안정된 의존관계 원칙과 안정된 추상화 원칙에 대하여
• 손권남

Robert C. Martin의 Agile Software Development - Principles, Patterns, and Practices 에서 SDP, SAP 를 정리해보았습니다.
이 글은 기본적으로는 Java와 Spring Framework 기반(혹은 이와 유사한 계층형 방식)으로 개발하시는 개발자분들을 대상으로 합니다.
개발을 하면서 어떨 때는 interface를 만들고 어떨때는 안 만드는지 혹시 규칙이 있는 것인 아닌지 궁금할 때가 있습니다.
특히 Controller 패키지, Service 패키지, Repository 패키지의 기본 계층으로 개발을 할 때 많이 제기되는 문제이면서 항상 마지막엔 “정답은 취향따라”로 결론지으며 끝나는 논의 중에 “Service는 interface를 뽑아내고 구현해야하는지에 대한 고민”이 있습니다.
그러다가 Robert C. Martin 의 Agile Software Development - Principles, Patterns, and Practices 에 “20장 패키지 설계의 원칙”에 나온 내용을 읽다보니 아 이부분을 통해서 interface 사용 여부를 결정하는 것도 가능하겠구나 라는 생각이들어서, 이를 제 나름대로 이해하고 정리하며, 개인 의견을 덧 붙인 것입니다. 책의 내용 요약과 제 개인 의견이 혼재되어 있으니 주의해서 봐주세요.
해당 장에서 두가지 부분 Stable Dependencies Principle(안정된 의존관계 원칙)과 Stable Abstraction Principle(안정된 추상화 원칙)에 대한 정리가 이 글의 핵심입니다. Controller-Service-Repository 레이어는 비교 예제일 뿐 이 원칙들이 유일하게 적용되는 대상은 아닙니다.
먼저 패키지에서 안정성이 의미하는 바를 알아보고 안정적인 패키지는 어떻게 추상적이어야 하는지 살펴보겠습니다.
안정된 의존 관계 원칙 (Stable Dependencies Principle, SDP)
“20장 패키지 설계의 원칙”을 보면 Stable Depencies Principle은 간단히 “의존은 안정적인 쪽으로 향해야 한다.”라는 것을 뜻합니다.
소프트웨어 설계는 정적일 수 없습니다. 유지보수를 하려면 변화는 필연적입니다. 안정된 의존 관계 원칙을 통해 쉽게 변할 수 있는 패키지를 만들 수 있습니다. 이 패키지는 변화할 것을 예상하고 있습니다. 이렇게 쉽게 바뀔 것이라고 예상되는 패키지들은 바뀌기 어려운 패키지의 의존 대상이 되어서는 안됩니다.
쉽게 바뀔 수 있는 모듈에 무언가가 의존하기 시작하면 금세 이 모듈은 변경하기 어렵게 됩니다. 클래스 다이어그램을 그릴 때 불안정한 것을 위로 안정적인 것을 아래로 두는 습관을 가지면 그 방향이 바뀌었을 때 문제를 알기 쉽습니다.
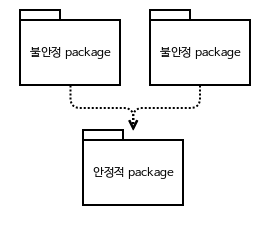
안정성이란?
소프트웨어 패키지를 변경하기 힘들도록 만드는 한 가지 확실한 방법은 바로 다른 많은 소프트웨어 패키지가 그 패키지에 의존하게 만드는 것입니다. 의존해 오는 패키지들이 많은 패키지는 변경한 내용이 의존하는 모두를 만족시키려면 매우 많은 일이 필요하므로 매우 안정적이라고 말합니다.
패키지의 안정성 측정
안정성은 패키지에 의존하는 수와 패키지가 의존하는 수를 통해 측정할 수 있습니다.
불안정성 = 패키지 외부 클래스에 의존하는 패키지 내부 클래스의 수 / (이 패키지에 의존하는 외부 클래스의 수 + 패키지 외부 클래스에 의존하는 패키지 내부 클래스의 수)
불안정성이 1 이면 이 패키지에 의존하는 다른 패키지가 없다는 의미 입니다. 이는 최고로 책임을 지지 않고 의존적이며 불안정합니다. 불안정성이 0 이면 이 패키지는 책임을 지며 독립적이며 안정적입니다. 이 패키지에 의존하는 다른 요소가 많기 때문에 함부로 변경하기 어려우며 다른 것에 의존하지 않으므로 자신의 의존성에 의해 변경될 가능성도 적습니다.
안정된 의존관계 원칙에 따르면 어떤 패키지의 불안정성 측정값은 그 패키지가 의존하는 다른 패키지들의 불안정성 값들보다 반드시 커야 합니다(즉, 의존 관계의 방향으로 불안정성 측정값이 줄어들어야 합니다).
Controller -> Service -> Repository 의 안정성
자 이제 생각해 봅시다.
Controller 는 일반적으로 Service와 Repository에 의존합니다. 하지만 일반적으로 Controller 코드를 사용하는 다른 코드는 존재하지 않습니다.
Controller가 10개가 있고 이들 모두 Service, Repository에 의존하지만 어느 것도 Controller에 의존하지 않는다고 했을 때
Controller의 불안정성 = 10 / (0 + 10) = 1 이 됩니다. 최고로 불안정하게 됩니다.
이제 Service를 보면 Repository에 의존하는 Service가 10개가 있고, 이 Service들에 20개의 Controller들이 의존한다고 하면
Service의 불안정성 = 10 / (20 + 10) = 0.333 이 됩니다. 약간 안정적입니다.
이제 Repository를 보면 Repository 자체는 우리가 직접 만든 다른 계층에 의존하지 않고(0) 이 Repository에 의존하는 Service들과 Controller들이 20개가 있다면
Repository의 불안정성 = 0 / (20 + 0) = 0 이 됩니다. 최고로 안정적이게 됩니다.
즉, 의존간계의 방향으로 Controller (1) -> Service (0.333) -> Repository (0) 불안정성 값이 줄어들게 됩니다.
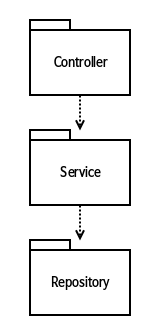
이것을 보면 안정된 의존 관계원칙으로 봤을 때 Repository는 절대로 Service나 Controller에 의존하면 안 됨을 알 수 있습니다. 마찬가지로 Service도 Controller에 있는 코드를 호출해서는 안됩니다. 그렇다면 이런 안정적인 설계가 필요한 코드는 설계의 유연성이 떨어지게 됩니다. 안정적이면서도 설계의 유연성을 높일 수 있는 방법은 무엇일까요?
바로 추상 클래스(abstract class)입니다.
안정된 추상화 원칙 (Stable Abstraction Principle)
패키지는 자신이 안정적인 만큼 추상적이기도 해야 한다.
안정된 추상화 원칙은 안정적인 패키지는 그 안정성 때문에 확장이 불가능하지 않도록 추상적이기도 해야하며, 거꾸로 이 원칙에 따르면 불안정한 패키지는 구체적이어야 하는데, 그 불안정성이 그 패키지 안의 구체적인 코드가 쉽게 변경될 수 있도록 허용하기 때문입니다.
따라서 어떤 패키지가 안정적이라면 확장할 수 있도록 추상 클래스들로 구성되어야 하며, 확장이 가능한 안정적인 패키지는 유연하며 따라서 설계를 지나치게 제약하지 않아야 합니다.
안정된 의존 관계 원칙은 의존관계의 방향이 안정성의 증가 방향과 같아야 한다고 말하고, 안정된 추상화 원칙은 안정성이란 추상성을 내포한다고 말하기 때문에 따라서 의존 관계는 추상성의 방향으로 흘러야 합니다.
이를 간단히 말하면
- Controller는 불안정하므로 추상적일 필요가 없다 -> Controller 클래스 interface를 만들고 구현하는 것은 무의미하다.
- Repository는 매우 안정적이므로 추상적이어야 한다 -> Repository는 interface를 만들고 구현하는 것이 좋다.
- 음? Service는?
패키지의 추상성 측정
추상성 = 패키지 안에 들어있는 추상 클래스 수(하나 이상의 순수한 인터페이스를 가지고 있으며 인스턴스화 할 수 없는 클래스) / 패키지 안에 들어있는 클래스 수
추상성은 0부터 1로 나올 수 있으며 0은 패키지에 추상 클래스가 하나도 없다는 뜻이고 1은 패키지에 추상 클래스 밖에 없다는 뜻입니다.
안정성과 추상성의 관계
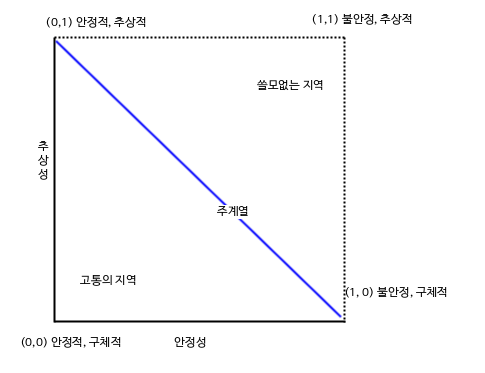
추상성과 안정성의 그래프를 위와 같이 그려볼 수 있습니다.
모든 클래스가 “(0,1) 안정적, 추상적” 위치나 혹은 “(1,0) 불안정, 구체적” 위치에 올 수는 없습니다. 여기서 가강 좋은 것은 위 그래프에서 “주계열” 부분에 위치하도록 코드를 만드는 것입니다.
그에 앞서 “쓸모없는 지역”과 “고통의 지역”은 무조건 배제하는 것이 좋습니다.
고통의 지역
(0,0) 안정적이고 구체적인 영역에 패키지가 있다고 해보면 추상적이지 않기 때문에 확장하기 어려운데 안정적이라서 변경하기도 함듭니다. 잘 설계된 패키지는 (0, 0) 위치에 오기 어렵습니다. 이 부분을 “고통의 지역”이라고 부릅니다.
하지만 고통의 지역에 있을 수 밖에 없는 경우도 있습니다. 데이터 베이스 스키마는 매우 구체적인데 이에 의존하는 코드도 무척이나 많은 안정적인 것입니다. 데이터베이스 스키마 변경이 고통스러운 이유중의 하나입니다.
그 외에 String 관련 클래스들이 있습니다. String 관련 클래스들은 매우 안정적으로 다른 수많은 코드가 의존하고 있는데 매우 구체적인 코드입니다. 하지만 문자열 코드는 변경의 가능성이 매우 적기 때문에 별로 해가 되지 않습니다.
여기서 봤을 때 정말 어쩔 수 없는 경우와, 변경 가능성이 0에 가까운 문자열, 유틸리티성 코드가 아니면 안정적이면서 구체적으로 만드는 행위는 피해야 함을 알 수 있습니다.
쓸모 없는 지역
(1, 1) 지역은 매우 추상적이면서도 불안정합니다. 불안정하다는 것은 이에 의존하는 다른 코드가 없음을 나타냅니다. 그런데 추상적이라는 것은 인터페이스를 만들고 구현했다고 보면 됩니다.
바로 Controller를 만들 때 인터페이스를 만들고 이를 구현하면 바로 이 부분 (1,1) 지역에 들어가게 됩니다. 이름 그대로 불안정한 Controller를 추상적으로 만드는 것은 매우 “쓸모 없는 행위”임을 알 수 있습니다.
이와 비슷한 것으로 Spring Batch의 Tasklet 같은 것이 있겠습니다. Tasklet 인터페이스 그 자체는 Sprig Framework가 Tasklet을 인식하기 위한 인터페이스이지 Tasklet 코드를 위한 인터페이스는 아닙니다. Tasklet은 Spring에 의해서만 호출되지 개발자가 직접 호출하지 않습니다. 즉 매우 불안정한 것인데, Tasklet에 별도의 인터페이스를 또 만들어서 구현하게 하는 것은 쓸모 없는 행위 임을 알 수 있습니다.
여기서 봤을 때 우리가 직접 사용하는 코드가 아닌 프레임워크에 의해 호출되는 코드는 프레임워크 규약을 따르기 위한 인터페이스를 제외하고는 별도의 인터페이스를 따로 빼서 구현할 필요가 없음을 알 수 있습니다.
우리는 고통의 지역과 쓸모 없는 지역은 항상 피하려고 노력해야 합니다. 물론 절대로 피할 수 없는 경우도 있습니다.
주계열
가장 바람직한 패키지는 주계열의 양끝 (0, 1) 안정적이고 추상적인 위치와 (1, 0)불안정하고 구체적인 위치이지만 대부분의 코드는 그 외 어딘가에 존재합니다. 그 중에서도 주계열이라고 표시된 지역에 있는 패키지는 “안정성에 비해 너무 추상적”이지도 않고, “추상성에 비해 너무 불안정적”이지도 않습니다. 즉, 쓸모 없지도 않고 특별히 고통스럽지도 않습니다. 자신이 추상적인 정도만큼 의존의 대상이 되며, 자신이 구체적인 정도만큼 다른 패키지에 의존합니다. 패키지를 주계열쪽에 위치하게 설계하는 것이 좋습니다.
주계열로 부터의 거리는 다음과 같이 측정합니다.
거리 = |추상성 + 불안정성 - 1|
이 결과는 절대값이므로 항상 0~1사이만 나오며, 거리가 0인 패키지는 주계열 바로 위에 있음을 의미합니다. 1은 가장 멀리 떨어져 있음을 뜻합니다.
이 주계열로 부터의 거리를 측정함으로써 예외적인 패키지들을 판변해 내고 이들을 조사해 보는 것이 좋습니다.
그래서 다시 Controller, Service, Repository는?
여기부터는 순전히 제 개인 의견만 기술합니다.
위에서 말한 Controller를 계산해보면 위에서 Controller의 불안정성을 1(불안정적)이라고 했고, Controller에 대해 전혀 인터페이스를 만들지 않을 것이므로 추상성은 0이 됩니다. 따라서,
Controller의 주계열로부터의 거리 = |Controller의 추상성 0 + Controller의 불안정성 1 - 1| = 0
0은 주계열 바로 위를 뜻하므로 좋습니다.
다시 위에서 말한 Repository를 계산해보면 위에서 Repository의 불안정성을 0(안정적)이라 했고, Repository는 항상 인터페이스를 구현하도록 했으므로 추상성은 1이 됩니다. 따라서,
Repository의 주계열로부터의 거리 = |Repository의 추상성 1 + Repository의 불안정성 0 - 1| = 0
마찬가지로 0은 주계열 바로 위를 뜻하므로 좋습니다.
그렇다면 Service는 어떨까요? 바로 상황에 따라 조사를 해봐야 한다는 의미가 됩니다.
해당 서비스의 안정성과 추상성을 측정해보면서 주계열에 가까운지를 지속적으로 살펴보면 됩니다. 하지만 몇가지 예를 살펴보도록 하겠습니다.
EmailService
대체로 우리가 웹서비스를 만들 때 Email 발송은 매우 많이 하게 됩니다. 최초의 시작은 SMTP 서버에 의존하겠지만 나중에는 DB에 메일 내용을 넣고 배치작업으로 메일을 보내거나 아니면 MQ를 통해 메일 내용을 전달하고 다른 프로그램에서 실제 메일 발송을 하게 하는 경우도 있는등 변동성이 매우 큰 것이 Email 발송입니다.
EmailService의 불안정성 = 패키지 외부 클래스에 의존하는 패키지 내부 클래스의 수(SMTP 의존 1) / (이 패키지에 의존하는 외부 클래스의 수 100여개의 이메일 호출 + 패키지 외부 클래스에 의존하는 패키지 내부 클래스의 수 SMTP 의존 1) = 1 / (100 + 1) = 0.009
불안정성 0.009라는 것은 정말 매우 안정적임을 의미합니다.
매우 안정적인데 추상성이 0이라면
주계열로부터의 거리 = |추상성 0 + 불안정성 0.009 - 1| = |-0.991| = 0.991
주계열로부터의 거리 0.991는 거의 1에 가깝다는 뜻으로 매우 멉니다. 문제가 있지요.
따라서 추상성을 1로 높이는 것이 좋습니다. 즉, 인터페이스를 구현해야 합니다.
EmailService를 인터페이스로 구현했다면 추상성이 1이 되어
|1 + 0.009 - 1| = 0.009
주계열로부터의 거리 0.009는 주계열에 매우 가깝다는 의미이므로 매우 좋습니다.
비즈니스 Service 예
Repository 5개를 호출해 그 결과를 조합해서 다른 결과를 도출하고, Controller 한 개에서만 사용되는 Service가 있다고 할 때 이를 일단 BusinessService라고 해보지요.
BusinessService의 불안정성 = 패키지 외부 클래스에 의존하는 패키지 내부 클래스의 수 Repository 의존 5 / (이 패키지에 의존하는 외부 클래스의 수 1개의 컨트롤러가 호출 + 패키지 외부 클래스에 의존하는 패키지 내부 클래스의 수 Repository 의존 5) = 5 / (1 + 5) = 0.83
불안정성 0.83은 매우 불안정함을 뜻합니다.
이 매우 불안정한 클래스를 추상적으로 만드는 것은 계산해보지 않아도 크게 의미가 없어 보입니다.
하지만 상황은 변하게 마련입니다. 시간이 지남에 따라 안정성이 변하고 그에 따라 필요한 추상성도 변할 수 있습니다.
그리고 원칙적으로 이 계산은 클래스 단위 보다는 패키지 단위입니다.
어떤 패키지 군에 속하느냐에 따라 어떤 Service는 추상적이어야 할 수도 있고 구체적이어야 할 수도 있습니다.
잠깐, 내가 생각하는 추상성이란?
이 책에서는 추상 클래스란 하나 이상의 순수한 인터페이스를 인스턴스화 할 수 없는 가진 클래스라고 합니다.
하지만 저는 여기에 또다른 한가지 규칙이 더 내포돼 있다고 생각합니다.
“인터페이스의 메소드 시그너쳐에 구현에 대한 정보가 없어야 한다” 라는 규칙입니다.
다시 EmailService로 돌아가서 아무리 EmailService 인터페이스를 만들고 그 구현을 EmailSerivceSmtpImpl 클래스로 만들었다해도 메소드 시그너쳐가 다음과 같다면 무의미합니다.
boolean sendEmail(String smtpHost, String username, String password,
String senderEmail, List<String> receiverEmail, String subject, String content);
위 코드를 보면 인터페이스 메소드 시그너처에 String smtpHost, String username, String password가 포함돼 있습니다. 이 파라미터들은 Email 발송을 SMTP로 구현한다고 가정할 때만 의미 있는 값들입니다.
인터페이스에서 그 구현이 SMTP 서버를 통해서 이메일을 발송해야 한다고 제약하고 있는 것입니다.
실제 이메일을 보내는 측에서는 그 구현이 SMTP이건 MQ로 다른 EMail 전송 서버에 쏴주건 DB에 메일 발송 관련 정보를 저장하건 상관이 없습니다. 호출자측에서 중요한 것은 그 뒤에 있는 발송자 이메일, 수신자 이메일, 제목, 내용 이것 뿐입니다.
따라서 Email을 발송하는게 목적인 인터페이스의 메소드 시그너쳐는 아래와 같이 구현의 상세에 대한 정보를 가지고 있어서는 안 됩니다.
boolean sendEmail(String senderEmail, List<String> receiverEmail, String subject, String content);
그래서 Service에 interface를 만들라는 것인가 말라는 것인가?
일단 두가지로 구분해 볼 수 있어보입니다.
인프라성 서비스와 Repository
Email 발송, Push, SMS 발송, Logging 등등 인프라성 코드는 거의 불안정성이 0에 가깝습니다(안정적). 호출자는 매우 많은데 그 자신이 의존하는 것은 별로 많지 않은 경우가 많습니다. 그러면서도 그 구현체는 시스템의 성장에 따라 바뀌기 쉽습니다(Email의 경우 SMTP → DB → MQ). 안정성이 높으면 변경 대응을 위해 추상적이어야 합니다.
따라서 인프라성 Service는 거의 무조건 interface를 구현해야 하며, 위에서 제가 말한 추상성의 의미 - 인터페이스의 메소드 시그너처에 구현에 구현의 상세를 포함하지 말 것 -을 지켜야 합니다.
Repository Layer도 마찬가지 입니다. 저는 과거에 “세상에 DB를 바꿀일이 뭐가 있다고 Repository를 인터페이스로 만들어?”라고 생각했었습니다. 하지만 지속적으로 성장하는 서비스를 맡아하면서 여러번 DB를 다른 DB 시스템 혹은 NoSQL 등으로 변경합니다. 그 뿐만 아니라 Persistence Framework도 바뀔 수 있습니다. 저는 얼마전까지 iBatis를 사용하던 프로젝트들을 JPA, QueryDSL, jOOQ 기반으로 변경하는 작업을 하기도 하였습니다. 이렇게 안정성이 높으면서 그 변경도 잦을 수 있는 Repository는 철저하게 추상적으로 만들기를 권합니다.
비즈니스 서비스
비즈니스 로직 서비스는 상황을 지켜봐야 할 것으로 생각됩니다. 처음부터 무작정 인터페이스를 만들면 복잡도만 높고 개발 효율은 떨어질 수 있습니다(쓸모없는 지역).
비즈니스의 성장에 따라 고통스러운 순간이 오거나 혹은 측정에 의해 인터페이스로 분리하는 작업을 해도 될 것 같습니다.
마무리
밥 아저씨(Robert C. Martin)는 다음과 같이 이 장을 마무리하십니다.
“측정값은 신이 아니다. 그것은 단지 임의로 만든 어떤 기준에 따라 측정해본 값일 뿐이다. 이 장에서 선택한 기준이 특정한 애플리케이션에만 적합하고, 다른 것에는 적합하지 않은 일도 분명히 일어날 수 있다.”
또한 이 글은 간략화를 위해 Controller, Service, Repository 계층을 빗대어 예로 들었지만, 코드 계층에 이 세가지만 있는 것은 결코 아닙니다. 기본적으로는 interface를 만드느냐 안마드느냐는 Controller/Service/Repository 계층화 개발과는 별개의 문제입니다.
또한 interface 구현의 필요성을 여기 나온 수식으로만 판단해서는 안 됩니다. 의존성 역전 원칙 등에 따라서 다각도로 고민이 필요합니다.
그리고 이 책의 내용은 기본적으로 패키지를 기준으로 하지만 저는 클래스 단위와 패키지 단위를 혼재해서 사용하였습니다. 책의 내용 전체를 정리한 것이 아닙니다. 빠진 부분도 있으니 책을 읽어주세요.
긴 글 읽어주셔서 감사합니다.