는 시간이 길어 진행되는 동안 서비스 안정성과 개발 효율이 저하되는 상황이었어요. 롤백해야 할 때는 진짜 발 동동 구릅니다.(저만 그런가요…?) - 독립적인 환경 구축의 어려움
환경(Dev, Beta, Prod)마다 구성해야 할 컴포넌트와 리소스가 많아 이를 새로 구성하는 것이 힘든 상황이었어요. Staging 환경을 구축해서 운영 환경과 최대한 동일하게 테스트를 진행하고 싶어도 엄두가 나질 않았습니다. 운영과 최대한 동일하게 구성해 테스트하고, 테스트가 완료되면 사용한 리소스를 일괄 삭제하고 싶었어요. 필요할 때는 즉시 재구성해서 테스트하고요.
어떻게 개선할까?
이를 해결하기 위해 여러 대안을 두고 논의했는데요. 그중 가장 우선이 되었던 것은 컨테이너 환경으로의 전환이었습니다.
컨테이너는 아시다시피 장점이 꽤 많아요.
컨테이너의 장점
- 일관성 있는 환경을 생성할 수 있다.
- 어느 환경에서나 구동되므로 개발 및 배포가 쉬워진다.
- 소프트웨어 전달 주기를 가속한다.
- 시스템 자원을 좀 더 효율적으로 이용할 수 있다.
- 마이크로서비스 아키텍처에서 빛을 발한다.
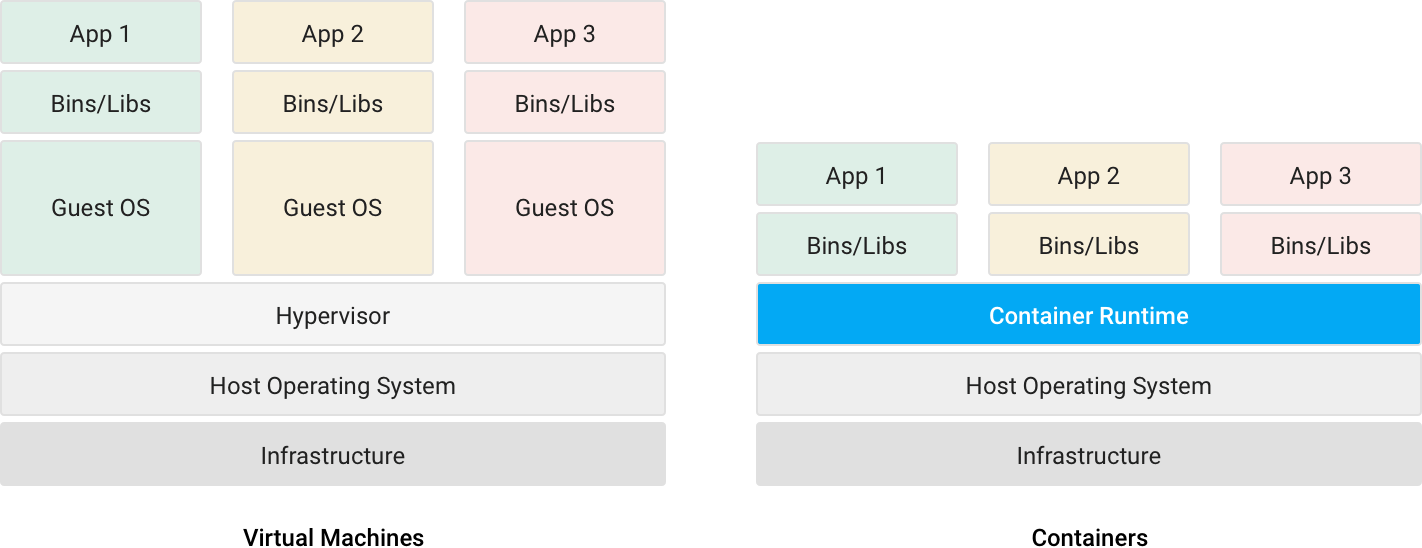
컨테이너의 장점을 십분 활용하면 우리가 불편하게 느꼈던 것들을 개선할 수 있다고 판단했습니다. 그리고 좀 더 세부적으로 비교해봤어요. 컨테이너만 사용할 것인지, 아니면 더 많은 기능을 위해 오케스트레이션 툴을 도입할 지도요. 저희는 AWS를 주로 사용하므로 AWS 위에서 어떻게 구현하는 것이 좋을 것인가에 주안을 두었습니다.
직접 구현 vs 관리형
- 직접 구현: 세밀한 부분까지 원하는 대로 구성 가능, 관리 복잡도 높음
- Docker, Docker swarm, Docker compose
- 적당한 규모에서는 쉽고 편리함
- Kubernetes
- 사실상 오케스트레이션 툴의 표준
- 다양한 기능
- 복잡함, 러닝 커브
- Docker, Docker swarm, Docker compose
- 관리형: 세밀한 기능 부족, 관리 복잡도 낮음
험난한 논의 끝에 최종적으로 관리형 쿠버네티스인 AWS EKS로 구현하는 것으로 결정했습니다.
직접 구현하는 방법은 많은 노력과 리소스가 투자되어야 하기에 지금 상황엔 조금 무리라고 판단했어요. 까딱하면 오버 엔지니어링이 될 수 있고 팀의 리소스도 한정적이니까요. 결국 AWS ECS 대비 다양한 기능을 제공하는 AWS EKS를 우리 서비스에 최적화해서 사용하기로 했습니다.
할 수 있겠어?
본격적으로 작업을 시작하려던 차에 갑자기 이걸 지금 우리가 하는 것이 맞나? 라는 의문이 들었습니다. 불편함을 개선할 방법은 찾았는데, 우리가 지금 직접 하는 것이 맞는지에 대해 아직 저 자신이 납득되지 않았거든요. 우리가 왜 ‘지금’ ‘직접’ 해야 하는지 더 고민하기 위해 주위의 반응이 어떨지 생각해보기로 했어요. 이 작업을 시작한다면 사람들은 저희에게 어떤 얘기들을 할까요? 좋은 반응보다는 부정적인 반응이 대체로 떠올랐습니다.
상상해보는 부정적 반응
- 서비스 개발할 시간도 부족하지 않아요?
기능 개발하면서 인프라 관련 작업까지 다 할 시간 있나요? 지금 꼭 해야 돼요? 백로그에 있는 티켓은 언제 처리하나요? - 그거 제대로 알고 하는 거에요?
컨테이너에 대해선 잘 알고 있나요? Best Practice, 잘 설계된 아키텍처에 대해 제대로 알고 있나요? 범위가 상당한데? 쿠버네티스는 인프라의 거의 모든 것을 다루고 있어서 러닝 커브가 큰데 어떻게 할 건데요? - 담당하는 팀이 따로 있잖아요.
클라우드플랫폼팀에서 전사 배포 플랫폼(Simploy)도 운영하고 있고 새로운 시스템도 준비하고 있지 않나요? 그냥 기존대로 쓰다가 바꾸라고 할 때 바꾸면 되는데 굳이? - 도입했다가 운영 중에 계속 장애 나고 해결 안 돼서 서비스에 영향 주면 어떻게 해요?
장애 나면 어떻게 할 건데요? 장애 대응 네가 다 할래?

너무 부정적인 것 아니냐고요? 위의 반응들은 일하면서 가끔 마주치지 않나요?(ㅎㅎ…) 이런 상황까지 한 번쯤 생각해보면 더 세세한 부분까지 챙길 수 있어요. 다만, 과한 감정 소비를 자제하고 계속 나아가는 것이 중요합니다.
새로운 기술을 도입하는 과정에서 삽질하고 장애도 겪는 등 고단한 일들은 계속 하던 일이라 걱정되진 않지만, 부정적인 반응 속에서 일을 해나간다는 것은 언제나 부담되는 일입니다. 조직장을 설득하지 못한다면 시작조차 할 수 없고 팀원이나 조직 전체의 여론이 좋지 않으면 지원받기도 어려워 진행이 어려워질 수 있으니까요.
그럼에도 불구하고
지금, 우리가 해야 합니다.
당연히 비즈니스 우선순위가 높은 일들은 우선적으로 진행해야 합니다. 사업적 목표를 이루기 위한 일, 그리고 시장 상황과 경쟁사와의 경쟁에 대처하기 위한 일들은 가장 높은 우선순위를 가지며 필사적으로 해내야 해요. 서비스와 직접적인 영향을 미치니까요.
그럼 중요하지만 상대적으로 우선순위가 낮다고 생각되는 작업은 대체 언제 할까요?
우선순위가 낮은 일이라고 하염없이 방치할 순 없고… 지금 하지 않으면 언제 할 수 있을까요? 나중에 언젠가 할까요? 그 언젠가라는 건 언제 올까요? 그 ‘언젠가’는 누가 결정하는 것일까요?
상황은 우리가 만들어가는 것이라고 생각합니다. 서비스에 도움이 된다면 우선순위가 낮더라도 시간을 만들어서 하나씩 해나가야죠. 아무리 작은 작업이라도 사용자에게 가치를 제공할 수 있다면 그것만으로도 소중한 일 일테니까요.
처음이라고, 완벽히 알지 못한다고 해서 시도조차 하지 못한다면 무엇을 할 수 있을까요?
일단 도전해야 경험할 수 있습니다. 누군가 먼저 했던 것을 보고 듣기만 해서 잘 알게 되고 잘 하게 되는 것이 아닙니다. 도전 속에서 시행착오를 겪으며 우리의 것으로 만들어나가야 합니다.
우리 시스템을 직접 구축하게 되면 서비스에서 예상되는 장애 상황에 더 꼼꼼히 대비할 수 있고, 이슈가 발생했을 때 더 빠르게 해결할 수 있습니다. 만약 어려움이 예상되는 부분이 있다면 꼼꼼하게 테스트를 진행하고, 점진적 적용, 롤백, 트러블 슈팅 방안에 대해 철저하게 준비해야 합니다.
우리가 직접 해야 우리에게 정말 필요한 시스템을 만들 수 있습니다.
명확한 작업 기준
진행하면서 혼란이 올 것에 대비해 두 가지 기준을 세웠습니다. 이미 한 두 가지 일을 동시에 하고 있는데도 급한 일이 계속 치고 들어올 때 멘탈을 잡아줄 수 있는 장치로요.
-
우선순위를 치열하게 조정하자
가장 높은 우선순위를 가지는 것은 서비스 개발입니다. 서비스 초반에는 비즈니스 요구 사항을 빠르게 개발해나가는 것이 중요하므로 그에 따른 작업들이 우선시 되어야 합니다. 다만, 중간에 여유 시간이 생기면 쿠버네티스 관련 마일스톤을 하나씩 진행해볼 수 있어요. 항상 무엇을 먼저 해야 하는지 치열하게 고민해야 합니다. 상황에 따라 다시 전환해야 할 수 있으니 작업 티켓을 잘게 분리하는 요령을 가져봅니다. -
유연한 마음가짐을 갖자
잦은 컨텍스트 변경이 있을 수 있음을 감안하고 유연하게 대처할 수 있는 마음가짐을 가지는 것이 중요합니다. 동시에 여러 가지 일들을 병렬로 진행하면 정신없고 스트레스도 받을 거예요. 어느 정도 연습이 필요한 부분입니다.
배포 파이프라인과 쿠버네티스
아래 그림은 새로운 배포 아키텍처입니다. 각 부분들을 전체적인 흐름 위주로 설명합니다. 쿠버네티스의 동작원리 및 세부 설정, 코드 등에 대한 내용은 이 글의 범위를 넘어서기에 제외했습니다. Java와 Node 애플리케이션을 배포하고 있습니다.
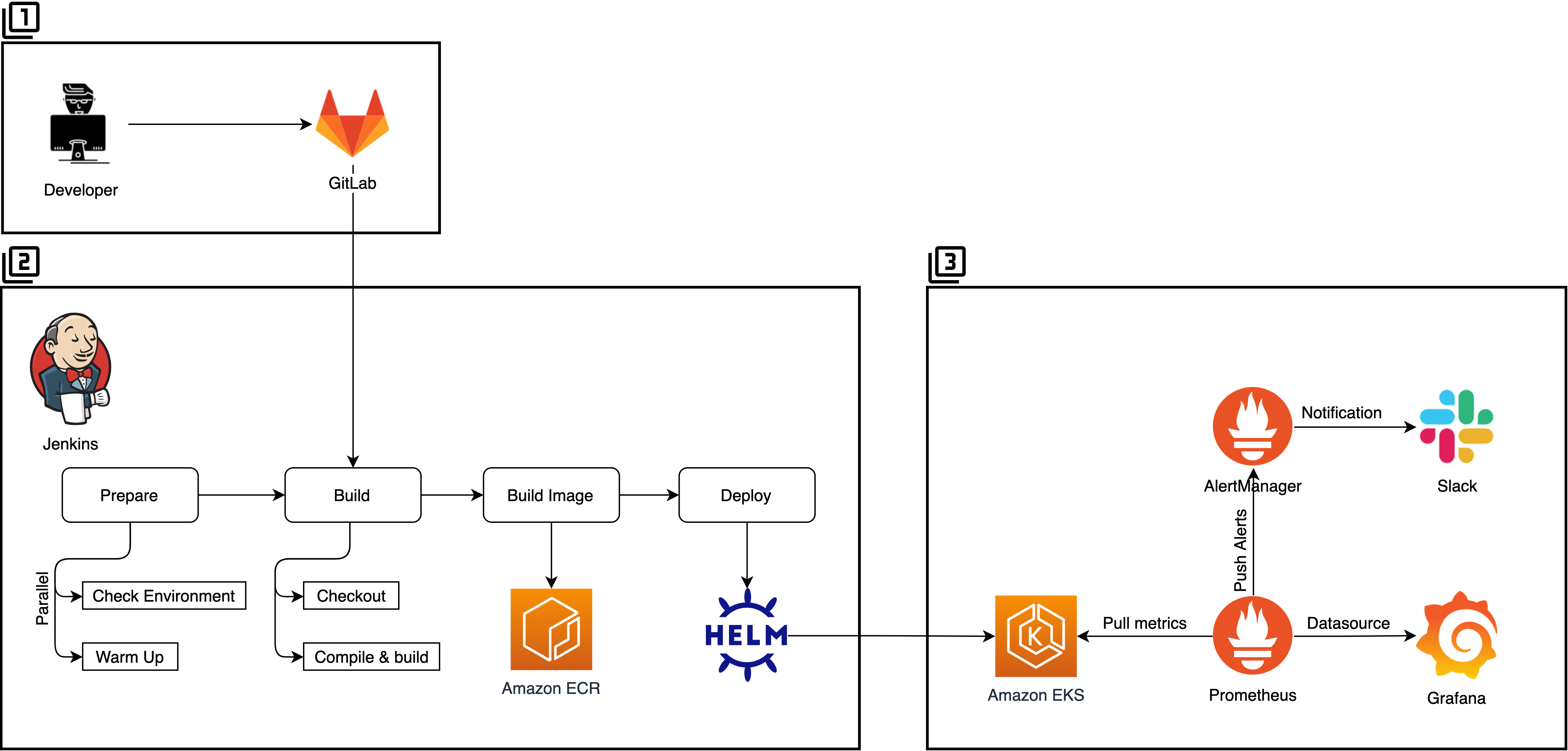
1. SCM
Git으로 애플리케이션 코드를 관리하며 Gitflow 전략을 사용합니다.
2. Jenkins Pipeline
Jenkins Pipeline의 단계(Stage)로 작업을 구분하여 진행합니다. 작업별 수행 시간을 측정하고 튜닝하기 위해 단계를 최대한 세밀하게 분할합니다.
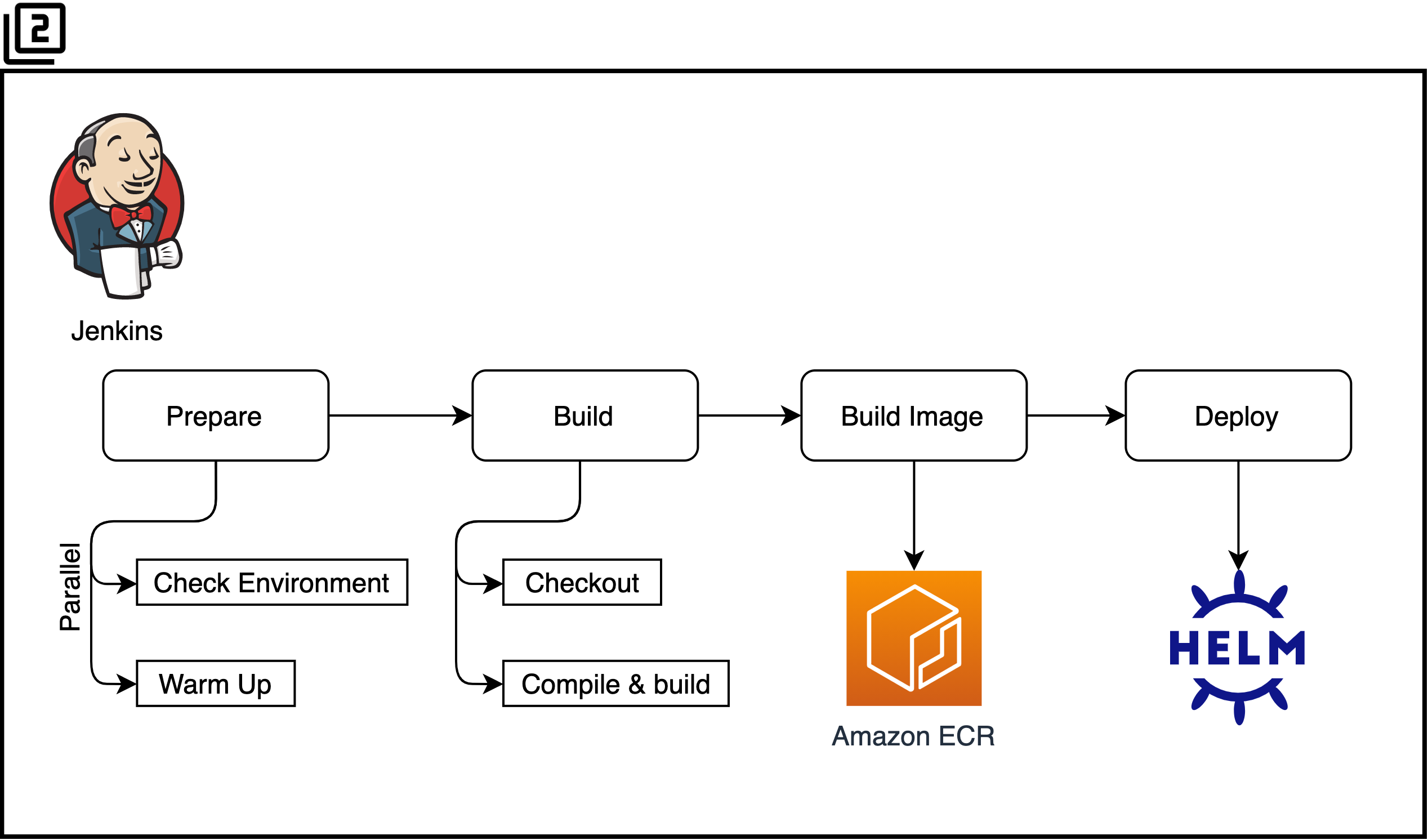
- Prepare
- Check Environment
- 배포 과정에서 필요한 파라미터를 설정하고 기존 환경 및 변경될 환경을 검증합니다.
- Warm Up
- 후속 빌드 과정에서 사용할 Jenkins Agent Pod들을 미리 병렬로 구동하여 전체 파이프라인 실행 시간을 약간이나마 줄입니다.
- Check Environment
- Build
- Build Image
- Deploy
- Helm을 사용하여 애플리케이션을 배포합니다. 초기 세팅 시에는 애플리케이션의 여러 모듈을 manifest로 테스트하고, 정리가 되면 Helm chart로 패키징하여 관리합니다.
3. 쿠버네티스와 프로메테우스
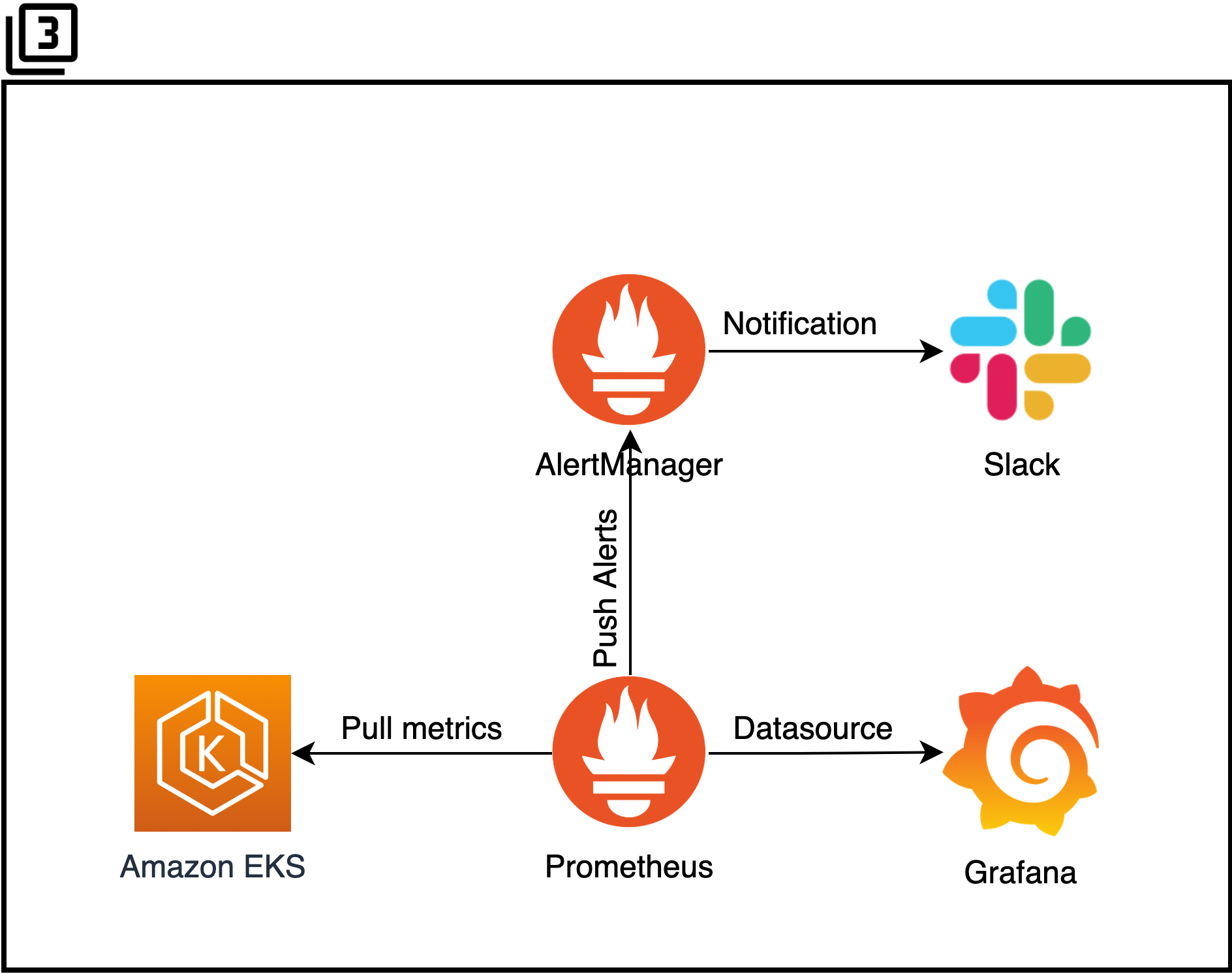
- AWS EKS
- AWS EKS를 사용하며 관리형 서비스에서 얻을 수 있는 이점을 최대한 사용합니다. 특정 서비스를 깊이 사용하다 보면 그 서비스에 매몰되는 것을 항상 걱정하게 되는데요. 계속 상황을 보면서 유연하게 선택해야 합니다. 얻을 것은 얻고 포기할 것은 어느 정도 포기해야 합니다.
- Prometheus
- Prometheus를 사용하여 쿠버네티스 metric을 모니터링합니다.
- Grafana
- Grafana를 구축하여 현재 쿠버네티스의 상태를 Dashboard를 통해 모니터링합니다.(Pod, Container의 CPU, Memory, Network, Count 등)
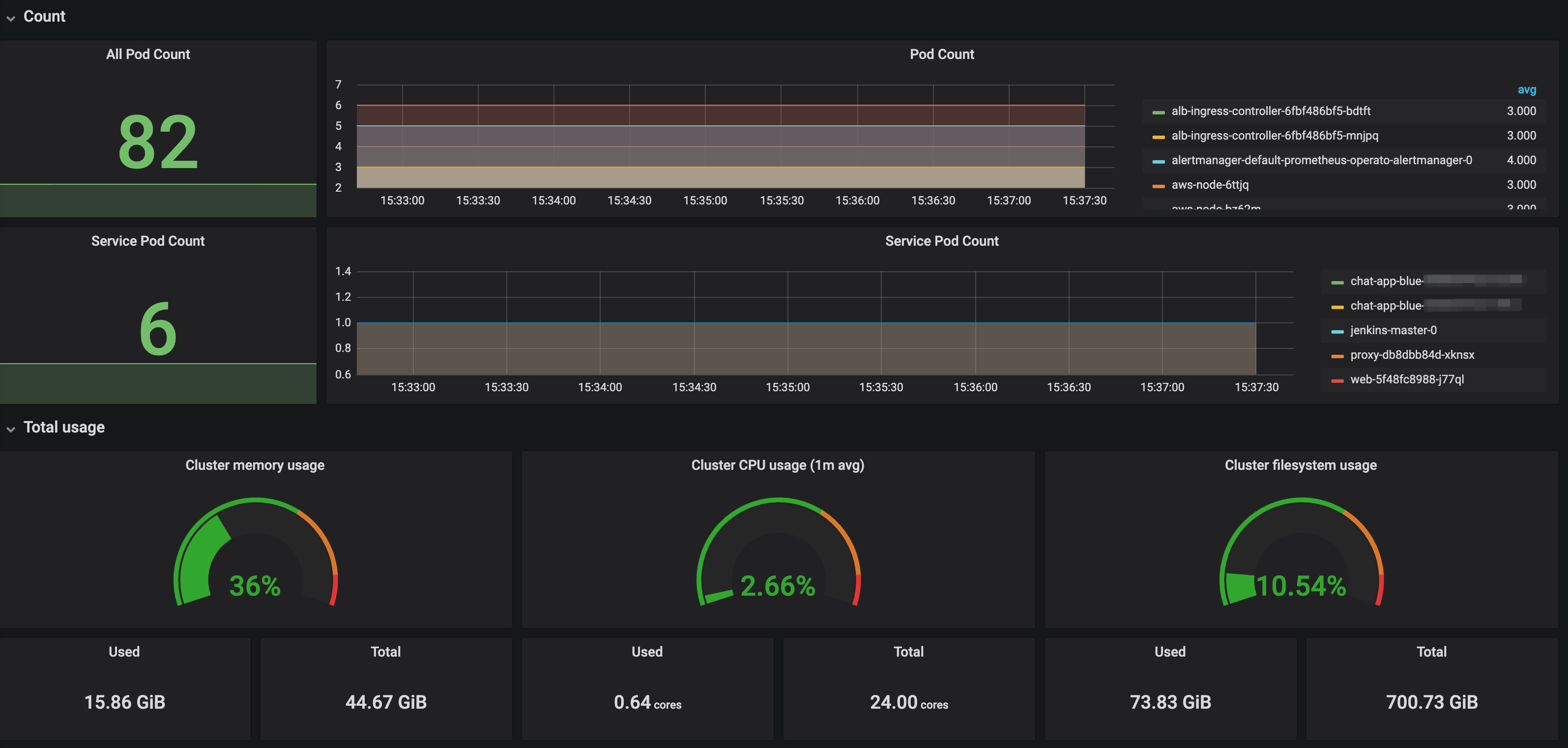 [Grafana Dashboard의 일부]
[Grafana Dashboard의 일부] - Prometheus Alertmanager
-
Alertmanager 설정을 하여 CPU, Memory, 비정상적인 Pod, Container의 상태를 관찰하며 해당 조건에 해당하면 Alert을 발생시킵니다.
prometheus-operator: additionalPrometheusRules: - name: alert-rules groups: - name: cpu-alert-rules rules: - alert: ContainerCpuUsage expr: sum (rate (container_cpu_usage_seconds_total{image!=""}[5m])) by(container_name, pod_name) * 100 > 50 for: 1m labels: severity: warning annotations: summary: "Container CPU usage (container {{ $labels.container_name }})" description: "`{{ $labels.pod_name }}` : `{{ $labels.container_name }}` is above 50% (`{{ $value }}`)" - name: memory-alert-rules rules: - alert: ContainerMemoryUsage expr: sum(container_memory_usage_bytes{image!=""}) BY (container_name, pod_name) / sum(container_spec_memory_limit_bytes{image!=""}) BY (container_name, pod_name) * 100 > 85 and sum(container_memory_usage_bytes{image!=""}) BY (container_name, pod_name) / sum(container_spec_memory_limit_bytes{image!=""}) BY (container_name, pod_name) * 100 != +inf for: 1m labels: severity: warning annotations: summary: "Container Memory usage (instance {{ $labels.instance }})" description: "`{{ $labels.pod_name }}` : `{{ $labels.container_name }}` is above 85% (`{{ $value }}`)" - name: container-alert-rules ... - name: pod-alert-rules ... - name: deployment-alert-rules ...
-
- Slack
- Prometheus Alertmanager를 통해 발생한 Alert은 Slack 채널로 전송됩니다.
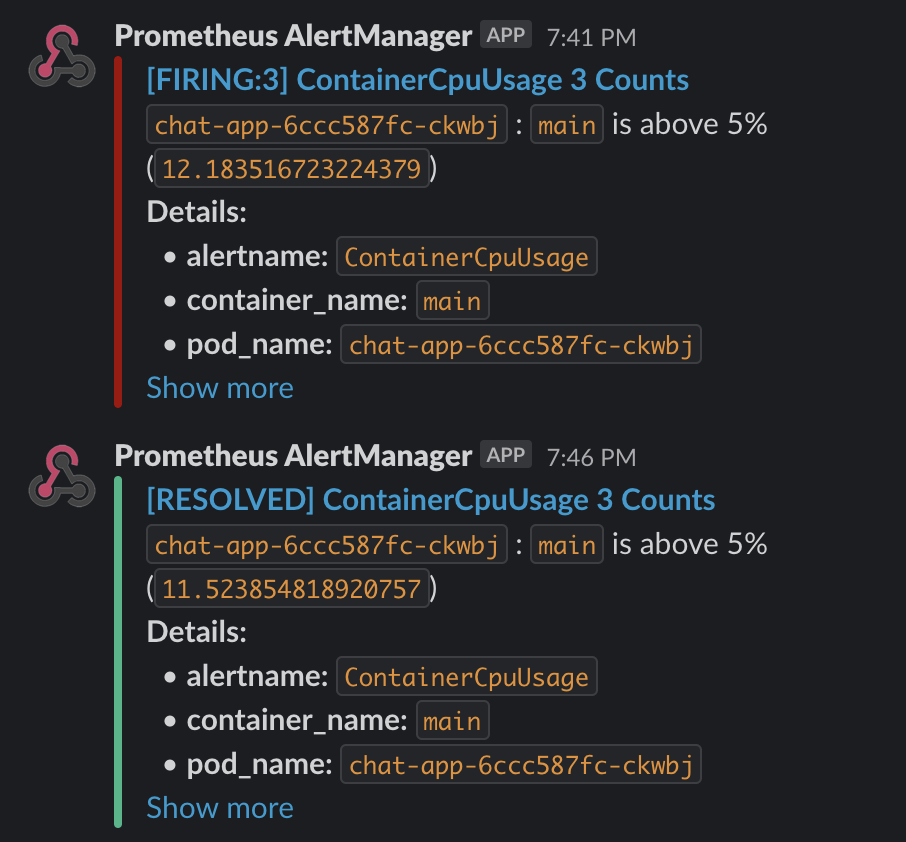 [Slack 알람 테스트]
[Slack 알람 테스트]
- 그 외 로그 시스템(ELK), 프로비저닝(Terraform) 등이 아키텍처에 포함됩니다.
도입 성과
- 리소스 사용률 향상에 따른 비용 절감
- 하나의 인스턴스에 여러 개의 서로 다른 애플리케이션 컨테이너 구동이 가능해졌습니다. 😁
- 개선 전: m5.large 14개 인스턴스 (2 AZ * 서비스 모듈 7개) -> 시간당 0.096 USD * 14 = 시간당 1.344 USD
- 개선 후: c5.xlarge 2개 인스턴스 (2 AZ) -> 시간당 0.17 USD * 2 = 시간당 0.34 USD
- 하나의 인스턴스에 여러 개의 서로 다른 애플리케이션 컨테이너 구동이 가능해졌습니다. 😁
- 소프트웨어 개발 주기 단축
- 배포에 걸리는 시간이 기존 7분에서 개선 후 2분 30초로 개선되었습니다. 😆😆
- 쿠버네티스의 자가치유 기능을 바탕으로 서비스 안정성 증가
- 쿠버네티스는 오류가 발생한 컨테이너를 제거 및 재시작 하며 현재 상태를 요구된 상태로 일치시키려고 끊임없이 확인하는 과정을 수행합니다. 직접 장애를 복구하는 일련의 과정을 생략할 수 있어 부담이 줄어들고, 정상 상태로 더 빨리 복구할 수 있게 되어 시스템 전체의 신뢰성이 향상되었습니다.
- 배포 시스템 최적화
- 직접 배포 시스템을 구축함으로써 우리 서비스에 최적화된 시스템으로 구축하기 쉽고 이슈가 생겼을 때 민첩하게 대응할 수 있게 되었습니다.
- 컨테이너 기반 개발 경험
- 실제 운영 환경에 컨테이너를 적용하는 경험을 통해 앞으로 컨테이너 환경에서 더욱 효율적인 아키텍처를 설계할 수 있게 되었습니다.
공유는 필수
이번 작업을 진행하면서 공유의 필요성에 대해 다시금 깨닫게 되었습니다.
팀 자체가 애플리케이션을 중점적으로 개발하다 보니 서비스 로직에 비해 인프라 작업에 대한 공유는 상대적으로 소홀했습니다. 또한, 공유하는 시간을 갖는 것 자체도 우선순위에서 밀리면서 계속 공유하지 않는 것들이 많아지자 점차 문제가 되었어요.
- 팀원이 아키텍처를 변경해야 할 때마다 물어보고 확인해야 진행이 되는 경우가 잦아져 이로 인해 팀원의 생산성이 떨어지게 됨
- 장애(쿠버네티스 및 컨테이너 이슈 등)가 생겨 빠르게 조치해야 할 때 미리 공유가 되어 있지 않아 담당자 혼자 대응함
이 외에도 Bus Factor를 낮추는 여러 상황들이 팀에게 리스크라고 여겨졌어요. 그 뒤로는 시간 날 때마다 진행 상황을 공유하려 했습니다. (개발보다 공유하는 게 더 어렵…)
- K8s Basic(쿠버네티스 기본 개념)
- 쿠버네티스 접속 방법 및 배포 과정
끝으로
데브옵스? 결국 대화와 신뢰
데브옵스(DevOps)는 소프트웨어의 개발(Development)과 운영(Operations)의 합성어로서, 소프트웨어 개발자와 정보기술 전문가 간의 소통, 협업 및 통합을 강조하는 개발 환경이나 문화를 말한다. 데브옵스는 소프트웨어 개발조직과 운영조직간의 상호 의존적 대응이며 조직이 소프트웨어 제품과 서비스를 빠른 시간에 개발 및 배포하는 것을 목적으로 한다.
Wikipedia
지금까지 인프라를 구축하고 새로운 배포 시스템을 도입하는 등의 작업을 통해 데브옵스의 기반을 만들어나가는 시도를 할 수 있었고 이 과정에서 서비스에 최적화된 개발, 운영 프로세스를 구축할 수 있었습니다. 하지만 이 정도로 데브옵스를 하고 있다거나 데브옵스 조직이 되었다고 명확하게 말하기는 어렵습니다. 소통, 협업에 대한 문화가 필수적으로 뒷받침되어야 합니다.
팀원과의 협업, 개발 리더와 조직장과의 신뢰를 바탕으로 든든한 지원이 있었기에 이번 기회에 조금이나마 나아갈 수 있었다고 생각합니다.
앞으로 해야 할 많은 일들이 기다리고 있습니다. 언젠가 할 일이라면 지금부터 적극적으로 의견을 제시하고 나아가려 합니다.
긴 글 읽어주셔서 감사합니다.