레거시 코드를 파괴하는 Vim 벽돌 깨기
• 이종립

혼돈! 파괴! Vim!
발단: 레거시를 들여다보던 어느 날
누군가 마음속에서 속삭이더군요.

그래서 정신 나간 Vim 플러그인을 하나 만들어 보았습니다.
플러그인을 설치한 다음 코딩하다 분노가 느껴지는 타임이 도래했을 때
:VimGameCodeBreak를 입력하면 해당 코드를 스테이지 삼아 벽돌 깨기 게임이 시작됩니다.
게임으로 박살 난 코드가 원본 파일에 저장되지는 않으니 와장창 다 때려 부수면 됩니다.
플레이가 귀찮으면 볼을 떨궈도 Life가 줄지 않는 GOD MODE를 켜고 사라져가는 코드를 구경해도 좋습니다.
와아! 파괴를 부르는 생산성 저하 도구 등장!
어떻게 개발했나
개발에는 대략 3주 정도 걸렸습니다.
본업이 게임 개발도 아니고 업무 시간에 코드를 파괴하며 놀 수는 없으니,
점심시간이나 퇴근 후에 시간을 내서 코드를 작성했으며 주말에도 틈틈이 컴퓨터 앞에 앉아있었어요.
사실은 작은 게임들을 만드는 걸 좋아해서 (취미라고 할 수도 있을 것 같습니다)
집에서는 계속 CodeBreak만 잡고 있었다고 할 수 있습니다.
이 때까지만 해도 여흥으로 만든 이 게임이 흥하게 될 줄은 아무도 몰랐습니다….
아무튼, 성격상 프로토타입을 빠르게 만들고 뒤이어 리팩토링하는 방식을 선호하여 다음과 같이 작업했습니다.
- 구색 갖추기
- 기능 추가
- 디버깅
- 리팩토링
- GOTO 2
만드는 도중에 몇 가지 까다로운 문제들을 마주하고 어렵사리 해결하기도 했습니다.
여러 가지 재미있는 문제들이 있었지만… 특히 다음의 세 문제가 기억에 많이 남습니다.
- Vimscript 코드 가독성 문제
- 주로 syntax highlight 때문에 발생한 퍼포먼스 저하 문제
- multibyte 문자 길이 문제
1. Vimscript 코드 가독성 문제
Vimscript는 VimL이라고도 부르며 일반적으로는 Vim plugin 제작을 위해 작성되고 Vim 내에서만 돌아가는 DSL 입니다.
Python이나 Perl이 떠오르는 특징들이 보이기도 하지만 곰곰이 살펴보면 두 언어의 이념을 따르는 언어가 아니란 것도 알 수 있습니다.
아마 C++나 Java와 같은 엄격한 언어들에 익숙한 분들께 이 언어는 지옥일 수 있을 겁니다.
예를 들어 다음의 코드는 축약의 차이만 있을 뿐 똑같은 세 함수를 정의합니다. 알아보기 힘든 코드를 짜는 데에는 환상적이겠죠.
" 주석은 이렇게 큰따옴표를 사용합니다
function! Foo()
vsplit " vertical split
endfunction
fun! Foo()
vs " vertical split
endf
funct! Foo()
vsp " vertical split
endfu
한편 List를 다루는 방식은 Python의 괴상한 친척 같은 느낌도 듭니다.
let mylist = [1, two, 3, 'four']
let last = mylist[-1] " 값은 four
let a = '12345'
echo a[0:2] " 결과는 123 이 나옵니다. Python이라면 12 가 나왔겠죠?
Vim 편집기 명령어의 특성상 상당수 명령어에 축약 표현이 있고 비슷한 문법을 가진 다른 대중적인 언어의 관용구와 차이점이 있으며, 테스트 코드를 작성하기에도 어려움이 많습니다(Vader.vim이라는 훌륭한 테스트 프레임워크가 있지만, 아직 공부를 못했어요).
아마 여기까지 읽어주신 분들이라면 가급적 멀리하고 싶은 언어로 생각하시겠네요. 하하하 ;ㅁ;
하지만 Vimscript는 Vim의 DSL인 만큼 익숙해질수록 나름의 편리함과 유쾌함을 느낄 수 있으며 답답한 만큼 무언가를 만들어냈을 때의 즐거움이 큰 편입니다. 제가 Vim을 좋아해서 그런 것도 있겠지만, Vim에서 작업하는 것은 대체로 게임같이 즐거운 일이죠.
아무튼, 완벽한 대안이 있는 것도 아니고, 테스트 코드 작성도 어려우므로 저는 Vim plugin 개발에서 가장 중요한 것은 가독성이라고 여기게 되었습니다. 외국의 다른 분들이 만든 멋진 Vim plugin 코드를 읽을 때도 가독성 때문에 어려움이 많았거든요. 따라서 다음과 같은 원칙을 생각하게 되었습니다.
- 가능한 한 축약하지 않는다. 단, Vim 명령어 중 관용적으로 많이 사용되는 것(s, g 등)은 예외로 한다.
- 함수 이름을 대충 짓지 않는다.
- 함수를 가능한 한 짧게 만들고 한 가지 기능만 하게 한다.
2. 퍼포먼스 저하 문제
다음은 개발을 시작한 지 일주일쯤 되었을 때의 프로토타입입니다.
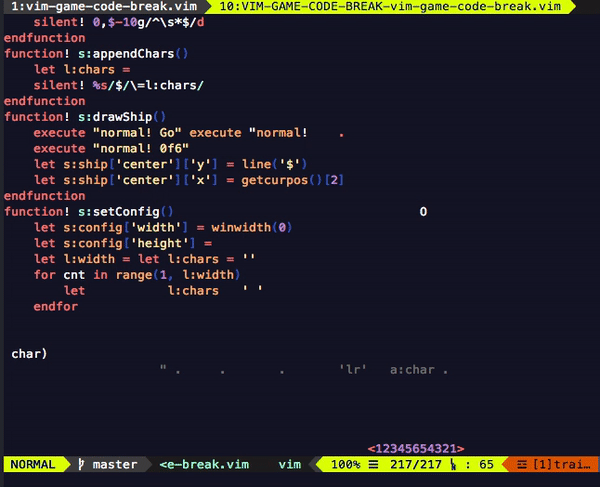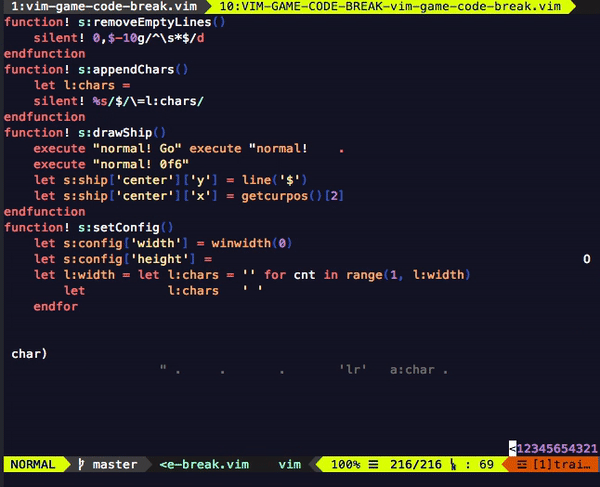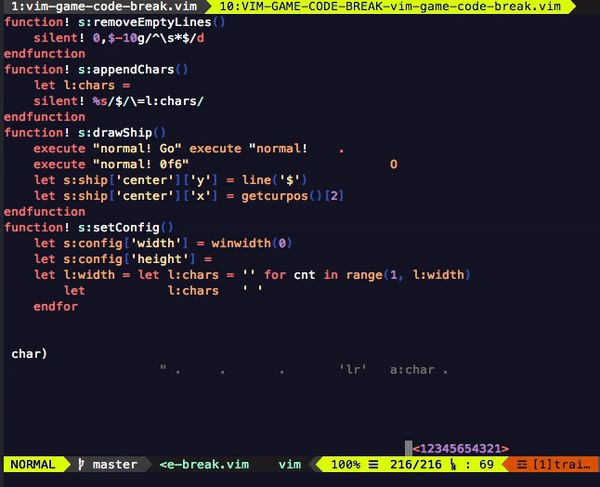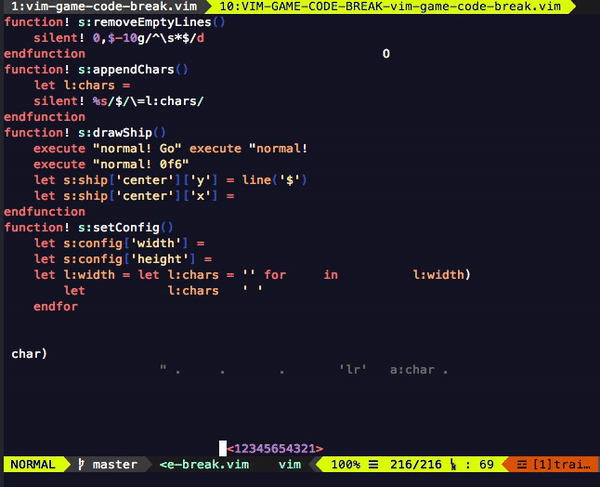
영상을 보면 다음과 같은 문제들을 발견할 수 있습니다.
- 공이 잠시 멈칫하는 순간이 있다.
- 플레이어가 조종하는 막대기 디자인이 구리다.
- 커서가 막대기를 따라다닌다.
이 세 문제는 각자 다른 카테고리에 속한 것처럼 보이지만, 속도 저하와 관련이 있다는 특징이 있습니다.
다음과 같은 방식으로 느려터진 속도를 다소 만회할 수 있었습니다.
- 짧은 시간 동안에 충돌 처리가 반복적으로 일어나면 느려진다.
- => 게임 전체를 관리하는 while 문 내에 있는 sleep 시간 조정
- 막대기에 원래 색깔이 나타나야 하는데 위쪽 코드가 망가지니 syntax highlight가 계획한 대로 나타나지 않는다.
- 게다가 막대기
<12345654321>가 코드에 포함되니 syntax color가 무너진다. - 계속 움직이는 막대기 때문에 syntax highlight redraw가 너무 빈번하게 발생한다!
- => 막대기를 status line으로 옮겨 syntax highlight의 영향을 받지 않게 한다.
- => 막대기 모양을 좀 더 단순하게
XXXXXXXXXXXXXXXXX로 변경 - => Vim help를 참고하여
regexpengine옵션을old로 변경.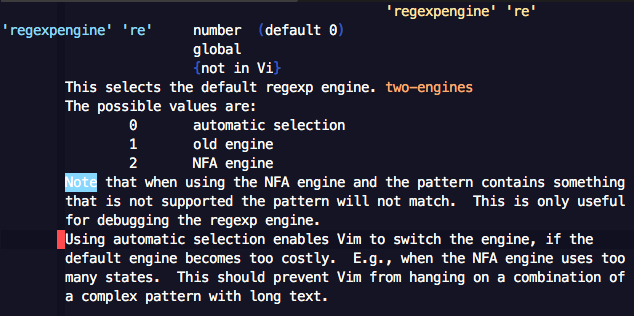
- 게다가 막대기
- 커서를 움직여 막대기를 그리고 있으므로 커서가 따라다니고 있다.
- => 될 수 있으면 커서를 사용하지 않고 화면을 갱신하도록 수정.
3. multibyte 문자 길이 문제
UTF-8에서 한글은 3 byte로 구성됩니다.
MARK 21 Specification의 Code Table Korean Hangul 표를 살펴보면 초성 중성 종성이 1 byte씩 차지하기 때문인 것을 알 수 있습니다.1
한편 Vim에서는 문자 위에 커서를 놓고 g8을 입력하면 다음과 같이 손쉽게 문자의 byte 값을 볼 수 있습니다.
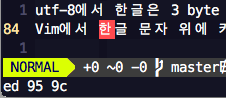
오 byte 단위로 작업할 일이 있다면 정말 편리하겠네요?
그런데 이것이 이 게임에서는 좀 짜증 나는 문제가 됩니다.
소스코드에 multibyte 문자로 주석이 달려 있을 때 공이 이상하게 움직이는 것을 발견했거든요.
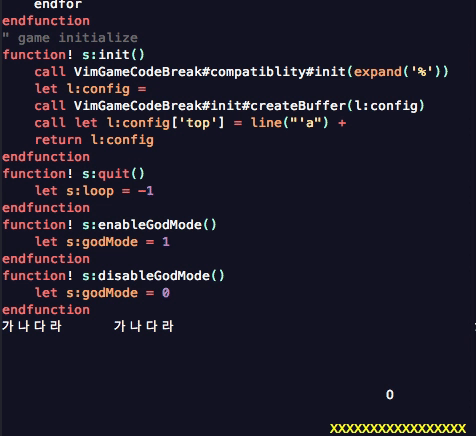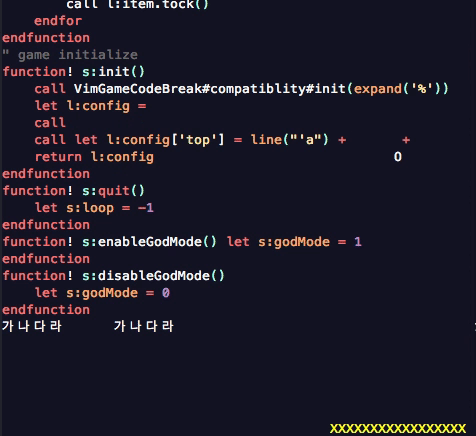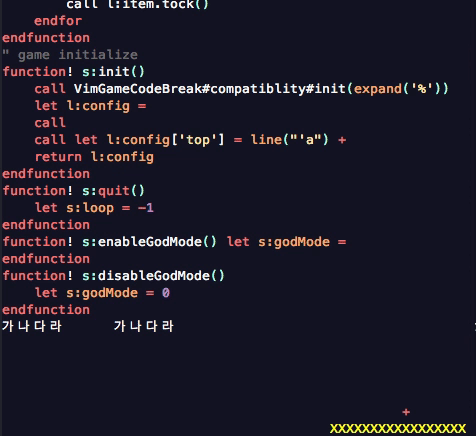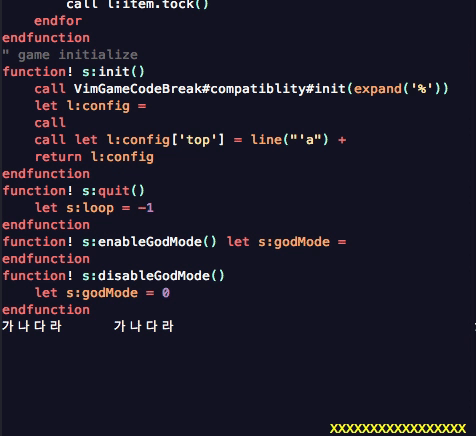
고의로 문제를 유발한 위의 gif 영상을 잘 살펴보면 공이 한글이 있는 라인을 지나갈 때 순간적으로 기대한 위치보다 왼쪽으로 점멸하는 것을 볼 수 있습니다. 이유를 이해하기 쉽게 관계된 사실들을 나열하자면 다음과 같습니다.
- Vim에서는 2 byte 이상의 multibyte 문자를 2 cursor column 사이즈로 보여줍니다(확실치는 않고 제가 모르는 설정이 있을 수 있습니다).
- 제가 작성한 공을 그리는 함수는 공의 미래 x 좌표를 참고하여 문자열을 자르고 공 문자를 끼운 다음 이어붙입니다.
- 문자열을 자를 때 문자열의 배열 인덱스를 기준으로 하는 방법을 사용했는데(깊게 생각하지 않은 결과), Vimscript에서 문자열의 배열 인덱스는 byte 단위입니다. 이로 인해 한글 한 글자를 이루는 3 byte 중 한 byte가 공으로 오염될 가능성이 생깁니다.
- Vimscript에서
cursor함수를 쓰면 커서가 byte 단위로 움직입니다. - Vimscript에서
execute "normal! l"로 커서를 움직여도 커서는 byte 단위로 움직입니다.
즉 한글이 왼쪽에 있다면, 최종적으로 표현된 공의 x 좌표 위치가 왜곡되어 보인다는 것입니다.
그뿐만 아니라 만약 공이 한글의 3 byte 중 영 좋지 못한 곳을 지나가면 2개의 byte 문자가 화면에 나타나기도 했습니다.
이 문제를 해결하기 위해서 머리를 싸매고 고민을 했습니다.
“라인별로 string 길이와 byte 길이를 비교해서 두 길이가 같지 않으면 multibyte 문자가 있다고 가정하고, 그 차이를 2로 나누면 multibyte 문자의 수가 나올 텐데… 아 이것만으로는 multibyte 문자의 위치를 확정할 수는 없구나. 임의의 x 값에 대해 왼쪽에 있는 multibyte 문자의 수를 구하는 것이 중요하니 라인별로 이진 탐색을 할까?”
그리고 진짜로 이진 탐색 코드를 작성하기 시작할 무렵…
이전까지 알지 못했던 Vim 명령어를 하나 알게 되었습니다.

아… |를 입력하면 l 처럼 움직이지만, 실제로는 screen column 기준으로 움직이는구나!
역시 매뉴얼을 잘 읽어야 고생을 덜 한다는 교훈을 얻고 |를 사용해 x 좌표 문제를 해결할 수 있었습니다.
Hacker News, Github Trending Today Developers에 오르다
위의 문제들까지 나름 무난하게 해결하고 나서는 개발이 다 끝났다고 생각했고 마무리 작업으로 돌입했습니다.
아직 이런저런 작은 문제들이 남아있긴 했지만, 천천히 해결하면 된다고 생각했거든요.
며칠 후 이 정도면 됐다는 생각이 들어 트위터에도 올리고 회사 동료들과 개발자 친구들에게 보여주며 신나게 놀았습니다.
그런데 팀 동료인 허승원 주임님이 이 게임을 해커 뉴스에 올려보면 어떻겠냐는 조언을 주시더군요.
별다른 생각 없이 해커 뉴스에 가입하고, CodeBreak의 Github 저장소 링크를 올렸습니다.
그런데 1~2시간 후 누가 트위터에서 제 저장소가 Hacker News 트위터에 떴다고 알려주길래 들어가서 봤더니 Hacker News 제일 윗자리에 제 글이 있었습니다. 그리고 저녁때쯤 되자 팀 동료인 남규진 님이 Github 트렌드에 제 저장소가 올라갔다고 알려주셨어요.
그리고 저장소에 별이 찍히기 시작했습니다.
다음 날 아침이 되자 pull request도 두 개나 들어와 있고 issue도 등록되어 새벽 다섯시에 일어나 pr을 검토하고 머지해주고 issue도 읽어보고 처리해주었습니다. 엄청난 행운이 다가온 느낌이었습니다.
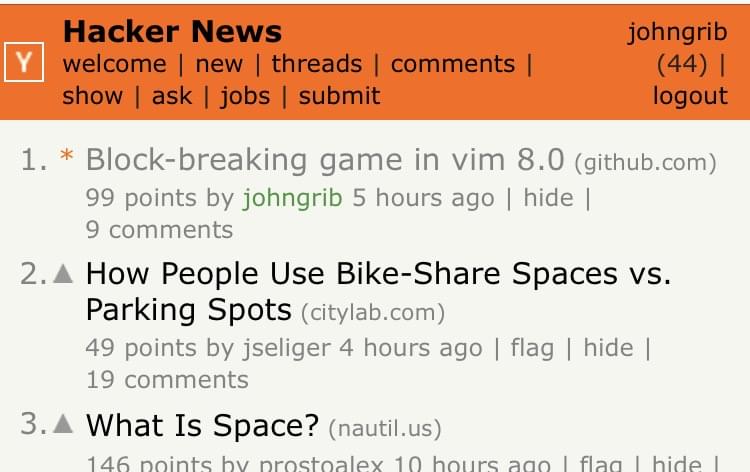
해커 뉴스 첫 번째 위치에 5시간 정도 올라가 있었습니다.
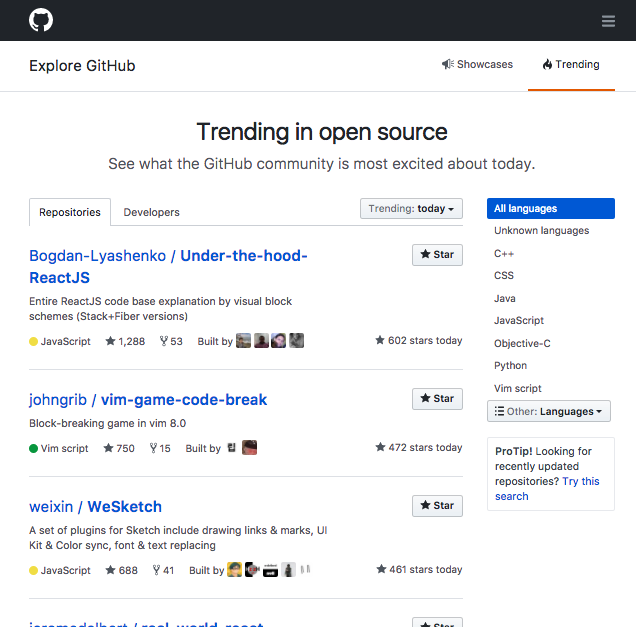
다음 날이 되자 Trending Repositories 순위도 올라서 2번 위치까지 올라갔습니다;;
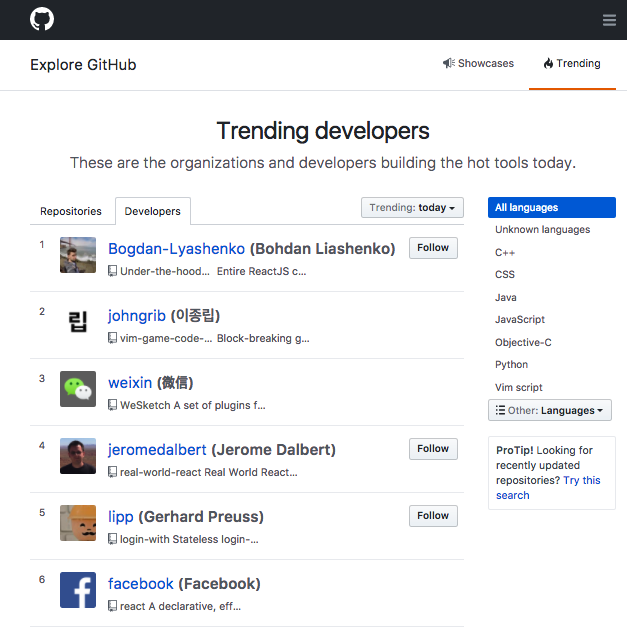
가문의 영광
이 글을 쓰고 있는 지금(이틀 후) 확인해보니 Github Star 가 910 개에 이르렀습니다. 광고 이메일이 오기도 하고, 트위터와 구글로 검색해보니 CodeBreak에 대해 대화하는 사람들의 글도 찾아볼 수 있었습니다. 대체로 웃고 즐거워하는 분위기의 글들이 많아 무척 기뻤고 많은 사람에게 재미를 준 것 같아 행복을 느끼고 있습니다. 아마 이런 즐거움도 소프트웨어 개발의 아름다운 측면이 아닐까 생각해 봅니다.
마지막으로 Reddit에서 CodeBreak에 대한 스레드를 하나 발견했는데 큰 감사와 부끄러움을 동시에 느끼게 하는 코멘트가 있었습니다.
rathrio: “This is absolutely amazing! I encourage everyone to skim over the code! It’s surprisingly readable Vimscript.”
rathrio님 감사합니다. 그리고 CodeBreak를 다운받은 분들과 이 글을 읽어주신 분들께도 감사를 드립니다.
부록 A : 링크, 출처 모음
- 엘론드: Destroy it! 짤림방지 이미지
- Vader.vim: Vim script test framework
- MARK 21 Specification: Code Table Korean Hangul
- Hacker News에 올린 글
- reddit: Block-breaking game in vim 8.0
부록 B
설치/실행 방법
- Vim 8.0 버전을 준비합니다. (이전 버전에서는 특정 함수들이 지원되지 않을 수 있습니다.)
- 플러그인 관리자를 사용하여 플러그인을 설치합니다.
- Vim을 재실행하거나 스크립트를 읽어들입니다.
- 스트레스를 풀고 싶은 소스코드 파일을 버퍼로 불러옵니다.
:VimGameCodeBreak를 입력하여 게임을 시작합니다.
게임 방법
- 알카노이드와 같은 일반적인 벽돌 깨기 게임 규칙을 따릅니다. 막대기로 낙하하는 공을 튕겨내고, 공이 코드를 때리면 코드가 사라집니다.
space키를 누르면 공을 출발시키고, 게임을 시작할 수 있습니다.h,l로 막대기를 좌우로 움직입니다.- 공이 막대기가 없는 바닥으로 떨어지게 되면 Life 점수가 감소합니다.
- 아이템을 먹으면 Life 점수가 회복되거나, 공이 추가된다던가, 막대기의 길이가 변화하는 등의 효과를 기대할 수 있습니다.
EOB
-
바로잡습니다. UTF-8에서 한글의 초성, 중성, 종성이 각각 1 byte 씩 차지한다는 것은 제 추측이었으며 잘못된 정보입니다.
Frank Hyunsok Oh님께서 첨부한 멘션을 인용합니다.
중간에 “초성 중성 종성이 1 byte씩 차지하기 때문”은 잘못된 정보같습니다. 한번 더 확인해 보시면 좋을것 같아요. 말씀하신 초중종성 분리 가능은 원래의 유니코드 한글 소리마디(Hangul Syllables) 코드포인트의 특징이고, 이를 인코딩한 UTF-8은 원래의 16비트 xxxxyyyyyyzzzzzz를 1110xxxx 10yyyyyy 10zzzzzz 처럼 인코딩합니다. 원래의 한글 소리마디 코드포인트에서는 ((초성 값 x 21) + 중성 값) x 28 + 종성 같은 형식으로 인코딩이 되어 있고요. ↩