도움이 될수도 있는 JVM memory leak 이야기
• 오민철

도움이 될지도 모르는 JVM memory leak 얘기인데 제목을 뭐라고 하지?
안녕하세요. 배민 플랫폼실 주문중계 시스템팀 오민철입니다.
이 글은 몇 줄의 코드와 어디서 걸렸는지 모를 dependency library로 발생한 memory leak에 관한 이야기입니다.
제목은 참 많이 고민했습니다. 사실 4월에 올리려고 했습니다. 그런데 제목을 지금까지 고민하다 저걸로 결정했습니다.
우리 팀의 역할은요.
먼저 우리 팀의 역할을 소개하겠습니다. 우리 팀은 주문이 발생하면 다양한 곳으로 중계를 합니다. 예를 들어 배민 앱에서 주문이 발생하면 가게 사장님에게 주문을 전달합니다. 이런 역할에 관련된 시스템을 관리하고 있습니다.
주문중계 api에 문제가 발생했어요.
12월 중순쯤 트래픽이 많지 않았으나 api 응답 지연이 발생했습니다. 응답이 느린 api의 코드를 살펴봤지만, 특이점을 찾을 수 없었습니다. 장애로 번지기 전에 해결하고자 환경 복제 후 트래픽을 새로운 서버로 이관했습니다. 하지만 api 응답 지연이 재발하여 서버와 pinpoint를 자세히 살펴보게 되었습니다.
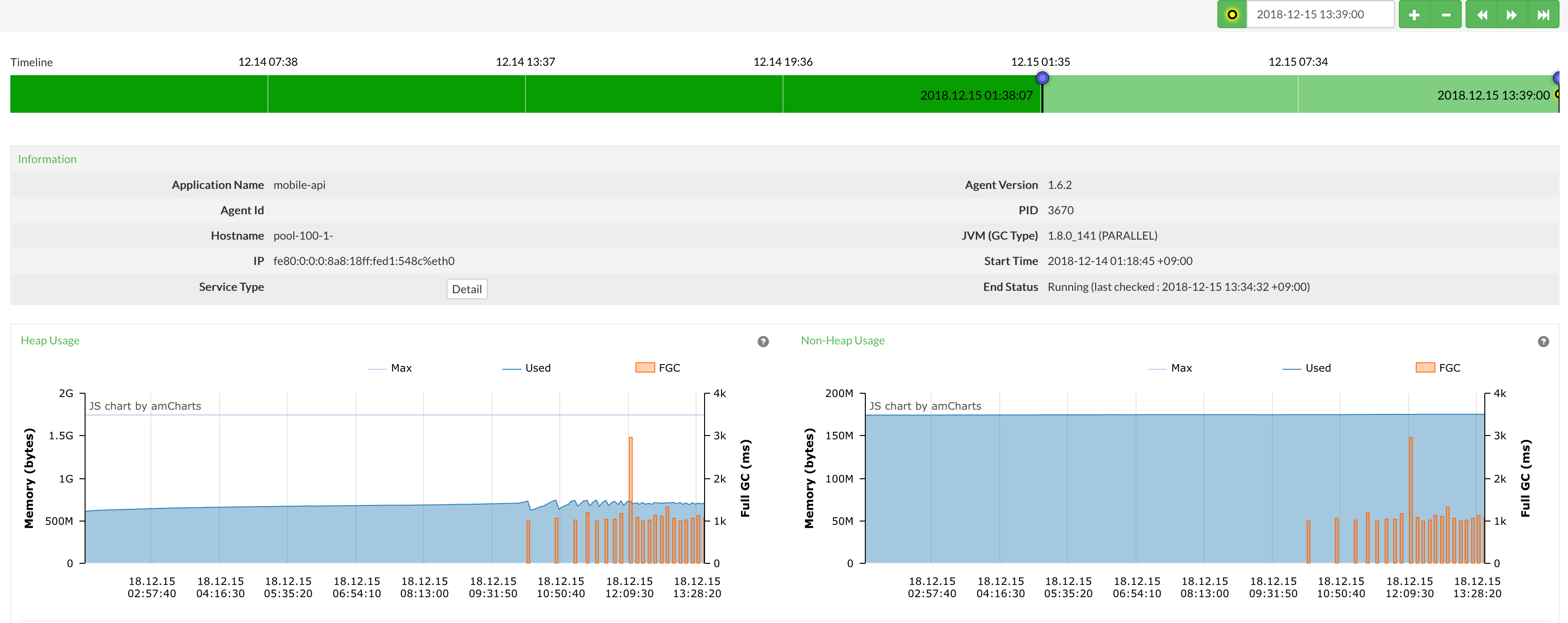
이건 memory leak이 분명해요.
FullGC 가 계속 발생하지만 heap memory의 변화가 없었습니다. 이런 현상은 memory leak 이 발생한다는 의미인데 주문중계 api는 이전에도 운영 중이었고, 동일한 현상이 발생하지 않았던 서비스여서 무엇이 문제인지 알 수 없어 이전에 발생 여부를 확인해봤습니다.
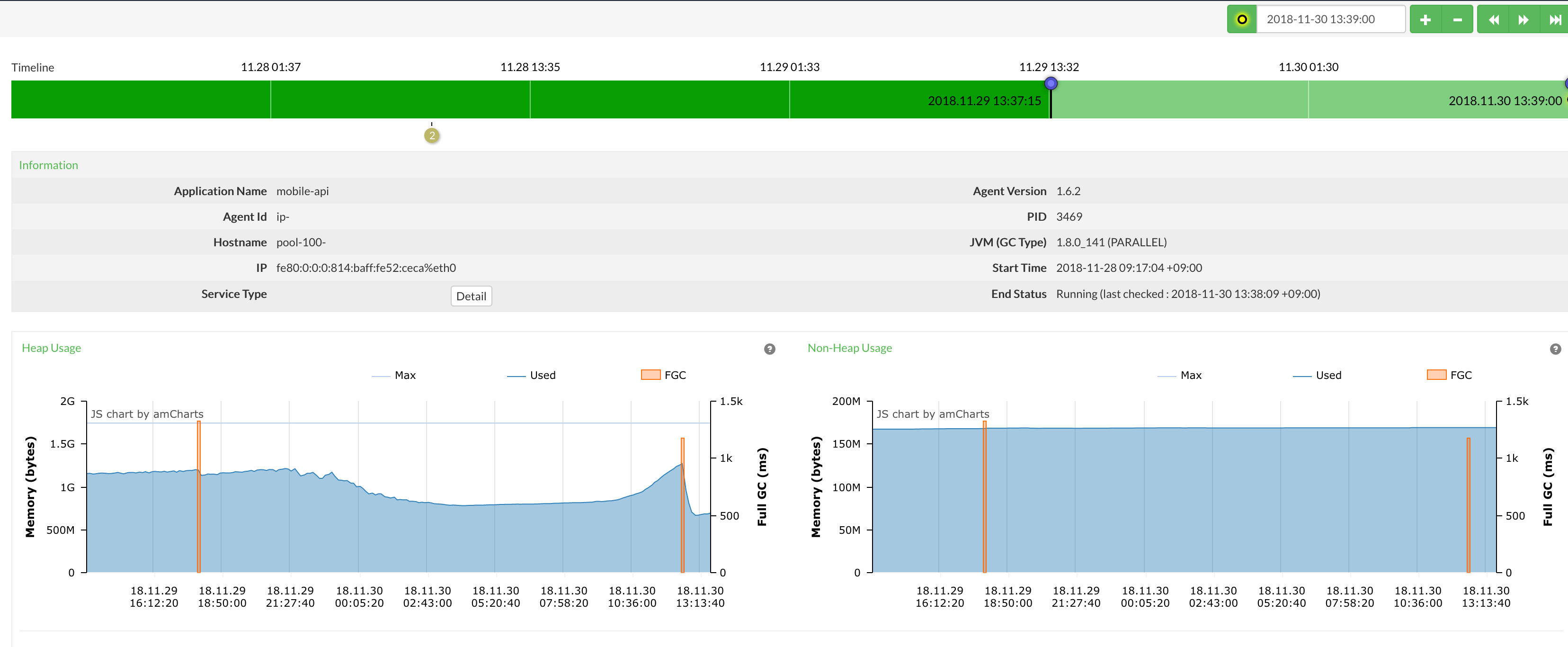
이전부터 FullGC가 간혹 발생하긴 했지만 가용 메모리가 조금 늘어났습니다. 아마 문제는 11월 경에 발생한 것 같아 배포 내역을 확인하니 의심 가는 부분이 2가지가 있었습니다.
- JWT library dependency 변경
ngrinder를 이용해 token 생성 부하 테스트를 해봐도 문제가 발생하지 않았습니다.
- RestTemplate api call 추가
// ... 생략 String url = apiUrl + "/find/" + req.getId(); try { res = restTemplate.getForObject(url, ApiResponse.class); } catch (Throwable t) {} // ... 생략의심가는 부분을 검토해 봤지만 별다른 문제는 없어보여 다른 방법을 고민했습니다.
다시 처음으로..
-
PARALLEL GC->G1GC변경하고 JVM 메모리 옵션 추가 JDK8의 기본 GC는PARALLEL GC입니다. 그래서 이 부분을G1GC로 변경하면서 JVM 메모리 옵션도 추가하기로 했습니다. 근본적인 해결 방법은 아니지만 STW(Stop the world)를 짧게 가져갈 수 있으니 할 수 있는 건 뭐든 해보기로 했습니다. -
문제가 발생했을 때
Heapdump내려서 분석하기 단순히 코드만 보고memory leak를 찾는 건 ‘모래밭에서 바늘 찾기’ 와 마찬가지였습니다. 해결을 위해heapdump분석이 필요했고, 관련 옵션을 추가했습니다.-Xms2g -Xmx4g -XX:+UseG1GC -XX:NewRatio=7 -XX:+PrintGCDetails -XX:+PrintGCDateStamps -verbose:gc -Xloggc:/var/log/gc.log -XX:+HeapDumpOnOutOfMemoryError -XX:HeapDumpPath=/var/log
앗! 다시 문제가 발생했어요

heapdump.. 차례로 따라해요
heapdump를 내립니다.(jmap -dump:format=b,file=heapdump.bin -F {pid})- eclipse memory analyzer 통해서 분석 합니다.
결과
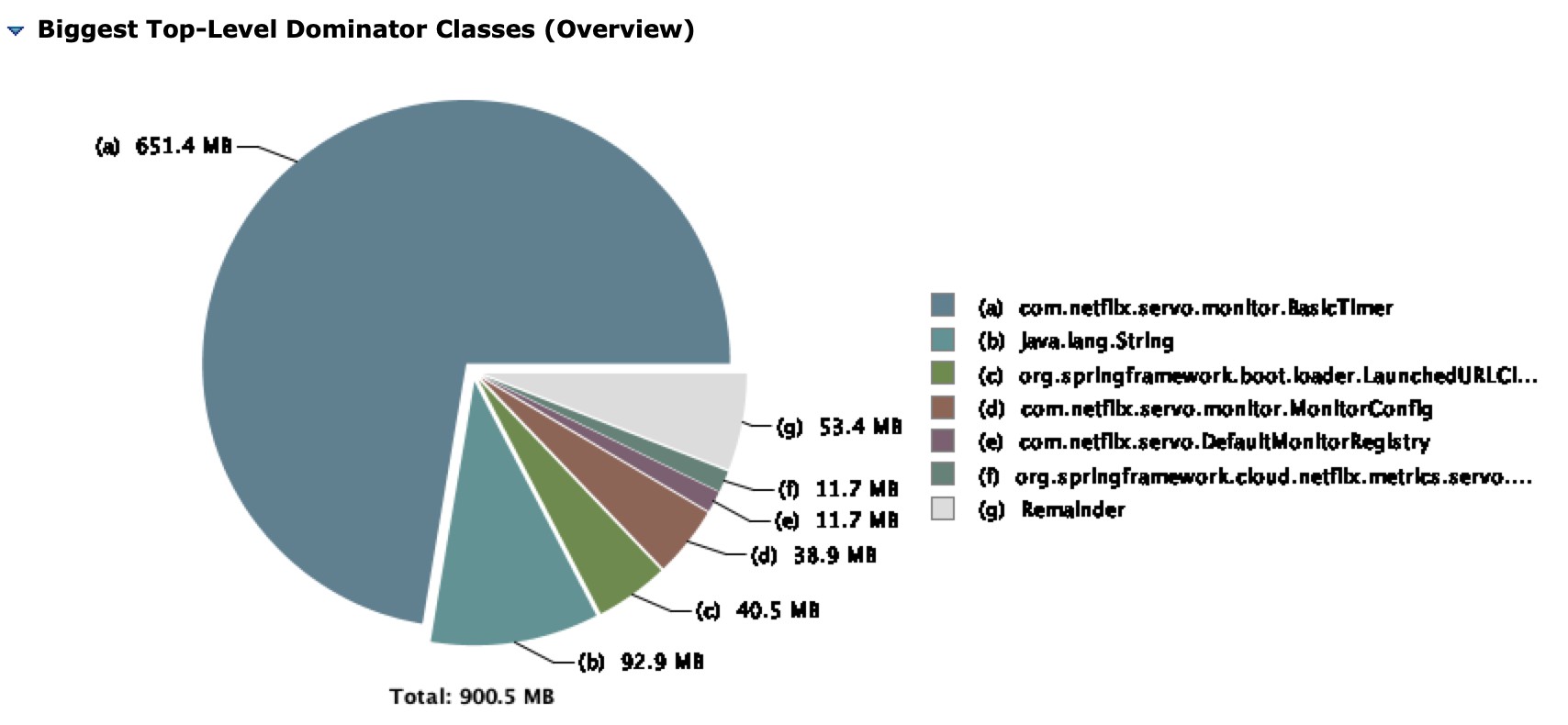 (A) com.netflix.servo.monitor.BasicTimer Object 가 heap memory에서 가장 큰 영역을 차지하고 있습니다.
(A) com.netflix.servo.monitor.BasicTimer Object 가 heap memory에서 가장 큰 영역을 차지하고 있습니다.
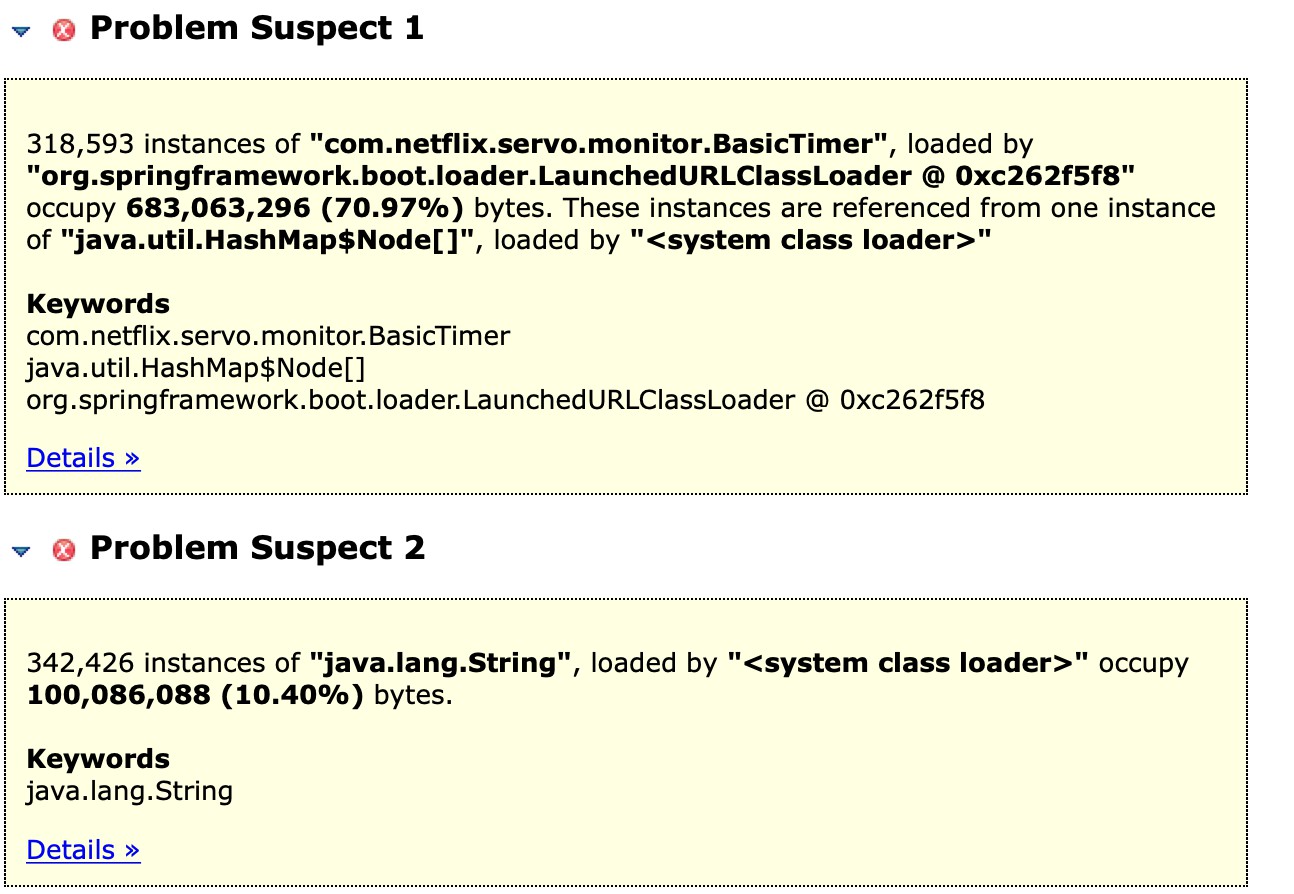 용의자는 2가지로 보입니다. 첫 번째 용의자 .. 심상치 않습니다. 무려 70.97%나 차지하고 있어 상당히 의심 갑니다.
용의자는 2가지로 보입니다. 첫 번째 용의자 .. 심상치 않습니다. 무려 70.97%나 차지하고 있어 상당히 의심 갑니다.
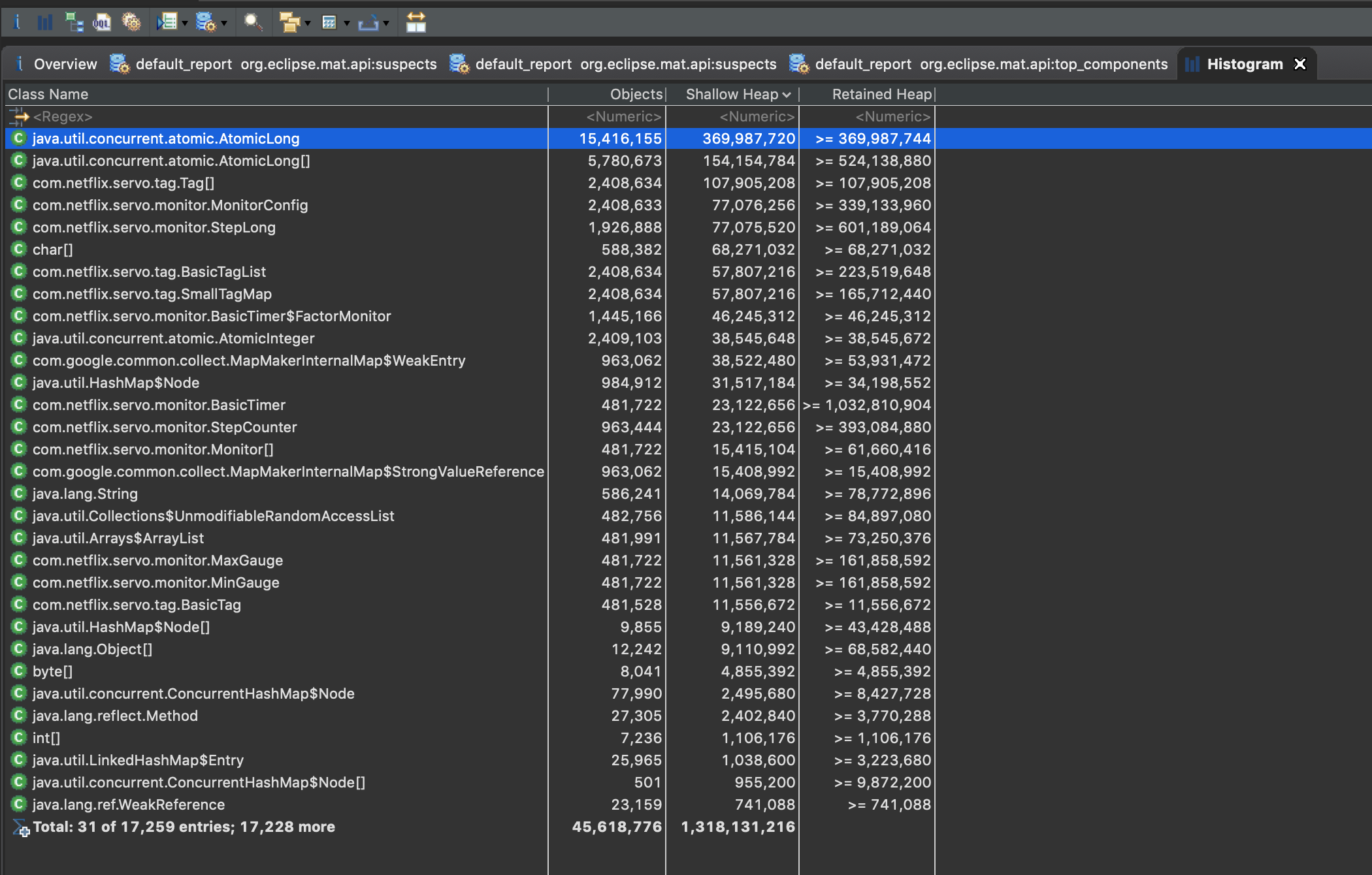
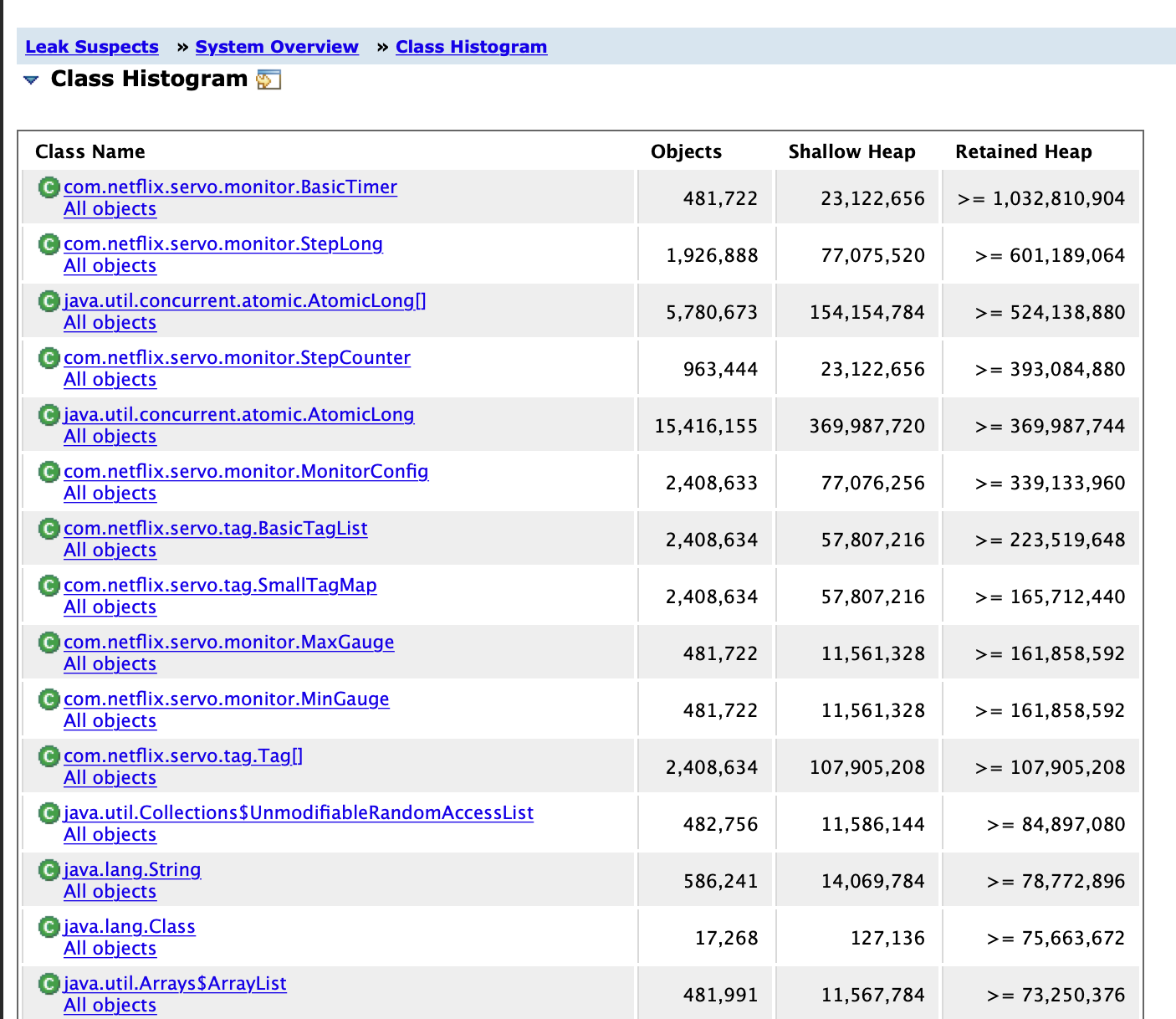 코드를 다시 살펴봐도 관련 기능을 사용하는 곳이 없었고, netflix library는 최근 추가된 패키지가 아니었습니다. 그래서 고민하던 중 팀원분이 링크를 하나 주셨는데 현상이 비슷했습니다. zuul을 사용하고 있고, servo 부분에서 leak 발생한 겁니다. 링크 본문에 있는 또 다른 링크의 하단을 보니 해결책이 친절하게 나와있었습니다.
코드를 다시 살펴봐도 관련 기능을 사용하는 곳이 없었고, netflix library는 최근 추가된 패키지가 아니었습니다. 그래서 고민하던 중 팀원분이 링크를 하나 주셨는데 현상이 비슷했습니다. zuul을 사용하고 있고, servo 부분에서 leak 발생한 겁니다. 링크 본문에 있는 또 다른 링크의 하단을 보니 해결책이 친절하게 나와있었습니다.
해결책 1
spencergibb commented on 3 Sep 2016
use a templated rest template url.
String orderid = “1”;
restTemplate.getForObject(“http://testeurekabrixtonclient/orders/{orderid}”, String.class, orderid)
instead of
restTemplate.getForObject(“http://testeurekabrixtonclient/orders/1”, String.class)
RestTemplate을 사용할 때pathVariable형태의 URL을 호출하려면 바인딩 해서 사용하세요.
해결책 2
wyzssw commented on 23 Jan 2018
Disable ServoMetrics by add spring.metrics.servo.enabled=false to application.properties,
orelse you would suffer Memory Leak From ServoMonitorCache
servoMetrics를 비활성화 하세요.
발생 원인은요.
String url = apiUrl + "/find/" + req.getId();
try {
res = restTemplate.getForObject(url, ApiResponse.class);
} catch (Throwable t) {}
위 코드를 다시 가져왔습니다. restTemplate.getForObject의 pathVariable 부분을 문자열을 합쳐 적용했는데 이 부분에서 발생한 것입니다. 문제가 없어 보이지만 servo metrics 가 url pattern을 고유한 키로 수집을 하는데 find/ 이후 부분의 id 값이 계속 달라지기 때문에 메모리가 계속 쌓이는 것이었습니다.
(아마 restTemplate를 위와 같이 사용하면서 servo metrics가 없었다면 아무 문제는 발생하지 않았을 겁니다. )
이제 원인을 정리하면요
- 서비스에서 사용하는 Netflix zuul library의 dependency는 아래와 같고, servo-core가 포함된 걸 볼 수 있습니다.
compile('org.springframework.cloud:spring-cloud-starter-zuul') ..... | \--- com.netflix.zuul:zuul-core:1.3.0 | +--- commons-io:commons-io:2.4 -> 2.5 | +--- org.slf4j:slf4j-api:1.7.6 -> 1.7.25 | +--- com.netflix.archaius:archaius-core:0.6.0 -> 0.7.4 (*) | +--- com.netflix.servo:servo-core:0.7.2 -> 0.10.1 (*) | \--- com.netflix.netflix-commons:netflix-commons-util:0.1.1 (*) - (1)에서 포함된 servo metrics는 간단한 인터페이스로 metrics를 게시합니다. 링크
Servo provides a simple interface for exposing and publishing application metrics in Java.
- 기본 설정이 활성화(enable) 이고,
RestTemplateurl pattern을 수집하는데 파라미터가 아니면서 바인딩으로 사용하지 않은 pattern을 계속 수집하다memory leak발생한 것이었습니다.org.springframework.cloud.netflix.metrics.servo.ServoMetricsAutoConfiguration
package org.springframework.cloud.netflix.metrics.servo;
@Configuration
@ConditionalOnClass({ Monitors.class, MetricReader.class })
@ConditionalOnMissingClass("com.netflix.spectator.api.Registry")
@AutoConfigureBefore(MetricRepositoryAutoConfiguration.class)
@Import(MetricsInterceptorConfiguration.class)
@ConditionalOnProperty(name = "spring.metrics.servo.enabled", matchIfMissing = true)
public class ServoMetricsAutoConfiguration {
@Bean
@ConditionalOnMissingBean
public ServoMetricsConfigBean servoMetricsConfig() {
return new ServoMetricsConfigBean();
}
@Bean
@ConditionalOnMissingBean
public ServoMetricNaming servoMetricNaming() {
return new HierarchicalServoMetricNaming();
}
...
해결책을 종합해보면요
- restTemplate pathVariable
String url = apiUrl + "/v1/orders/{orderId}"; try { res = restTemplate.getForObject(url, ApiResponse.class, id); } catch (Throwable t) {}id값을pathVariable부분을 바인딩 해서 할당해주면 servo metrics 수집에서 문제가 발생하지 않을 것입니다.
해결책 1의 내용은 cloud.spring.io 에서 확인할 수 있었습니다.
Avoid using hardcoded url parameters within RestTemplate. When targeting dynamic endpoints use URL variables. This will avoid potential “GC Overhead Limit Reached” issues where ServoMonitorCache treats each url as a unique key.
// recommended
String orderid = “1”;
restTemplate.getForObject(“http://testclient/orders/{orderid}”, String.class, orderid)
// avoid
restTemplate.getForObject(“http://testclient/orders/1”, String.class)
사실 서비스에서 servo metrics를 사용하진 않습니다. 이는 zuul dependency에서 같이 포함되었는데 어차피 사용하지 않을 것이니 비활성화합니다.
spring.metrics.servo.enabled=false
차라리 gradle dependeicy에서 제외하는 방법도 있습니다.
compile('org.springframework.cloud:spring-cloud-starter-zuul'){
exclude group: 'com.netflix.servo', module : 'servo-core'
}
검증시간이에요
ngrinder로 수정 반영 전후를 비교해 보았습니다. 테스트는 문제의 api 부분의 id 값을 무작위로 대입해 계속 호출하는 방식입니다.
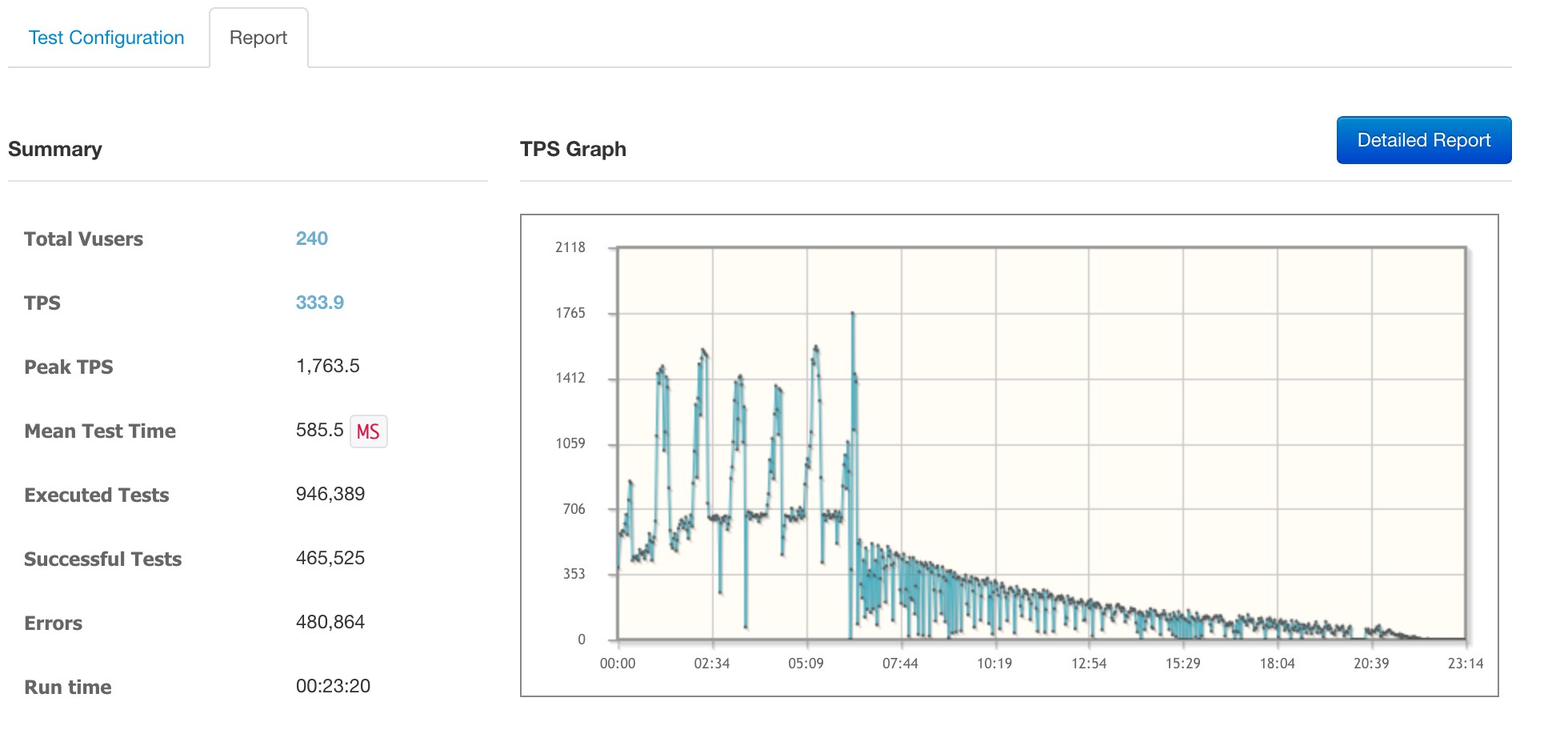 반영 전 상태입니다. 가상 유저 240으로 수행했고, 5분이 지나자 초당 처리량(TPS)이 급격하게 떨어지다가 결국 장애가 발생했습니다.
반영 전 상태입니다. 가상 유저 240으로 수행했고, 5분이 지나자 초당 처리량(TPS)이 급격하게 떨어지다가 결국 장애가 발생했습니다.
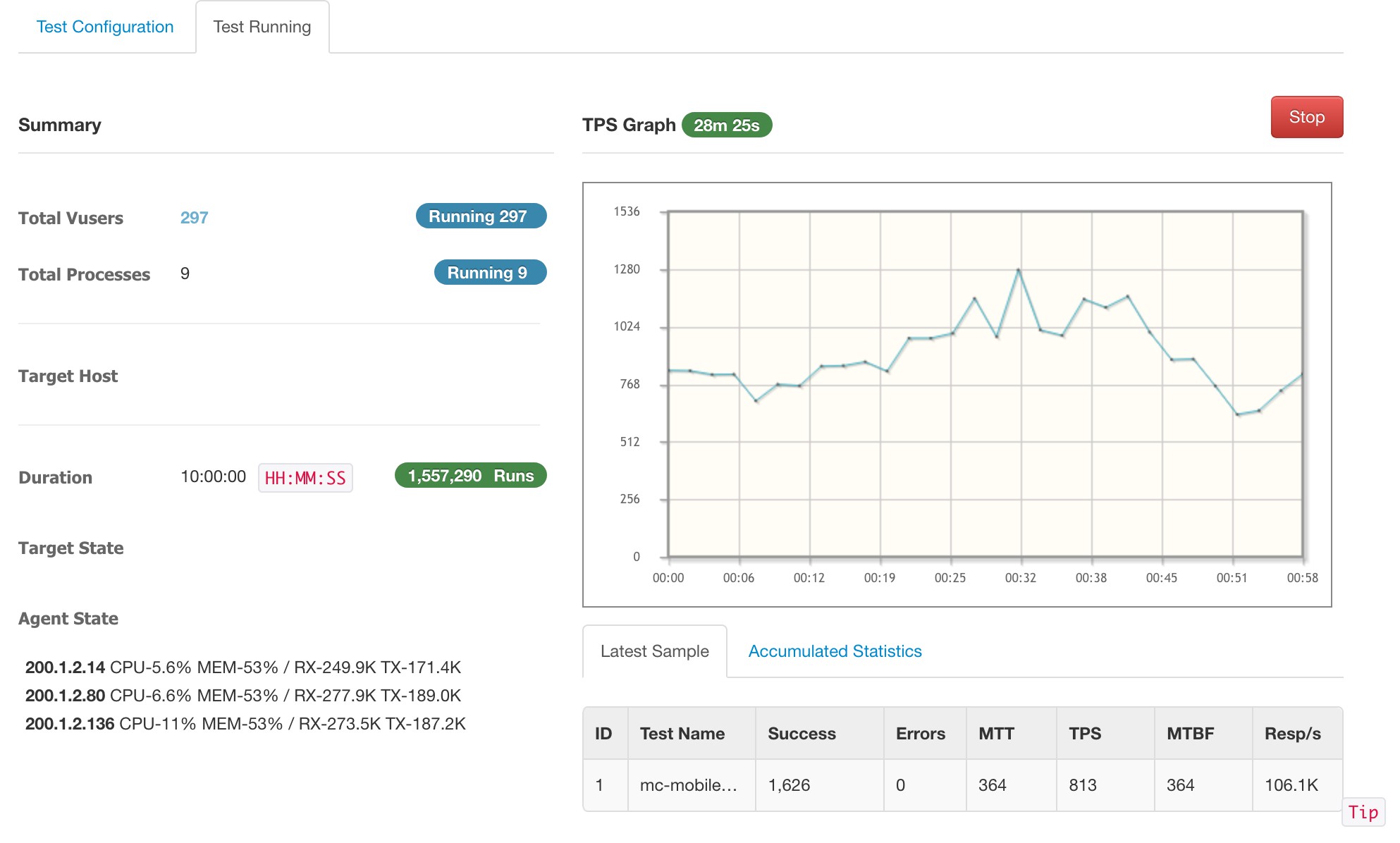 반영 후 총 10시간을 수행했습니다. 가상 유저 297명으로 수행했지만 문제없었습니다.
반영 후 총 10시간을 수행했습니다. 가상 유저 297명으로 수행했지만 문제없었습니다.
결론은요
수정 버전을 배포하고 pinpoint로 살펴봤을 때 문제가 재발하지 않았고, 서비스도 안정적으로 운영되었습니다.
memory leak의 발생 원인은 다양합니다. 내가 작성한 코드에서 발생할 수도 생각지도 못한 부분에서도 발생할 수 있습니다.
(특히 위 사례는 당장 나타나지 않고 트래픽이 점차 늘면서 발생하는 부분이어서 문제점을 찾기 더 어려울 수 있습니다.)
이런 부분은 성능 테스트를 통해 예방할 수 있을 것 같습니다. 그리고 성능 테스트를 해야 하는 이유는 여기를 보시면 큰 도움이 되실 겁니다.
감사합니다!