배민 API GATEWAY - spring cloud zuul 적용기
서비스를 운영하고 개발하는 팀이라면, LEGACY라는 거대한 괴물이 얼마나 다루기가 힘든 일인지 동감 할 것이다. 이 괴물이 오래되면 될수록, 크면 클수록… 제가 운영하고 개발하고 있는 팀에도 7년 묵은 괴물이 살고 있습니다. 이 괴물을 한번에 팍~하고 변화시키기에는 너무나 많은 개발 비용이 듭니다. 그리고 운영은 어쩔… 그래서 저희 팀에서는 API GATEWAY를 도입하여 이 괴물을 고립시키고, 도메인 단위로 괴물의 feature를 조금씩 조금씩 떼어내기로 결정했습니다.
자~ 이제부터 본격적으로 API GATEWAY 적용기를 시작하겠습니다.
출처 - https://www.facebook.com/75911537320/photos/a.10151028112312321.423930.75911537320/10154488365657321/?type=3&theater
1. API GATEWAY이란?
Microservice Architecture(이하 MSA)에서 언급되는 컴포넌트 중 하나이며, 모든 클라이언트 요청에 대한 end point를 통합하는 서버이다. 마치 프록시 서버처럼 동작한다. 그리고 인증 및 권한, 모니터링, logging 등 추가적인 기능이 있다. 모든 비지니스 로직이 하나의 서버에 존재하는 Monolithic Architecture와 달리 MSA는 도메인별 데이터를 저장하고 도메인별로 하나 이상의 서버가 따로 존재한다. 한 서비스에 한개 이상의 서버가 존재하기 때문에 이 서비스를 사용하는 클라이언트 입장에서는 다수의 end point가 생기게 되며, end point를 변경이 일어났을때, 관리하기가 힘들다. 그래서 MSA 환경에서 서비스에 대한 도메인인 하나로 통합할 수 있는 API GATEWAY가 필요한 것이다.
API GATEWAY를 도입하기 위해서 먼저 오픈소스를 찾아보았다. KONG, API Umbrella 등이 있었다. 별다른 고민은 없었다. 선택은 Netflix였다. 이유는 JAVA 프로젝트이며, 세계적으로 MSA를 가장 잘하고 있는 서비스이다. 무엇보다 Martinfowler 아저씨가 정의한 MSA환경, MSA에서의 문제점을 충분히 고려하여 설계된 모든 컴포넌트를 오픈소스화 하였기때문이다. 한마디로 Netflix가 잘 닦아놓은 길을 우리는 그대로 걸으면 된다. 물론 서비스가 다르고, 상황이 다르다. 우린 다만 필요한 것을 선택해서 취하면 된다.
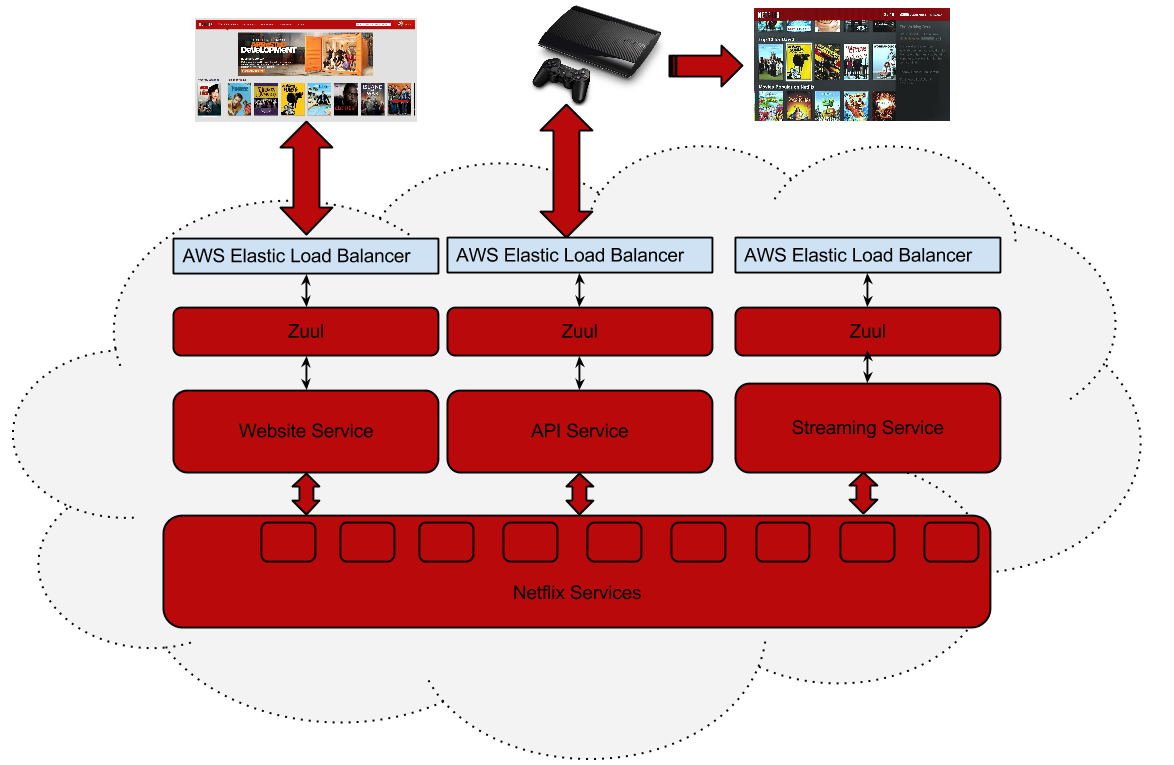
2. Netflix Zuul이란?
Zuul is the front door for all requests from devices and web sites to the backend of
the Netflix streaming application. As an edge service application, Zuul is built to enable
dynamic routing, monitoring, resiliency and security. It also has the ability to route requests
to multiple Amazon Auto Scaling Groups as appropriate.
Netflix wki에 위와 같이 정의하고 있다.
한마디로 Netflix 사용하고 있는 API GATEWAY이다.
출처 - https://github.com/Netflix/zuul/wiki
1) 왜 Netflix에서는 Zuul을 사용하나?
클라이언트 요청은 많은 트래픽과 다양한 형태(예상하지 못한 형태)의 요청으로 경고없이 운영에 이슈를 발생시킨다. 이러한 상황에 신속히 대응할 수 있는 시스템 zuul을 개발하였다. zuul은 이런한 문제를 신속하고, 동적으로 해결하기 위해서 groovy 언어로 작성된 다양한 형태의 Filter를 실행한다. Filter에 기능을 정의하고, 이슈사항에 발생시 적절한 filter을 추가함으로써 이슈사항을 대비할 수 있다.
2) Netflix Filter의 기능
- Authentication and Security
- 클라이언트 요청시, 각 리소스에 대한 인증 요구 사항을 식별하고 이를 만족시키지 않는 요청은 거부
- Insights and Monitoring
- 의미있는 데이터 및 통계 제공
- Dynamic Routing
- 필요에 따라 요청을 다른 클러스터로 동적으로 라우팅
- Stress Testing
- 성능 측정을 위해 점차적으로 클러스터 트래픽을 증가
- Load Shedding
- 각 유형의 요청에 대해 용량을 할당하고, 초과하는 요청은 제한
- Static Response handling
- 클러스터에서 오는 응답을 대신하여 API GATEWAY에서 응답 처리
출처 - https://medium.com/netflix-techblog/announcing-zuul-edge-service-in-the-cloud-ab3af5be08ee
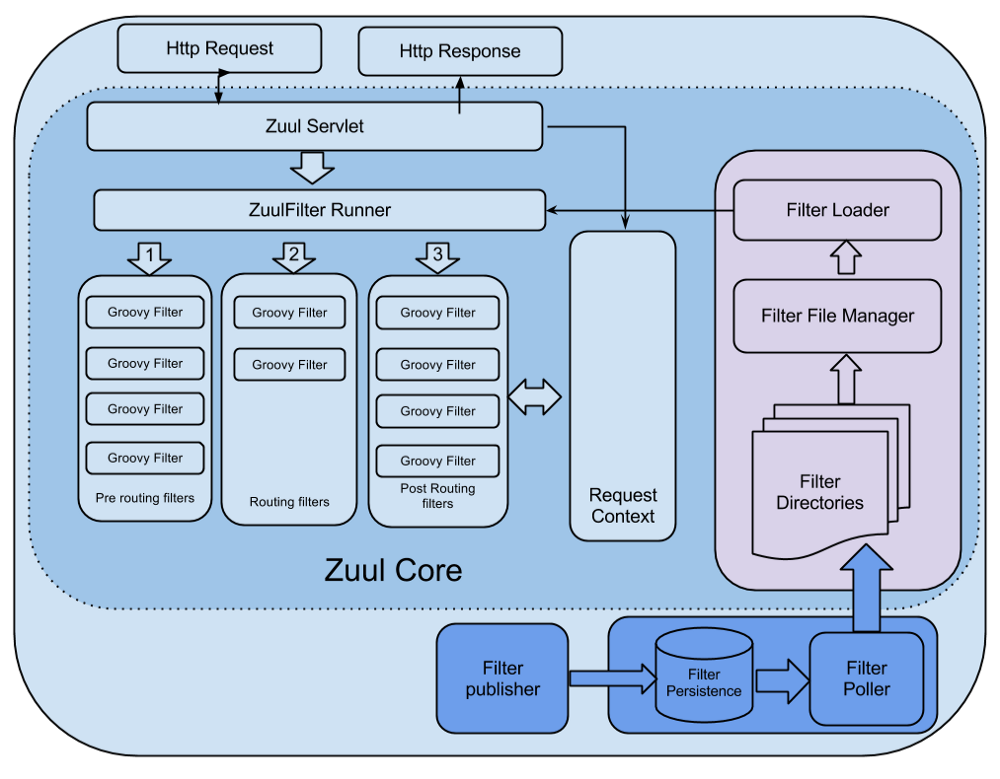
내 생각에는 위 그림이 zuul 시스템을 가장 이해하기 좋은 그림 같다.
- Filter File Manager에서는 일정 주기(정해진 시간) 마다 정해진 directory에서 groovy로 정의된 filter 파일을 가져온다.
- javax.servlet.http.HttpServlet을 상속받아서 ZuulServlet을 제정의 하였고, request 요청이 들어 올때마다 아래와 같이 preRoute(), route(), postRoute()에서 ZuulFilter Runner를 실행한다.
- ZuulFilter Runner는 Filter에 정의된 기능을 실행한다.
- 기본적으로 Filter은 다른 Filter들과 직접적으로 통신할 수 없다. 그래서 각각의 요청별로 RequestContext를 공유(마치 thread local같이)하여 통신 할 수 있다.
@Override
public void service(javax.servlet.ServletRequest servletRequest, javax.servlet.ServletResponse servletResponse) throws ServletException, IOException {
try {
init((HttpServletRequest) servletRequest, (HttpServletResponse) servletResponse);
// Marks this request as having passed through the "Zuul engine", as opposed to servlets
// explicitly bound in web.xml, for which requests will not have the same data attached
RequestContext context = RequestContext.getCurrentContext();
context.setZuulEngineRan();
try {
preRoute();
} catch (ZuulException e) {
error(e);
postRoute();
return;
}
try {
route();
} catch (ZuulException e) {
error(e);
postRoute();
return;
}
try {
postRoute();
} catch (ZuulException e) {
error(e);
return;
}
} catch (Throwable e) {
error(new ZuulException(e, 500, "UNHANDLED_EXCEPTION_" + e.getClass().getName()));
} finally {
RequestContext.getCurrentContext().unset();
}
}
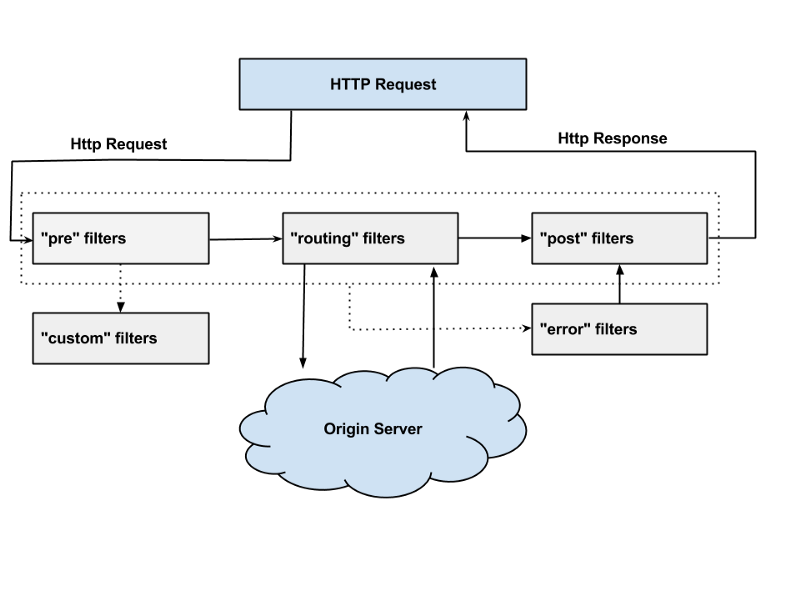
3) Zuul Filter
Zuul Filter는 크게 4가지 Filter로 나누어 진다.
- PRE Filter - 라우팅전에 실행되며 필터이다. 주로 logging, 인증등이 pre Filter에서 이루어 진다.
- ROUTING Filter - 요청에 대한 라우팅을 다루는 필터이다. Apache httpclient를 사용하여 정해진 Url로 보낼수 있고, Neflix Ribbon을 사용하여 동적으로 라우팅 할 수도 있다.
- POST Filter - 라우팅 후에 실행되는 필터이다. response에 HTTP header를 추가하거나, response에 대한 응답속도, Status Code, 등 응답에 대한 statistics and metrics을 수집한다.
- ERROR Filter - 에러 발생시 실행되는 필터이다.
출처 - https://medium.com/netflix-techblog/announcing-zuul-edge-service-in-the-cloud-ab3af5be08ee
위와 같이 요청이 들어면 PRE Filter를 실행하고, ROUTING Filter에 의해 원하는 서버로 요청을 보낸다. 원하는 서버에서 응답이 오면 POST Filter를 실행시킨다.
4) Zuul Components
zuul은 zuul-core, zuul-simple-webapp, zuul-netflix, zuul-netflix-webapp 4개의 컨포넌트로 구성한다.
- zuul-core : 위에서 설명한 Zuul의 Request Lifecycle를 담당하고, Fliter를 컴파일하고 실행한는 기능을 담당하고 있는 Zuul의 core library
- zuul-netflix : 기본적은 Zuul에 NetflixOSS library를 추가한다.
- zuul-simple-webapp : zuul-core만 사용한 아주 기본적은 web application
- zuul-netflix-webapp : zuul-core와 zuul-netflix를 함께 사용한 web application
API GATEWAY를 구축하기 위해서는 zuul-simple-webapp를 사용하다는 것은 MSA 환경에서 아주 유용한 NetflixOSS library를 포기하는 것이다. zuul-netflix-webapp을 도입하기에는 학습곡선이 크다. 그래서 찾은게 spring cloud netflix 프로젝트이다.
3. Spring cloud Netflix
spring boot에 NetflixOSS를 통합적으로 제공한다. annotation과 yml설정 만으로도 아주 쉽게 NetflixOSS를 사용할 수 있다.
1) Spring cloud Zuul
spring boot 프로젝트에 artifact id spring-cloud-starter-zuul를 추가하고 main class에 @EnableZuulProxy또는 @EnableZuulServer라고 명시해주면 zuul 서버가 구축된다.
@EnableZuulProxy
@SpringBootApplication
public class ApigatewayApplication {
}
zuul-core의 ZuulServlet을 그대로 사용하여, 아래 그림과 같이 spring MVC 위에서 동작하기 위해 몇가지를 추가하였다.
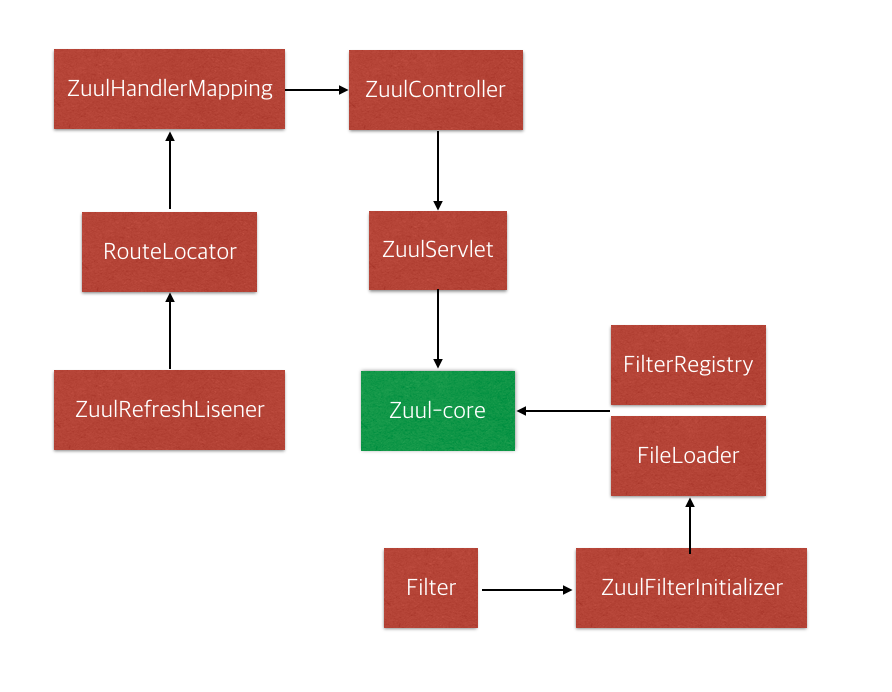
- RouteLocator은 url path에 대한 routing을 지정한다. 요청이 들어오면 url path로 어떻게 routing 할 것인가를 정의하고 있다.
- ZuulHandlerMapping은 org.springframework.web.servlet.handler.AbstractUrlHandlerMapping을 상속받고, RouteLocator에 정의된 url path에 zuulController를 매핑한다. RouteLocator에 정의된 path의 요청이 들어오면 zuulController를 호출하게 된다.
- ZuulController은 org.springframework.web.servlet.mvc.ServletWrappingController를 상속받으며, ZuulServlet을 주입시킨다. 그래서 ZuulController로 들어온 모든 요청은 ZuulServlet으로 처리한다.
- ZuulFilterInitializer는 filter Map에 정의된 filter를 FilterRegistry에 등록하고, FilterLoader로 로딩한다.
Spring Cloud Zuul은 @EnableZuulProxy와 @EnableZuulServer 두 종류의 annotation으로 Zuul을 구동시킨다. 두개는 완전히 다른 것이 아니고 @EnableZuulProxy가 @EnableZuulServer을 포함한다. @EnableZuulServer에서 PreDecorationFilter, RibbonRoutingFilter, SimpleHostRoutingFilter를 추가하면, @EnableZuulProxy가 되는 것이다.
더 자세한 설명은 http://cloud.spring.io/spring-cloud-netflix/spring-cloud-netflix.html에 있고, 더 완벽한 설명은 소스를 보면 된다. 소스가 그렇게 많지 않아 같이보길 권장한다.
여기까지 Spring Cloud Zuul에 대한 설명였다.
자, 이제부터 우리팀에서 API GATEWAY를 어떻게 적용했는지 설명하겠다.
4. 배민 LEGACY API System Architecture
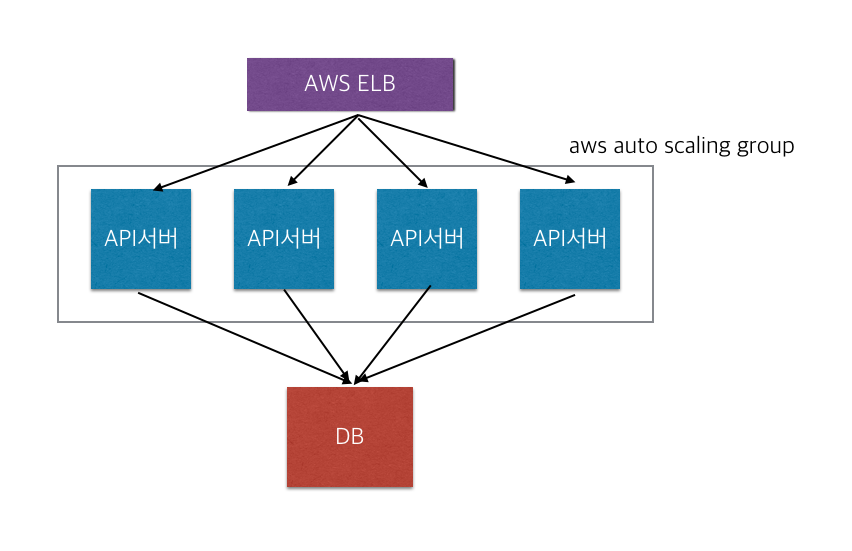
흔히 보는 그림이다. Monolithic Architecture의 전형적인 구조이다. 우리 배민 API 서버의 대략적인 현재 모습이다. 다행인것은 Amazon Web Service(이하 AWS) 에 올라가 있고, auto scaling group에 묶여있어 그나마 운영하기가 편하다. 그러나 DB쪽 도메인 분리가 더 필요한 상황이다.
현재는 Monolithic Architecture 단점을 그대로 가지고 운영하고 있다.
- 조금만 수정을 해도 전체를 배포해야 된다.
- 서비스를 유연하게 가져가기 힘들다.
우린 현재 MSA가 필요한 상황이 온 것 같다. 아마 몇년 전 부터 필요한 상황인지도…
그런데 한번에 LEGACY 서버를 도메인별로 분리하다는 것은 엄청난 위험과 개발비용이 필요하다. 도메인별로 디비 분리하고 스키마를 재정의하고 마이그레이션을 완료했는데, 스키마 정의가 잘못 되거나 데이터 정합성이 깨졌다면 서비스는 완전 망가질수도 있다.
그래서 우린 LEGACY 서버를 고립시키고 도메인별로 하나씩 분리하는 작업을 진행하야겠다는 판단을 했다. 그런데 도메인을 분리하면 몇가지 문제점이 생긴다.
- 도메인을 분리하면 서비스별로 서버가 많이 생길 것이고, 서비스별로 URL이 또한 많이 생길 것이다. 그렇다면, 기능별로 URL을 관리하는 것이 필요하다.
- 기존 클라이언트 요청은 모두 예전 LEGACY 서버의 URL를 호출한다.
그래서 우리는 이런 문제를 해결하기 위해서 API GATEWAY 도입하였다. API GATEWAY가 PATH에 대한 Routing을 관리하면, 모든 클라이언트들은 하나의 URL를 보면 된다.
5. 배민 API GATEWAY
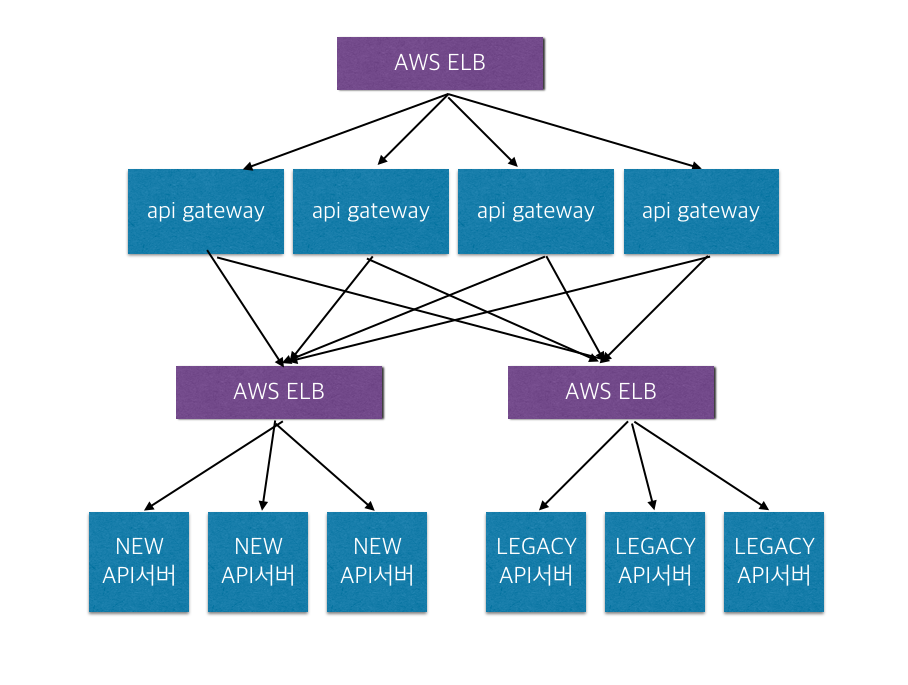
위 그림과 같이 API 서버를 설계하였다. 기존 API 서버에 사용했던 ELB에 API GATEWAY를 구성했고,
두 개의 ELB를 더 생성하여, 하나의 ELB에는 기존 LEGACY API 서버를 구성하였고, 또 하나의 ELB에는 새로운
API 서버(특정 도메인)로 구성하였다. 앞으로 도메인 늘어날 때 마다 ELB는 더 늘어날 예정이다.
클라이언트에서 들어오는 요청을 API GATEWAY에서 구분하여 새로운 API서버와 LEGACY API서버로 라우팅을 한다.
라우팅 기준을 URL PATH이다.
zuul:
routes:
baeminApiService:
path: info/notice/**
url: http://baeminservice-new-api.com/v1/notice
baeminLegacyApiService:
path: /**
url: http://baeminservice-legacy-api.com
위와 같이 예와 같이 http://www.test.com/info/notice라는 요청이 들어오면, 새로 만들어진 API 서버의 /v1/notice PATH로 라우팅 한다. 나머지는 원래 LEGACY API 서버로 라우팅된다. 이런식으로 새로운 API가 만들어질때 마다 location을 명시해준다.
왜 Eureka를 사용하여 serviceId로 라우팅하지 않았나?
- Eureka 서버의 운영 및 관리 비용이 필요하다. - 가장 큰 이유다.
- 서버 배포 시스템이 변경되어야 된다. 기존에는 ELB에서 서버를 뺀 후 배포하고 배포 완료되면 ELB에 붙였는데 Eureka를 사용하면 변경되어야 된다.
- 아직까지는 Eureka를 사용 할 만큼 서버 리스트가 많지않다
- ELB를 사용했을때 응답시간를 비교했는데 별로 차이가 없었다.(5ms 이내)
아직 Eureka 도입 시기는 아니라고 판단된다. 시스템은 필요에 의해 변경되어야 된다. 우선 LEGACY API 개선이 먼저이다. 도메인이 늘어나고, 서버 리스트가 늘어나면 그때 필요에 의해 Eureka를 도입할 것이다. 지금 당장 필요한 것은 API GATEWAY이다.
Zuul은 Filter를 실행하는 Application이다. Filter를 추가함으로써 자신만의 API GATEWAY를 만들 수 있다. Spring Cloud Zuul은 Filter를 @Bean으로 설정할 수도 있다. 이때는 JAVA언어로 Filter를 정의하고 정적으로만 사용가능하다. 실시간으로 이슈 대응해야 되는 API GATEWAY에서는 뭔가 부족하다. 그래서 동적으로 Filter를 정의하기 위해서 FilterFileManager를 사용했다. 아래와 같이 FilterFileManager에 Filter file 디렉토리를 지정해주면 Netflix Zuul처럼 지정 디렉토리에 있는 파일을 일정주기로 읽어오고 파일을 수정하면 런타임에도 반영가능하다.
@Component
public static class ZuulFilterCommandLineRunner implements CommandLineRunner {
@Value("${baemin.zuul.filters.base-path}")
private String filterBasePath;
@Override
public void run(String... args) throws Exception {
FilterLoader.getInstance().setCompiler(new GroovyCompiler());
try {
FilterFileManager.setFilenameFilter(new GroovyFileFilter());
FilterFileManager.init(1, this.filterBasePath + "pre", this.filterBasePath + "route", this.filterBasePath + "post");
} catch (Exception e) {
throw new RuntimeException(e);
}
}
}
끝으로
지금까지 API GATEWAY를 왜 구성했으며, 어떻게 구성했는지에 대해서 이야기했다. 아직까지는 MSA로 가기 위한 초기단계이다. 앞으로 필요에 따라 Eureka, Archaius 등을 구축해야 되고, API GATEWAY의 FIlter도 추가해야 된다. 무엇보다 도메인 분리가 시급하다. 도메인별로 서비스가 분리되면, 이에 따른 많은 문제(배포, CircuitBreaker, 모니터링 등)가 발생할 것이다. 이 문제들은 Netflix OSS의 모범 해법을 보고 하나씩 하나씩 문제를 풀면 될 것 같다. ribbon, hystrix, servo등… 기회가 된다면, MSA의 컴포넌트들을 도입할 때 마다 소개하고 싶다.