가게 배달지역 관리방식 개편 프로젝트
배달지역 관리방식 개편 (S2)
🙇🏻♂️ 안녕하세요. 우아한형제들에서 가게시스템을 개발하고 있는 윤찬명입니다. 2019년 말부터 2020년 상반기에 걸쳐 진행된 가게 배달지역 관리방식 개편 프로젝트(이하 ‘S2 프로젝트’)의 마이그레이션을 진행했던 경험을 공유하고자 합니다.
배달지역?
배달의민족 서비스에 입점한 가게가 배달하고자하는 영역(지역)을 의미합니다.
(설정한 배달지역 & 가게의 광고 스팟)내의 사용자에게 가게가 노출되고 주문이 발생합니다.
왜 why? 무엇이 문제인가?
자세한 내용에 들어가기에 앞서 기존에는 가게의 배달지역이 어떻게 관리되고 있었는지, 어떤 불편함이 있었는지를 말씀드리고자 합니다.
배달의민족 가게 배달지역은 ‘행정동’을 기반으로 관리되고 있었는데요. 가게 A가 방이1동, 방이2동 등 1개 이상의 행정동을 선택해 해당 지역에 배달할 수 있도록 하는 관리 방식이었습니다.
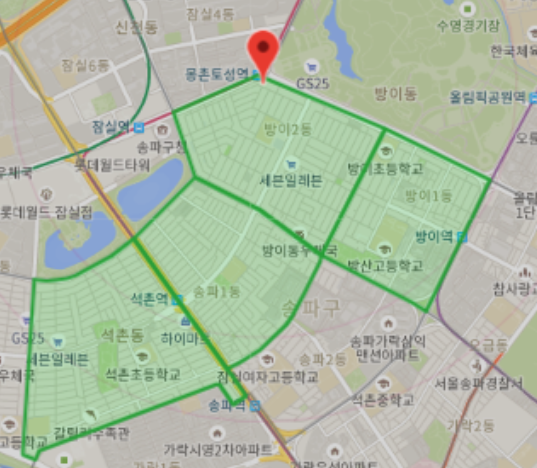
기존의 행정동 배달지역 설정 방식을 활용한 예
이때 몇 가지 문제점이 발생합니다.
-
법정동과 행정동의 명칭은 같은데 경계가 다르거나, 두 개 이상의 법정동이 하나의 행정동으로 운영되는 경우도 있어 경계에 대한 문의가 지속적으로 인입됩니다.
법정동? 행정동? 법정동은 단어 그대로 ‘법으로 정한 동’이라는 뜻으로 법적으로 정해진 행정구역 단위입니다. 각종 법적인 서류(주민등록증 포함)에 기재되는 주소가 법정동 주소입니다. 따라서 변동이 거의 없습니다.
행정동은 행정편의(행정업무 효율성)에 의해 설정된 행정구역 단위입니다. 방이2동주민센터와 같은 주민센터명 앞에 붙은 동 명칭이 행정동 명칭입니다. 주민 수의 증감에 따라 새로 생겨나기도, 합쳐지기도 하는 만큼 변동이 잦습니다.
- 행정동은 지속적으로 갱신이 일어나는 데이터입니다. 행정동 영역이 바뀌면 해당 행정동을 배달지역으로 포함하고있는 가게들에도 영향이 발생합니다.
- 배달지역을 유연하게 설정할 수 없습니다. 근본적인 문제입니다. 교통이 원활하지 못하거나, 오토바이가 진입할 수 없는 지역 등 배달하기 어려운 행정동 영역도 배달하고싶은 영역을 포함한다면 추가해야합니다.
그래서 이러한 문제점을 해결해줄 기술로서 ‘S2’를 검토해보기로 했습니다
S2?
S2는 구글에서 개발한 지리 정보 시스템으로서 지구를 사각형 형태의 ‘Cell’로 쪼개어 넘버링한 시스템입니다.
각각의 Cell은 유니크한 id를 갖게 됩니다.


출처: https://s2geometry.io/devguide/s2cell_hierarchy
S2의 기본적인 원리는 다음과 같습니다.
- 위 그림과 같이 지구를 정육면체로 보고 전개도로 나눕니다. (전개도를 역으로 조립하면 지구같아요!) 이때 0~5, 총 6개의 면이 생기는데요, 각 면을 face cell이라 합니다.
- face cell을 하나 선택해 다시 4개의 사각형(Cell)로 나눕니다. 이때 0~3, 총 4개의 사각형이 생깁니다.
- 2 과정을 원하는 크기의 Cell을 선택할 때까지 재귀적으로 반복합니다. (이때 Cell을 선택하기까지의 depth를 level이라고 합니다. 따라서 level이 높을수록 크기는 작아집니다. 중요.)
-
S2의 모든 셀은 64개의 bit (최대 30 level)로 표현할 수 있습니다.
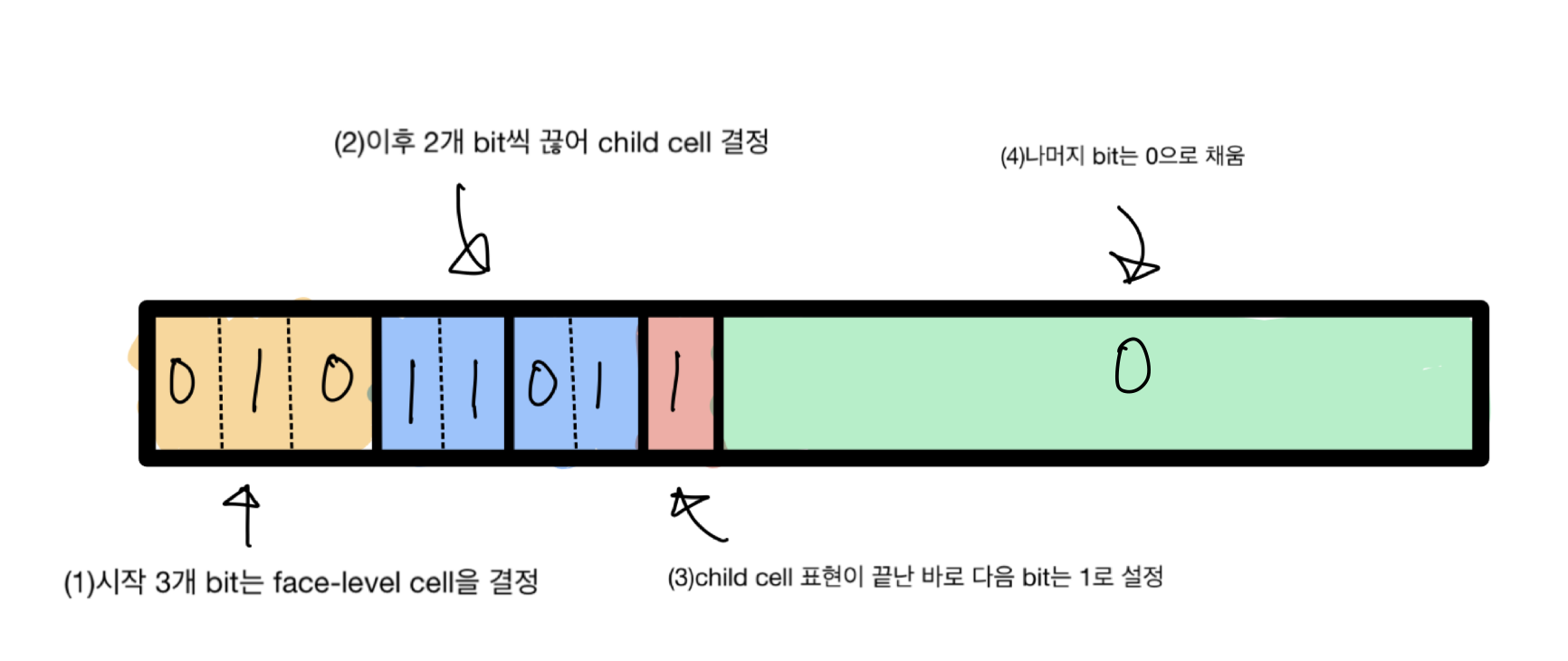
- 시작 3개 bit는 face cell 을 표현하는데에 사용합니다. 010 = 2 이므로, face cell은 2입니다.
- 이후 2개 bit씩 끊어 child cell을 결정합니다. [11, 01] 이므로, 위 그림이 표현하는 cell은 face cell 2의 child cell 3, 다시 그 child cell 1입니다.
- cell을 표현한 직후의 bit를 1로 설정해 표현이 끝났음을 표시합니다.
- 64개 bit 중에서 1~3의 과정을 거치고 남은 나머지 bit를 모두 0으로 채웁니다.
- 위 과정을 거쳐 나온 64개 bit가 선택한 2-3-1 (face=2, level=2) cell의 id를 나타냅니다.
아래는 공식 문서 원문입니다.
where “face” is a 3-bit number (range 0..5) that selects a cube face, and each of the k “child” values is a 2-bit number that selects one of the 4 children during the subdivision process. The bit that follows the last child is always 1, and all other bits are zero. For example: 010 10000...0 Face cell 2. 001 10 100...0 Subcell 2 of face cell 1. 100 11 01 1000...0 Subcell 1 of subcell 3 of face 4. 출처: https://s2geometry.io/devguide/s2cell_hierarchy - 5번을 통해 비트로 표현한 Cell id를 hex string으로 바꾸면 S2 token이 됩니다.
- 이밖에도 space-filling curve를 이용해 순회하는 등의 특징도 갖는데 자세한 내용은 S2 공식문서를 참고하시길 추천드립니다. (쪼끔 어렵습니다.)
눈여겨 볼만한 S2의 장점은 다음과 같습니다. (공식문서에는 다양한 연산, 성능, 공간인덱싱에 유리함 등 여러 장점 서술되어 있지만 아래엔 제가 느낀 장점만 적어보았습니다.)
- 정밀함 → 30level cell 기준 가로/세로 길이가 8~9mm이기 때문에 굉장히 작은 면까지 표현할 수 있습니다.
- 라이브러리에서 셀 정규화 기능을 제공해 하위 4개의 cell을 상위 1개의 cell로 변환할 수 있습니다. → 이 기능을 사용하면 많은 양의 cell도 개수를 줄여 저장할 수 있습니다.
특히 셀 정규화 기능을 제공하는 것이 큰 장점으로 여겨져 S2 적용을 결정했습니다.
S2로 개편하기전 - S2마이그레이션 실험실
S2를 적용하기로 했으니 서비스에서 사용할 S2 level의 최소/최대 구간을 결정해야 했습니다.
따라서 기존에 서비스에서 사용하고 있던 행정동 데이터(Polygon)를 S2방식으로 변환할 경우 몇 개의 Cell이 되는지 테스트가 필요했고, 테스트 결과는 다음과 같았습니다.
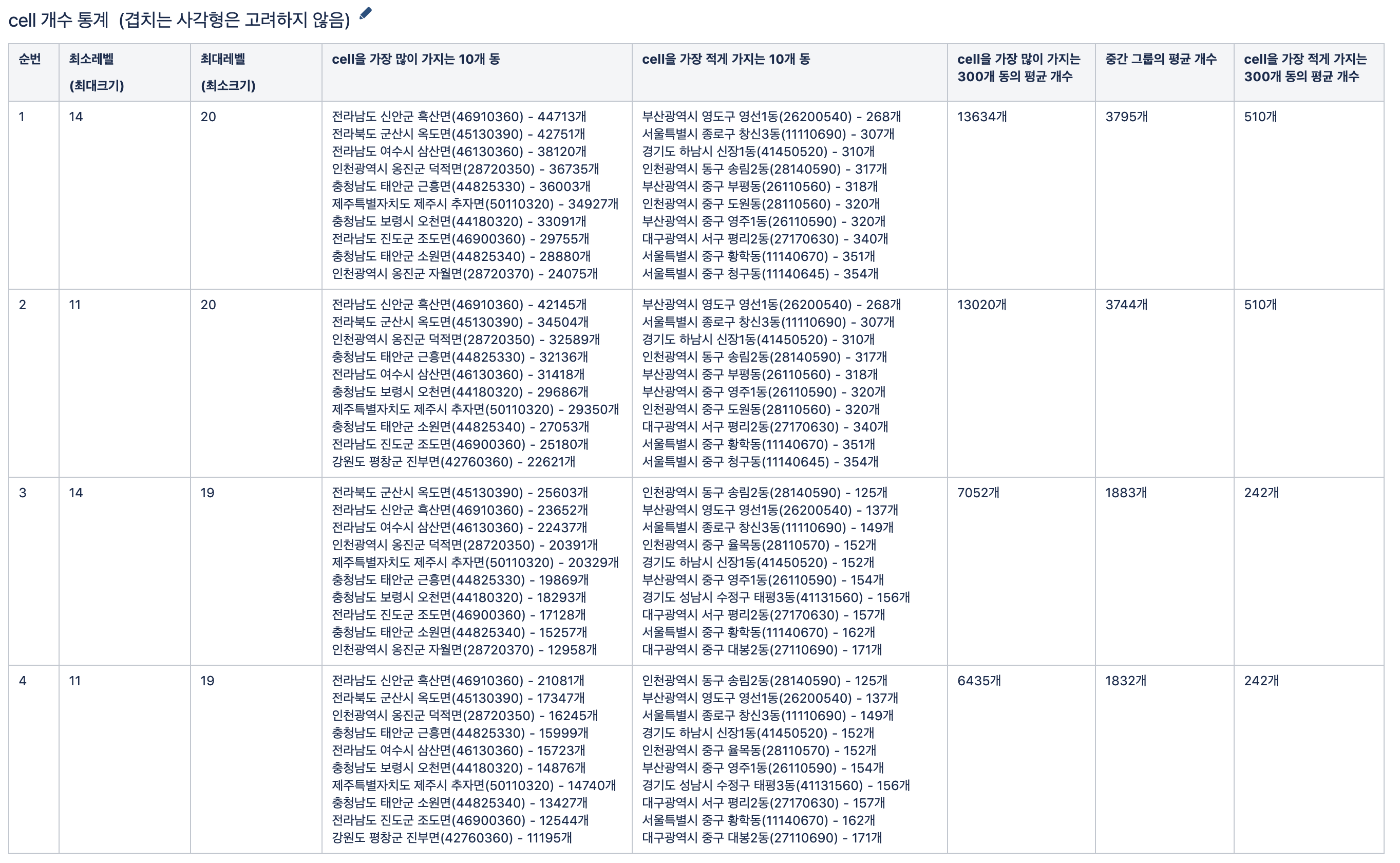
위 실험을 통해 알아낸 점은 다음과 같습니다.
- 최소레벨(최대크기)이 11레벨이냐 14레벨이냐 → 개수 변화가 많지 않습니다. 이는 14레벨보다 셀을 다량 포함하는 행정동이 많지 않다는 걸 의미합니다.
- 최대레벨(최소크기)이 19레벨이냐 20레벨이냐 → 개수가 약 2배가량 차이납니다. 20레벨이 19레벨보다 영역을 훨씬 정밀하게 표현하기 때문에 발생한 결과입니다.
따라서 어차피 개수 차이가 많지 않은 11, 14레벨 중에선 조금 더 정밀한 14레벨을 선택하고, 개수 차이가 많은 19, 20레벨 중에서는 갖은 성능테스트(프런트엔드에서 그릴 때의 성능, 배달 가능 여부를 체크하는 로직 성능테스트 등)를 거쳐 19레벨로 결정했습니다. (많은 도움 주신 타 팀 분들께 압도적 감사……)
S2 마이그레이션 진행
14 ~ 19레벨로 최대/최소 레벨을 결정했으니 보유중인 행정동 데이터를 S2 토큰 기반으로 마이그레이션해야할 때가 왔습니다.
Spring Batch를 이용한 마이그레이션툴을 개발했고, 쓰기작업이 많아 전사 공통 개발 환경에서 직접 수행하기 꺼려져(사실 한 번 해봤다가 CPU 튐) 전사 공통 개발 환경의 데이터베이스 스냅샷을 복원해 독립적인 데이터베이스에서 마이그레이션을 진행했습니다. (* 개발과 운영 환경 행정동 데이터는 차이가 없습니다.)
Spring Batch에 대한 글은 갓동욱님께서 아주 전문적으로 다뤄주시므로 이 글에서는 로직만 다루겠습니다.
들어가기 전, 프로젝트에 s2-geometry 라이브러리 의존성을 추가합니다.
dependencies {
// ...
api group: 'io.sgr', name: 's2-geometry-library-java', version: '1.0.1'
}
각 행정동의 Polygon 데이터를 WKT(Well-Known Text)로 읽어들이고, Polygon을 커버하는 S2 Cell의 집합으로 변환한 후 셀들의 토큰을 저장합니다.
@Bean
@StepScope
public ItemProcessor<Geo, List<S2>> migrateProcessor() {
return geo -> {
String dongCode = geo.getDongCode();
Polygon polygon = geo.getGeofence();
log.info("동코드='{}'", geo.getDongCode());
List<String> tokens = s2GeometryService.toS2Tokens(polygon);
log.info("동코드='{}' S2 token 개수='{}'", dongCode, tokens.size());
return tokens.stream().map(token -> new S2(dongCode, token)).collect(toList());
};
}
각 행정동은 다음 과정을 거쳐 S2 token 집합으로 변환됩니다.
1. 행정동 데이터(Polygon)를 S2Loop로 변환

S2Loop는 구 형태의 S2 점 집합입니다. 점들로 구성된 체인이고, 처음 시작한 점이 마지막에도 한 번 더 오는 구조로 생각하시면 됩니다. 아래 점들도 S2Loop를 이룰 수 있습니다.
# 시작점인 (1, 2)가 마지막에도 한 번 더 왔습니다.
[(0, 0), (1, 1), (1, 1), (0, 1), (0, 0)]
기본적으로 S2Loop는 CCW(Counter-Clock Wise, 반시계방향)으로 점을 가지도록 설계되어있어 CCW를 지키지 않는 경우 동작에 오류가 발생하기도 합니다. 따라서 뒤집어서 방향을 CCW로 바꾸는 정규화(라이브러리의 표현을 그대로 인용)과정을 한 번 거쳐야 합니다.
다시 돌아가서 Polygon 데이터의 점을 모두 꺼내어 S2Point로 변환하고, 변환된 S2Point들을 S2Loop로 만듭니다.
public S2Loop polygonToS2Loop(Polygon polygon) {
S2Loop s2Loop = new S2Loop(getS2PointsFromPolygon(polygon));
s2Loop.normalize();
return s2Loop;
}
protected List<S2Point> getS2PointsFromPolygon(Polygon polygon) {
return Stream.of(polygon.getCoordinates()).map(c -> S2LatLng.fromDegrees(c.y, c.x).toPoint()).collect(toList());
}
S2Loop를 만든 후 정규화합니다.
2. S2Loop(Polygon 영역)를 덮는 Cell들을 가져오기
// covering cell을 구한 후 정규화함 -> 사용할 수 없음
protected List<S2CellId> getCoveringCellIdsWithNormalize(S2Region region) {
return this.regionCoverer.getCovering(region).cellIds();
}
// covering cell을 구한 후 정규화하지 않음 -> 사용가능
public List<S2CellId> getCoveringCellIdsWithoutNormalize(S2Region region) {
ArrayList<S2CellId> cellIds = new ArrayList<>();
this.regionCoverer.getCovering(region, cellIds);
return cellIds;
}
앞에서 변환한 S2Loop를 덮는 Cell들을 가져옵니다.
S2RegionCoverer의 getCovering 메서드를 통해 앞서 만든 S2Loop를 덮는 Cell들을 가져올 수 있는데요, 이때 메서드 사용에 주의해야합니다.
getCovering(S2Region region) 메서드는 Cell들을 구한 후 셀 정규화합니다. 셀 정규화를 진행하면 작은 4개 셀이 더 큰 1개의 셀로 표현되므로 예기치 못하게 minLevel(최대크기)보다 낮은 Level의 Cell들이 결과에 포함될 수 있습니다.
반면 getCovering(S2Region region, ArrayList
테스트를 통해 검증해보겠습니다.
@Test
public void normalizeTest() throws ParseException {
Polygon polygon = (Polygon) new WKTReader().read("POLYGON((125.12766320500009 34.07388744800005,125.12934443400002 34.09125975000006,125.10505848500009 34.10455268100003,125.10430372400003 34.115564762000076,125.06905232800011 34.12827447900003,125.06688174900012 34.12538607700003,125.07962229800012 34.09636242500005,125.08462558600002 34.082637258000034,125.07400239300011 34.07261400500005,125.08470359400008 34.04734345800006,125.10215830100003 34.05658256500004,125.11410312700002 34.038902079000025,125.14722905000008 34.04314643200007,125.14734230500005 34.05102778400004,125.12766320500009 34.07388744800005))");
S2Loop s2Loop = s2GeometryService.polygonToS2Loop(polygon);
// getCovering(S2Region region) 메서드 사용 -> 정규화 O
List<S2CellId> withNormalize = s2GeometryService.getCoveringCellIdsWithNormalize(s2Loop);
// getCovering(S2Region region, ArrayList<S2CellId> covering) 메서드 사용 -> 정규화 X
List<S2CellId> withoutNormalize = s2GeometryService.getCoveringCellIdsWithoutNormalize(s2Loop);
// 정규화한 결과와 정규화하지 않은 결과 모두 원본 폴리곤 위의 셀들이다.
assertTrue(withNormalize.stream().allMatch(cellId -> s2Loop.mayIntersect(new S2Cell(cellId))));
assertTrue(withoutNormalize.stream().allMatch(cellId -> s2Loop.mayIntersect(new S2Cell(cellId))));
// 정규화한 결과보다 정규화하지 않은 결과의 셀 개수가 더 많다.
assertTrue(withNormalize.size() < withoutNormalize.size());
}
동일한 Polygon 데이터를 사용했음에도 불구하고 assertTrue(withNormalize.size() < withoutNormalize.size()); 구절이 정상적으로 통과합니다. 이는 정규화를 진행해 17레벨 Cell 4개가 16레벨 Cell로 치환되면서 개수가 줄어들었기 때문입니다.
시각적으로도 검증 가능합니다. S2 token을 시각화하는 툴 에 토큰을 시각화하자 차이가 확연히 드러났습니다.

정규화된 결과

정규화하지 않은 결과
정규화한 결과에서 중앙의 4개 Cell이 상위레벨 Cell로 치환되었음을 알 수 있었습니다.
마이그레이션에서는 minLevel(최대크기)보다 큰 크기의 Cell이 포함되면 안되기 때문에 getCovering(S2Region region, ArrayList<S2CellId> covering) 를 사용했습니다.
이로써 배치의 핵심 로직을 모두 작성했습니다 🙂
샘플로 몇 개 행정동을 마이그레이션했을 때 문제도 없었고, 배치도 문제없이 돌았겠다.
바로 검증에 들어갔습니다. 하지만..
겹치는 구간이 발생했다.
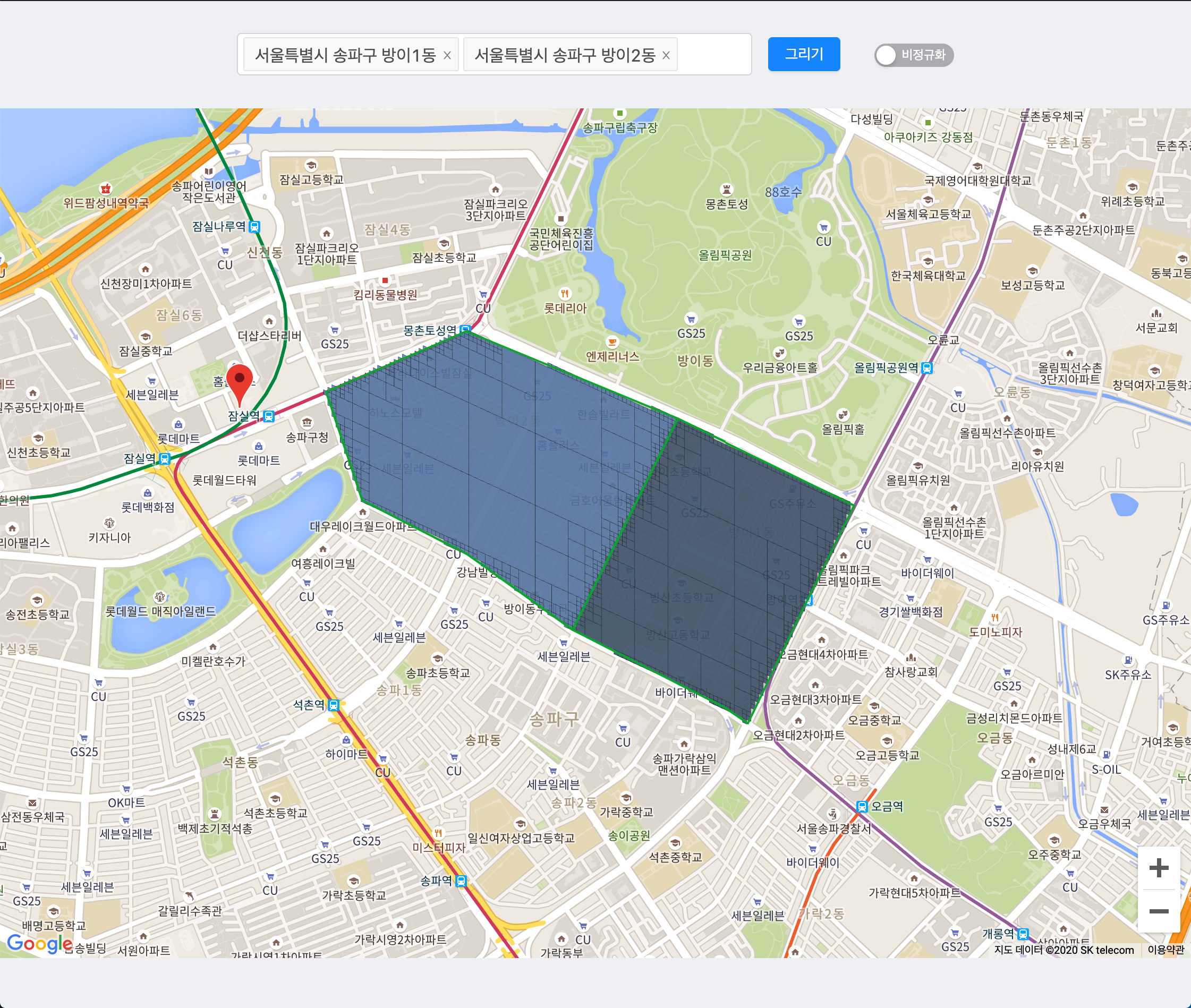
마이그레이션을 마치고 방이1동과 방이2동의 Cell을 시각화해봤습니다.
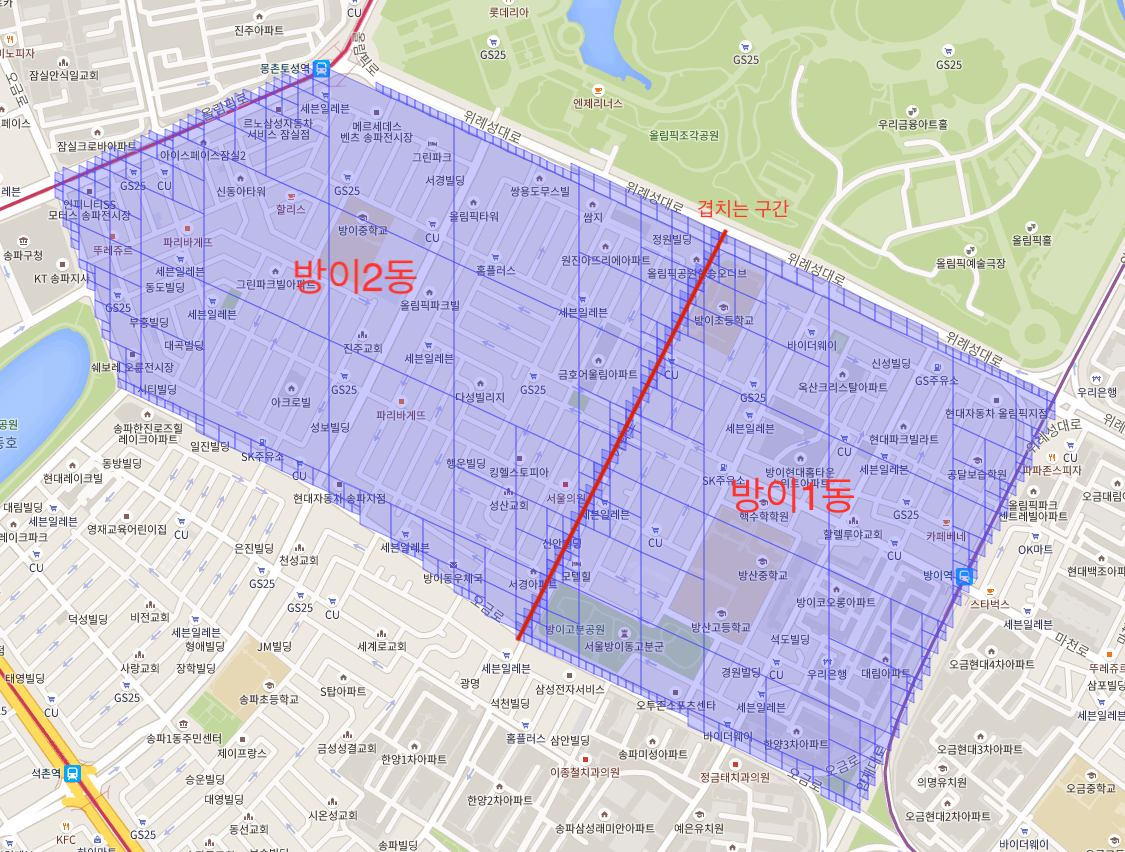
얼핏 예상하던 결과였습니다. 경계를 확대해서 보니
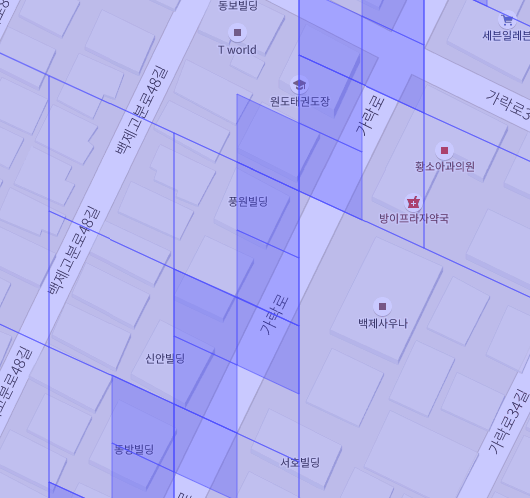
위 처럼 두겹으로 그려져 색이 더 진해져있었습니다.
interioring(속을 채우는, 경계를 넘어가지 않는)이 아닌 covering(완전히 덮는, 경계를 넘어갈 수 있는) 셀들로 변환했기 때문에 토큰(셀의 고유 id)이 겹치는 경우가 충분히 발생할 수 있었습니다.
겹치는 토큰이 몇 개 정도 되는지 뽑아봤습니다.
insert into s2_14to19_intersection (token, times)
select token, count(*)
from s2_14to19
group by token
having count(*) > 1;
결과는 약 1.3만개 토큰, 팀에 마이그레이션 결과를 리뷰하기 시작했고 리뷰중 한 가지 의문점이 발생했습니다. “대한민국 전체를 마이그레이션했는데 겹치는 셀이 만삼천개밖에 안돼요?”
다른 레벨의 Cell이 겹친다
진짜 문제는 따로 있었습니다. 바로 서로 다른 레벨의 셀이 겹친다는 점인데요. 사실 위에서 보여드린 방이1동과 2동 사이의 경계에서도 자세히 보면 동일한 문제를 찾을 수 있습니다.
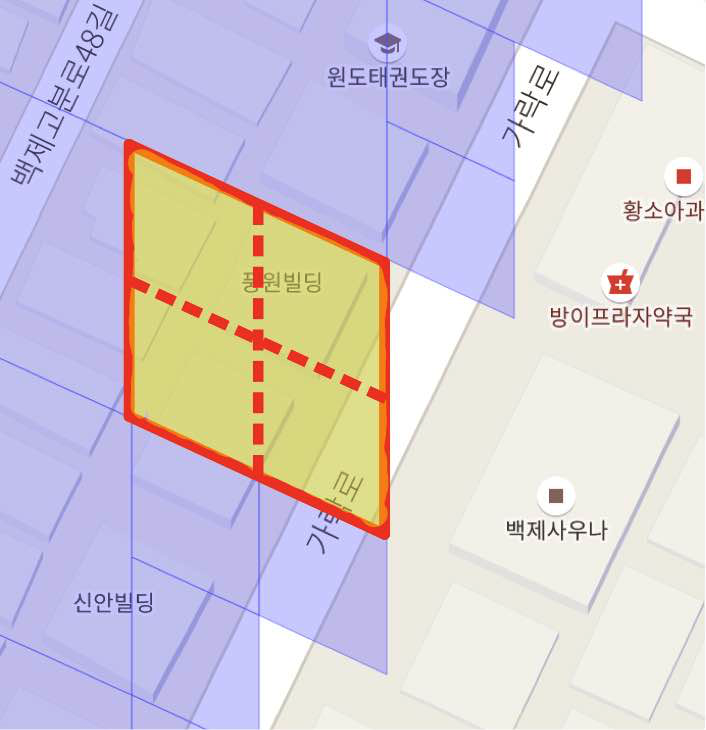
방이2동의 풍원빌딩 인근 마이그레이션 결과
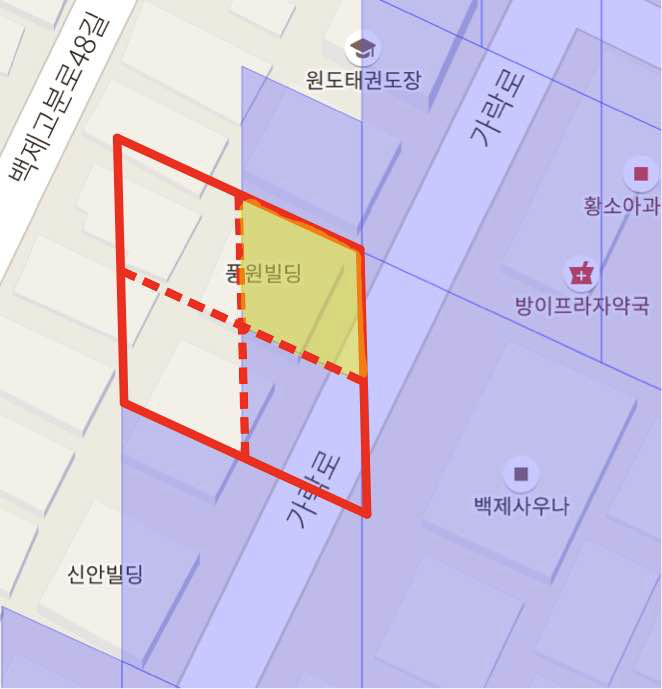
방이1동의 풍원빌딩 인근 마이그레이션 결과
방이2동에서는 풍원빌딩 인근이 18레벨 셀 1개로 마이그레이션 되었지만 방이1동에서는 19레벨 셀 2개로 마이그레이션 되어 다른 레벨끼리 겹치고 있음을 알 수 있습니다.
동일한 레벨의 셀이 중복되어 겹치는 경우에는 앞서 시도한 것처럼 단순히 토큰이 같은 셀끼리 그룹핑하고 소유할 행정동을 선택하면 되지만 다른 레벨간 겹치는 경우에는 토큰 값이 완전히 다르기 때문에 단순 그룹핑이 불가능합니다. 따라서 다른 방법을 찾아야했습니다.
경계를 일정한 크기의 셀로 쪼개자
위 문제의 해결책으로 생각해낸 것이 행정동의 경계에 위치한 셀의 크기를 가장 작은 크기의 셀 (19레벨 셀)로 고정하는 것이었습니다. (다소 원시적이긴 하지만요) 이를 위해서는 한 번 covering 셀을 구한 후 경계선 위의 셀들을 상대로 후속처리해주어야 했습니다.
// 외곽 셀의 크기를 고정한 변환 결과를 반환하는 메서드
public List<String> toBoundaryCellLevelFixedS2Tokens(Polygon polygon) {
List<S2CellId> cellIds = getCoveringCellIdsWithoutNormalize(polygonToS2Loop(polygon));
// polygon의 외곽선 (boundary)을 구한다.
S2Polyline boundary = getBoundary(polygon);
List<S2CellId> boundaryCellIdsLessThanMaxLevel;
// polygon의 경계 (boundary)위의 cell들 중 level이 maxLevel보다 낮은 cell을 추려 한 단계 작은 4개 셀로 치환한다.
while (CollectionUtils.isNotEmpty(
boundaryCellIdsLessThanMaxLevel = cellIds.stream()
.filter(cellId -> boundary.mayIntersect(new S2Cell(cellId)) && cellId.level() < maxLevel)
.collect(toList())
)) {
cellIds.removeAll(boundaryCellIdsLessThanMaxLevel);
cellIds.addAll(boundaryCellIdsLessThanMaxLevel.stream().flatMap(cellId -> to4ChildCells(cellId).stream()).collect(toList()));
}
return cellIds.stream().map(S2CellId::toToken).collect(toList());
}
이로써 경계의 셀들이 모두 동일한 레벨로 쪼개졌습니다.
이후 앞서 시도했던 대로 동일한 토큰끼리 그룹핑해 겹치는 셀의 개수를 뽑아보니
insert into s2_14to19_intersection (token, times)
select token, count(*)
from s2_14to19
group by token
having count(*) > 1;
select count(*) from s2_14to19_intersection; # 3517669
약 350만개 토큰(셀)이 겹치는 정상적인 결과를 얻을 수 있었습니다. 또한 데이터도 아래처럼 예쁘게 들어갔습니다.
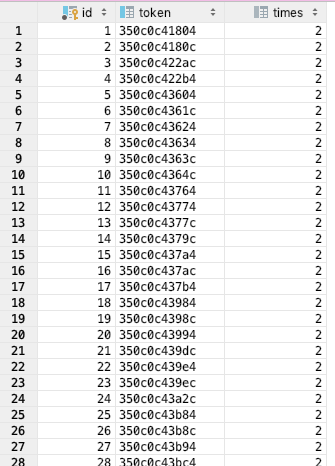
이제는 이 셀들을 어떤 기준으로 소유할 행정동을 결정할지 고민할 차례입니다.
겹치는 셀을 갖게될 단 하나의 행정동 결정하기
겹치는 셀들은 해당 셀의 표면적을 가장 넓게 차지하고 있는 행정동이 갖도록 하는것이 가장 합리적이라 생각했습니다.
따라서 아래 과정을 통해 겹치는 셀을 클렌징했습니다.
- 겹치는 셀 + 행정동 코드 쌍을 읽고
- 해당 셀을 보유중인 행정동중에서 셀과 가장 넓은 면적이 겹치는 행정동을 찾아
- 찾은 행정동이 아닌 행정동의 셀 정보는 삭제
아래는 핵심 로직을 포함한 코드입니다.
/*
영역이 겹치는 행정동 중에서 해당 cell과 가장 넓게 겹치는 행정동을 찾는다
*/
public Polygon findLargestContainingPolygon(List<Polygon> polygons, S2Cell cell) {
if (CollectionUtils.isEmpty(polygons)) {
throw new IllegalArgumentException();
}
return polygons.stream().max(Comparator.comparingDouble(polygon -> getIntersectionArea(polygon, cell))).orElseThrow(IllegalArgumentException::new);
}
/*
행정동과 cell로 만든 폴리곤의 겹치는 면적을 계산
*/
private double getIntersectionArea(Polygon polygon, S2Cell cell) {
S2Polygon s2Polygon = new S2Polygon(polygonToS2Loop(polygon));
S2Polygon cellPolygon = new S2Polygon(new S2Loop(cell));
S2Polygon intersection = new S2Polygon();
intersection.initToIntersection(s2Polygon, cellPolygon);
return intersection.getArea();
}
배치 잡 역시 성공적으로 수행 완료 했고, 검증을 위해 겹치는 셀을 찾기 위해 사용했던 쿼리를 다시 날려보니
select token, count(*)
from s2_14to19
group by token
having count(*) > 1;
결과는 비어있었습니다. 드디어 겹치는 토큰이 모두 사라졌습니다. 전체 s2 토큰의 개수도 약 1500만 개에서 1150만 개 정도로 줄었습니다.
결과는 어떻게 검증할 건데?
마이그레이션이 끝났으니 결과가 완전한지 검증해보아야 합니다.
검증할 점은 크게 3가지 입니다.
- 내륙에 빈틈이 없는가
- 외곽지역, 섬지역의 마이그레이션 결과에 문제가 없는가
- 겹치는 영역이 없는가(*다른 레벨 포함)
내륙에 빈틈이 없는가
마이그레이션 이전 원본 (polygon)이 대한민국 내륙에 빈틈이 없었습니다. 따라서 마이그레이션된 결과에서도 내륙에 빈 틈이 있어선 안됩니다.
이는 다음과 같은 과정을 통해 검증했습니다.
- 마이그레이션 결과 1150만개 셀을 모두 읽어 정규화하고, 다시 텍스트파일로 내보낸다.
- 내륙 지방의 대부분을 덮는 레벨인 6~9레벨 셀을 시각화해본다.
- 대한민국 내륙 지방을 잘 덮는지 확인한다.
작성할 핵심 코드는 간단합니다.
List<String> tokens = getAllMigratedTokens();
S2CellUnion union = new S2CellUnion();
// 앞서 읽은 전체 토큰으로 initialze.
union.initFromCellIds((ArrayList<S2CellId>) tokens.stream().map(S2CellId::fromToken).collect(toList()));
// 정규화
union.normalize();
// 이후 S2CellUnion의 모든 s2 token을 파일로 쓰기
다음과 같은 파일이 작성됩니다.

마이그레이션 결과 전체를 정규화한 후 내보낸 결과
내륙 지방의 대부분을 덮는 레벨인 6~9레벨 토큰만을 뽑아 모두 시각화 툴에 그려보니
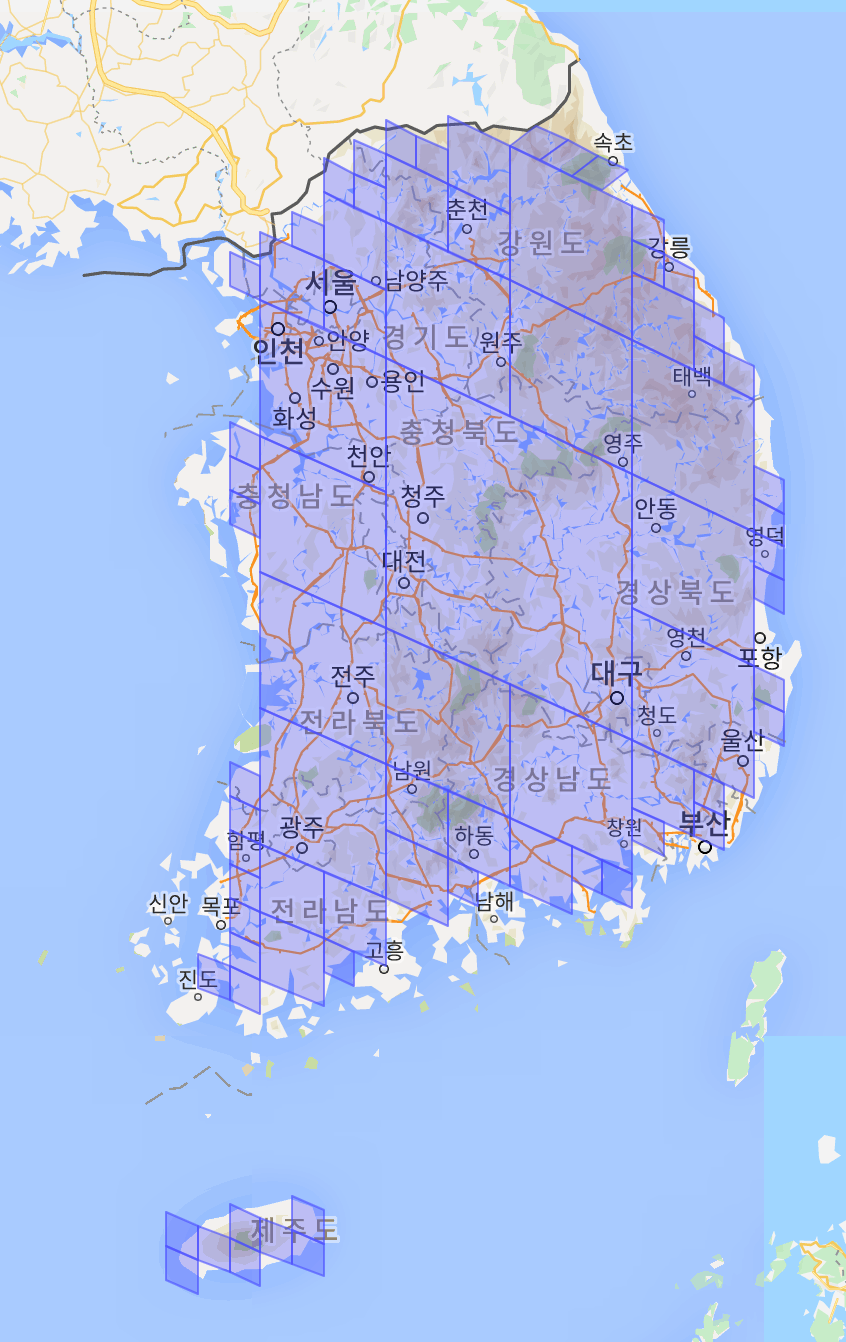
대한민국 내륙 지방이 모두 큼지막한 사각형으로 잘 채워져 있음을 알 수 있었습니다.
만약 내륙에 조금이라도 빈 틈이 있었다면 해당 지역은 정규화되지 않아 잘개 쪼개져 있었을거에요.🙂
외곽지역, 섬지역의 마이그레이션 결과에 문제가 없는가
외곽지역이나 섬지역의 마이그레이션 결과를 보기 위해서는 해당 지역의 토큰을 모두 꺼내어 시각화 툴에 그려보아야 했는데요. 앞서 사용했던 시각화 툴에서는 많은 토큰을 동시에 그리기 어렵고, 매번 특정 동의 토큰을 모두 선택해 그려 검증해야 했습니다.
따라서 여러 행정동을 동시 선택해 지도에 표시해 검증할 수 있는 툴을 별도로 개발해 외곽, 섬 지역들을 수월하게 검증할 수 있었습니다.
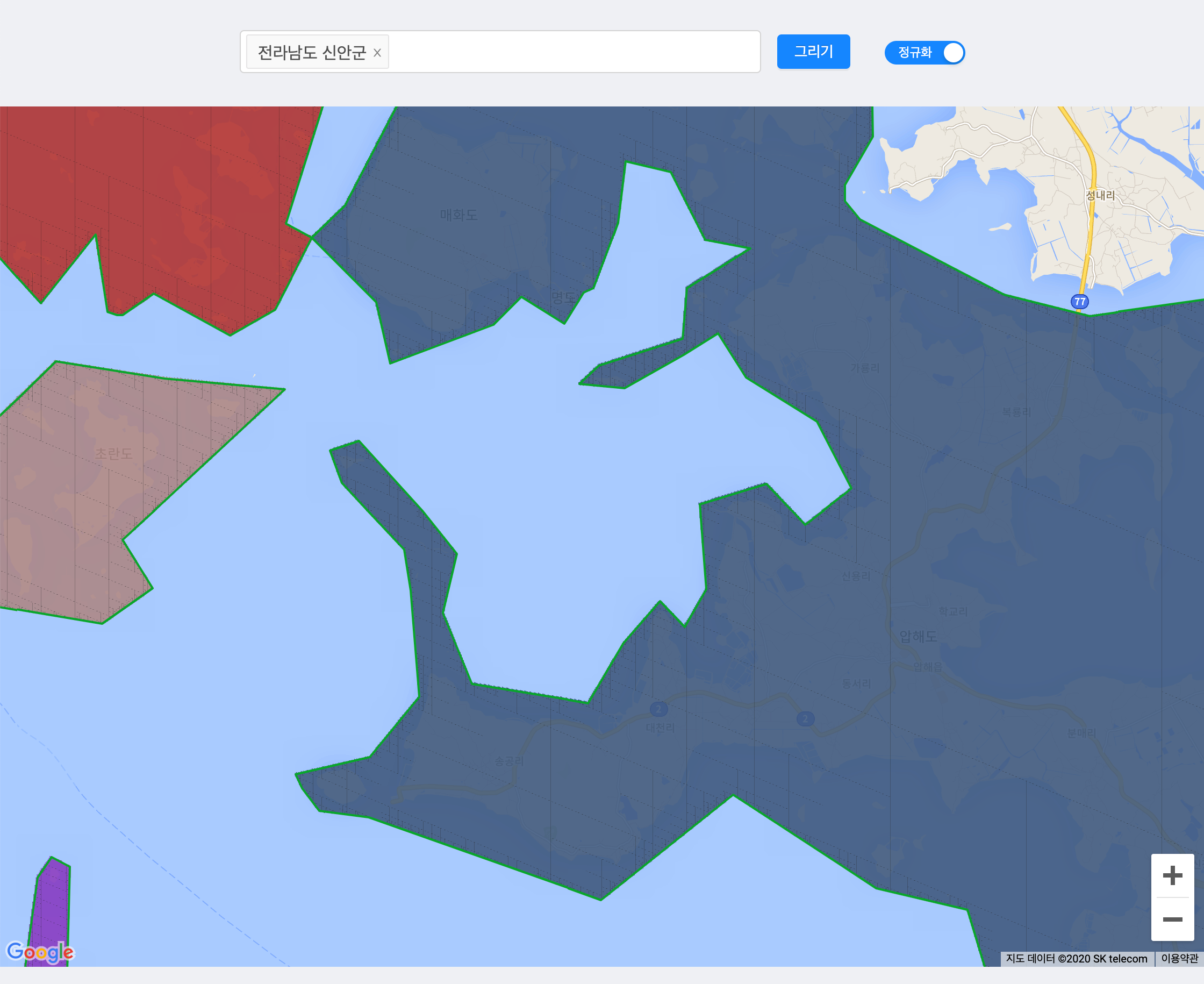
겹치는 영역이 없는가(*다른 레벨 포함)
앞서 경계를 maxLevel로 모두 쪼개어 처리했으니 행정동간 동일한 레벨끼리 겹치는 영역은 없습니다. 서로 다른 레벨간 겹치는 영역 또한 없어야 하는게 맞습니다. 하지만 고려하지 못한 엣지 케이스가 존재해 겹치는 토큰이 발생할 수 있다고 생각했습니다. 만약 겹치는 토큰이 존재한다면 특정 위경도 좌표에서 좌표에 해당하는 행정동 조회시 여러개의 동이 조회될 수 있게 되고, 이는 작지 않은 문제가 됩니다.
따라서 자동화된 검증 방법이 필요했고 트리 자료구조에서 아이디어를 얻어 검증에 사용했습니다.
- 셀을 모두 꺼내어와 레벨 오름차순으로 정렬
- 셀의 위치를 표현할 수 있는 자리를 탐색(ex. 5-3-2 셀은 face5번 셀의 3번 자식셀의 2번 자식셀 위치)
- 자리를 찾은 경우 S2CellId를 할당해 해당 셀이 존재함을 표시
- 트리에서 할당할 자리를 찾는 도중 S2CellId가 들어있는 노드를 거치거나, 할당할 자리에 이미 동일한 S2CellId가 들어있는 경우 중복이 발생했음을 의미
코드는 다음과 같습니다
public boolean validateNoIntersection() {
List<S2CellId> s2CellIds = getAllMigratedTokens()
.stream()
.map(S2CellId::fromToken)
.sorted(Comparator.comparing(S2CellId::level))
.collect(toList());
log.info("total cells: {}", s2CellIds.size());
S2CellIdTree tree = new S2CellIdTree();
for (S2CellId cellId : s2CellIds) {
if (!tree.addS2Cell(cellId)) {
log.error("겹치는 영역 발생: {}", cellId.toToken());
return false;
}
}
return true;
}
S2CellIdTree.java
import com.google.common.geometry.S2CellId;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
public class S2CellIdTree {
private static final Logger log = LoggerFactory.getLogger(S2CellIdTree.class);
private final S2CellIdNode[] faceCells;
public S2CellIdTree() {
this.faceCells = new S2CellIdNode[]{S2CellIdNode.empty(), S2CellIdNode.empty(), S2CellIdNode.empty(), S2CellIdNode.empty(), S2CellIdNode.empty(), S2CellIdNode.empty()};
}
/**
* 해당 인덱스의 노드가 비어있는 상태일 경우에만 노드를 채워넣음.
* S2CellId를 받아 트리의 올바른 위치에 S2CellIdNode로서 채워넣음
* 탐색 도중 비어있지 않은 노드가 있는 경우 위치 탐색을 중지하고 false 반환
*
* @param s2CellId 트리에 추가할 S2CellId
* @return 추가여부 - false의 경우 들어갈 위치의 노드가 비어있지 않거나, 상위 노드가 비어있지 않음 (더 낮은 레벨의 셀과 겹침)
*/
public boolean addS2Cell(S2CellId s2CellId) {
// face level node를 결정
S2CellIdNode node = faceCells[s2CellId.face()];
// face level에 이미 S2CellId가 들어가있는 경우
if (!node.isEmpty()) {
log.error("{} is child of {}", s2CellId.toToken(), node.getS2Token());
return false;
}
// 1레벨부터 넣고자하는 S2CellId의 레벨까지 순회
for (int level = 1; level <= s2CellId.level(); level++) {
// 레벨에서의 인덱스를 찾아 (0..3) 그 위치의 노드를 가져온다.
int pos = s2CellId.childPosition(level);
node = node.getChild(pos);
// 노드에 이미 S2CellId가 들어가있는 경우 중복이 발생했음을 알 수 있다.
if (!node.isEmpty()) {
log.error("{} is child of {}", s2CellId.toToken(), node.getS2Token());
return false;
}
}
return node.setS2CellId(s2CellId);
}
}
S2CellIdNode.java
import com.google.common.geometry.S2CellId;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import java.util.Optional;
public class S2CellIdNode {
private static final Logger log = LoggerFactory.getLogger(S2CellIdNode.class);
private S2CellId cellId;
private S2CellIdNode[] childCells;
private S2CellIdNode() {
}
public boolean isEmpty() {
return cellId == null;
}
public S2CellIdNode getChild(int index) {
if (childCells == null) {
childCells = new S2CellIdNode[]{empty(), empty(), empty(), empty()};
}
return childCells[index];
}
/**
* 해당 인덱스의 노드가 비어있는 상태일 경우에만 노드를 채워넣음.
*
* @param cellId 채워넣을 child cell
* @return 할당 여부
*/
public boolean setS2CellId(S2CellId cellId) {
if (!isEmpty()) {
log.error("'{}' token이 이미 존재함", cellId.toToken());
return false;
}
this.cellId = cellId;
return true;
}
public String getS2Token() {
return Optional.ofNullable(cellId).map(S2CellId::toToken).orElse(null);
}
public static S2CellIdNode empty() {
return new S2CellIdNode();
}
}
겹치는 토큰이 존재하는 케이스와 존재하지 않는 케이스로 모두 검증해본 결과 모두 정상적으로 검증 되었고, 이로써 1100만개 이상의 S2 토큰들 중 겹치는 토큰(다른 레벨 포함)이 존재하는지를 수 초 내에 검증할 수 있게 되었습니다.
드디어 모든 마이그레이션과 검증 과정을 마쳤습니다.
마이그레이션 과정 정리
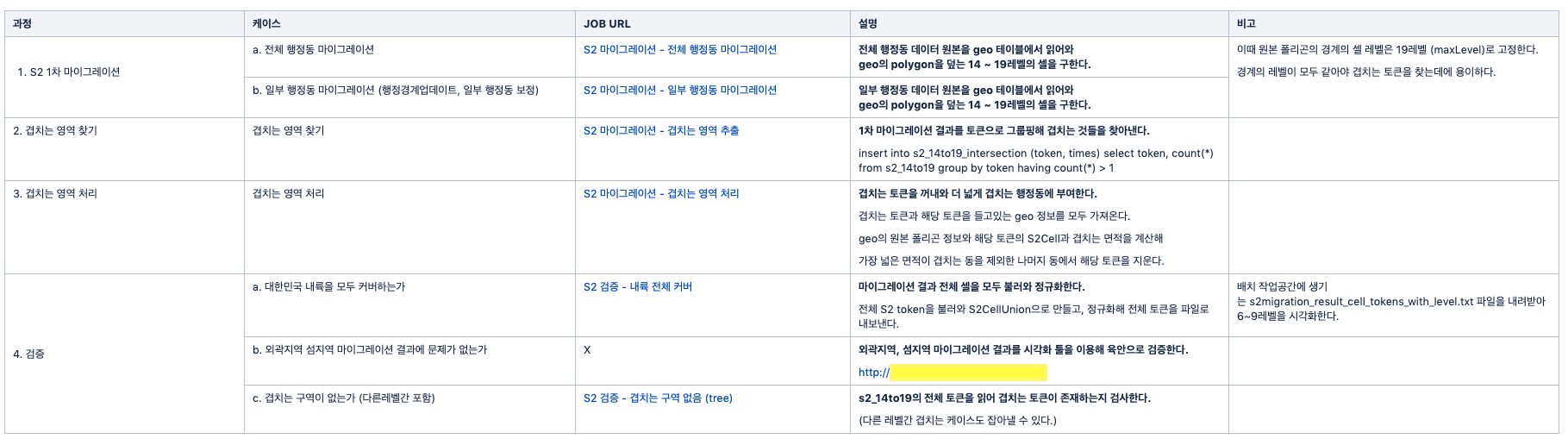
전체 마이그레이션 과정을 정리하면 다음과 같습니다.
- S2 1차 마이그레이션
→ 이후 다른 레벨의 셀 간 겹치는 케이스를 발견해 외곽 셀의 크기를 고정한 상태로 재마이그레이션 했습니다. - 겹치는 영역 추출
- 겹치는 영역 처리
- 검증
- 대한민국 내륙을 모두 덮는가
- 외곽지역 또는 섬지역 마이그레이션 결과에 문제가 없는가
- (다른 레벨 포함) 겹치는 영역이 없는가
결과
결국 S2는 성공적(?)으로 적용되었습니다. (마이그레이션 이후 오픈까지의 과정도 만만찮았지만.. 기회가 된다면 다른분께서 새로운 글로 다뤄주시겠죠..!?)
적용 후 사장님께서는 배달지역을 기존에 비해 훨씬 유연하게 설정하실 수 있습니다. 그덕에 서비스적인 발전 가능성이 높아졌 다고믿고싶 고요.
내게 있어
돌아보면 S2프로젝트는 제게 있어 단순히 가게 배달지역을 유연하게 설정할 수 있게 되었다. 라는 한 줄 이상의 의미를 갖고 있습니다.
이곳이 첫 회사인 신입 개발자로서 그동안 진행했던 프로젝트는 일하는 방법을 배우고 몰랐던 것을 알아가는 데에 중점이 맞춰져 있었습니다. 반면 S2프로젝트는 기존 적용 사례도 없고 레퍼런스도 거의 없는 상태에서 주도적으로 움직이고 공유하는 입장에서 진행해야 했어요. 물론 큰 방향은 다 제시해주셨고 이제와서 돌아보니 떠먹은 기억밖에 없네요 😹
진행 중 여러 시행착오를 겪기도 하고, 어리버리해서 안 해도 될 고생을 사서 하기도 하고, ‘내가 잘 해낼 수 있을까?’ 하는 생각때문에 정신적으로 힘들었던 때도 많았습니다. 하지만 아무도 나무라지 않으셨고요. 격려해주시고 자신감을 불어넣어주셨어요. 그덕에 성공적으로 마칠 수 있었습니다. 정말 감사합니다 🙏🏻
그렇게 제 알을 깨고 한꺼풀 더 성장하게 만들어준 프로젝트였기에 글로써 기록하고 싶었던 것 같습니다. (너무 오랜 시간 적은게 문제네요..)
S2 프로젝트를 마무리하고 나의 성공 시대 시작됐다~
사실 S2를 검토중인 분을 제외하고는 기술적으로 큰 인사이트는 드리지 못했을 것 같아 송구하지만, 얘 애썼구나.. 하는 애정어린 시선으로 봐주시길 부탁드립니다 🙇🏻♂️
다음번엔 더욱 영양가있는 글을 들고 올 수 있도록 노력할게요!
진짜 마지막으로!
가게시스템팀은 아직 갈 길이 멀어요.. 자동화해야할 업무도 쌓여있고요. 시스템 개선포인트도 많답니다. 함께하실 분을 애타게 기다리고 있어요 😉
살짝 관심이 생겼다면? 여기
감사합니다. 🙇🏻♂️