좌충우돌 Terraform 입문기
• 오지산

안녕하세요, 저는 신사업부문의 오지산이라고 합니다.
저희 신사업부문은 배달의민족과는 조금 다른… 시장의 문제를 해결하기 위해 다양한 신규 서비스들이 개발되는 곳입니다.
그 중에는 아직 출시되지 않은 서비스도 있고, 배달의민족과 비교적 관련성이 적은 서비스들도 있는데요.
저희 조직은 둘 모두에 속하는 서비스를 개발하고 있고,
맡은 도메인의 문제를 해결하기 위해 배달의민족에서 사용되지 않는 기술도 여럿 도입해서 사용하고 있습니다.
다양한 기술을 도입하게 되면 그만큼 세팅할 인프라도 많아지는데요.
특히 AWS 서비스들을 사용할 때는 SQS, CloudWatch 등 연계된 인프라를 세팅해야 하는 경우도 많아집니다.
따라서, 인원이 적은 상태에서 복잡한 인프라 구성을 효율적으로 할 수 있는 방법이 필요해졌습니다.
저희 조직에서는 이 문제를 해결하기 위해 올해 1월부터 Terraform을 사용하기 시작했는데요.
어떻게 사용하고 있는지, 도입하면서 어떤 함정(?)을 만났는지,
그리고 해결하지 못한 과제는 무엇인지를 작게나마 공유드리고자 합니다.
3분만에 훑어보는 Terraform 사용법
먼저 저희 팀에서 Terraform을 사용하는 플로우를 최대한 간결하게 설명드리겠습니다.
원격 상태 저장, AWS CLI에서의 리소스 생성 권한 부여 등은 글의 분량상 생략했습니다.
Terraform 적용을 위해 세밀하게 알아야 하는 것들은 테라폼 설치에서 운영까지 등을 참고해 주시면 감사하겠습니다 :)
코드 작성
기본적인 컨셉은 무척 간단한데요. 원하는 인프라를 코드로 서술할 수 있습니다.
여기서는 AWS를 중심으로 예를 들어 보겠습니다.
가령 SQS를 통해 Queue 하나와 Dead Letter Queue 하나를 쌍으로 구성하고 싶다면…
provider "aws" {}
resource "aws_sqs_queue" "ec2_monitor" {
name = "ec2-monitor"
redrive_policy = "{\"deadLetterTargetArn\":\"${aws_sqs_queue.ec2_monitor_dlq.arn}\",\"maxReceiveCount\":3}"
tags = {
Team = "engineers"
}
}
resource "aws_sqs_queue" "ec2_monitor_dlq" {
name = "ec2-monitor-dlq"
tags = {
Team = "engineers"
Type = "dlq"
}
}
우선 aws provider를 정의하고, 각각의 큐를 aws_sqs_queue라는 resource로 정의합니다.
Terraform에는 이러한 resource들이 provider(AWS, GCP, Azure, …)별로 몇십 가지는 정의되어 있어서,
문서를 통해 원하는 리소스를 찾아내고 개별 속성의 쓰임새를 알 수 있습니다.
그리고 이렇게 생성한 리소스들은 서로 속성을 참조할 수도 있습니다.
ec2_monitor의 redrive_policy 속성을 보시면 ec2_monitor_dlq의 ARN이 참조되고 있는 것을 볼 수 있는데요.
Terraform은 리소스간의 참조 관계를 파악한 뒤, 순서에 맞게 생성/변경/삭제해 주기 때문에
여기저기 흩어진 값을 복사&붙여넣어야 했던 복잡한 인프라 구성도 한꺼번에 생성할 수 있습니다.
환경별 구성
저희 팀의 경우 이렇게 작성한 코드들을 AWS 리소스 기준으로 묶어둡니다.
(outputs나 variables 같은 아리송한 이름의 파일이 눈에 들어오실 텐데요. 밑에서 설명드리겠습니다.)
.
├── cloudwatch.tf
├── main.tf
├── outputs.tf
├── sqs.tf
└── variables.tf
Terraform에서는 폴더 하나가 모듈의 단위가 되기 때문에, 공통으로 사용하는 인프라 구성은 위처럼 모듈화한 뒤
환경별로 변수 값만 바꾸어 재사용하면 개발 환경과 운영 환경에 쉽게 동일한 인프라를 구성할 수 있습니다.
module "ec2_monitor" {
source = "path/to/module/ec2_monitor"
environment = "prod"
tags = {
Phase = "prod"
}
}
변경 계획 확인 및 적용
작성한 Terraform 코드를 적용하려면 우선 CLI를 통해 terraform init 명령을 실행합니다.
init 단계에서는 먼저 provider에 맞는 플러그인을 다운받고, 기존 인프라 상태를 가져올 수 있는지 확인합니다.
Initializing the backend...
Initializing provider plugins...
- Checking for available provider plugins...
- Downloading plugin for provider "aws" (hashicorp/aws) 2.28.1...
[...]
* provider.aws: version = "~> 2.28"
Terraform has been successfully initialized!
이후 terraform plan을 실행하면, Terraform이 코드와 인프라 상태를 대조하여 생성/변경/삭제할 사항들을 나열합니다.
Terraform will perform the following actions:
# aws_sqs_queue.ec2_monitor will be created
+ resource "aws_sqs_queue" "ec2_monitor" {
+ arn = (known after apply)
+ max_message_size = 262144
+ message_retention_seconds = 345600
+ name = "ec2-monitor"
+ policy = (known after apply)
+ receive_wait_time_seconds = 0
+ redrive_policy = (known after apply)
+ tags = {
+ "Team" = "engineers"
}
+ visibility_timeout_seconds = 30
}
# aws_sqs_queue.ec2_monitor_dlq will be created
[...]
Plan: 2 to add, 0 to change, 0 to destroy.
이를 통해 어떤 리소스가 영향을 받으며, 어떤 속성이 변화하는지를 자세하게 알 수 있습니다.
일부 값들은 리소스가 생성되면서 정해지기 때문에 (known after apply)로 표시되고 있네요.
원하는 대로 plan이 나왔다면, terraform apply를 통해 변경 사항들을 적용합니다.
aws_sqs_queue.ec2_monitor_dlq: Creating...
aws_sqs_queue.ec2_monitor_dlq: Creation complete after 0s [id=https://sqs.ap-northeast-2.amazonaws.com/123456789012/ec2-monitor-dlq]
aws_sqs_queue.ec2_monitor: Creating...
aws_sqs_queue.ec2_monitor: Creation complete after 0s [id=https://sqs.ap-northeast-2.amazonaws.com/123456789012/ec2-monitor]
Apply complete! Resources: 2 added, 0 changed, 0 destroyed.
DLQ의 ARN을 원래 Queue의 redrive_policy에서 참조하기 때문에, DLQ를 먼저 생성해 주고 있네요.
콘솔을 확인하면 이렇게…
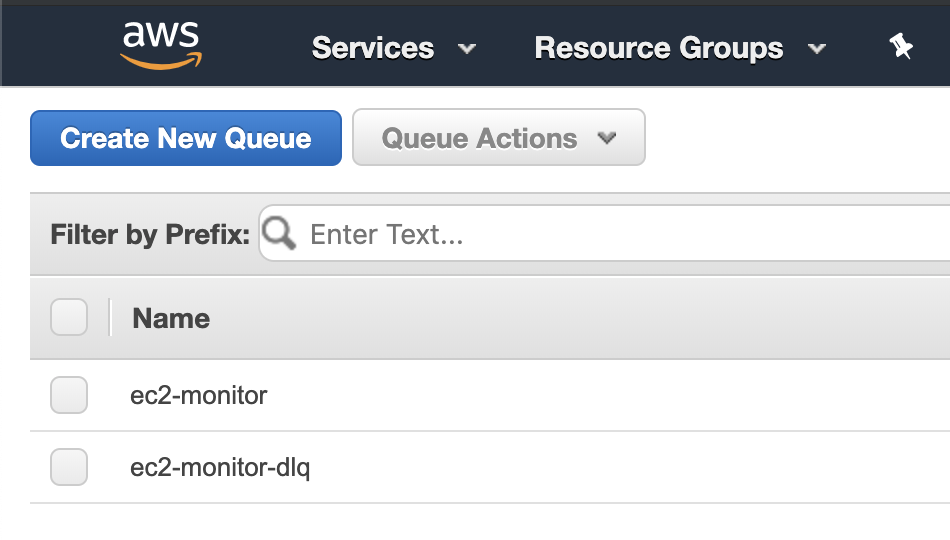
리소스들이 잘 생성된 것을 확인하실 수 있습니다.
Terraform 적용 중 만난 함정들
이렇게 간단하게만 쓸 수 있다면 좋았겠지만…

실제로 Terraform을 통해 인프라를 구성할 때는 시행착오를 겪지 않을 수 없었는데요.
여기서는 제가 기존 Terraform 코드에 손을 대기 시작하면서부터 만났던 함정들을 소개해 보고자 합니다.
resource 빼고 다 생소한 문법
처음 Terraform 코드를 볼 때는 사실 resource 이외의 모든 문법이 난관이었습니다.
data, variable, output, locals 같은 용어가 훅훅 튀어나오는데요.
가령 위에서 사용했던 Queue + DLQ 구성을 조금만 더 모듈화해도 이런 코드가 나옵니다.
variable "environment" {
type = string
}
variable "tags" {
type = map(string)
default = {}
}
locals {
tags = merge(var.tags, {
Module = "ec2_monitor"
})
}
resource "aws_sqs_queue" "ec2_monitor" {
name = "${var.environment}-ec2-monitor"
redrive_policy = "{\"deadLetterTargetArn\":\"${aws_sqs_queue.ec2_monitor_dlq.arn}\",\"maxReceiveCount\":3}"
tags = merge(local.tags, {
Type = "queue"
})
}
[...]
output "ec2_monitor_queue_arn" {
value = aws_sqs_queue.ec2_monitor.arn
}
variable, locals, output의 역할이 무엇인지 감이 오시나요?
처음 Terraform 코드를 볼 때는 var.tags가 무엇인지 모르겠어서 한참을 봤던 것 같습니다.
익숙한 단어에 다른 쓰임새입니다만, 실제로 사용해 보면 어렵지는 않습니다.
이 상태로 terraform apply 명령을 실행해 보면…
var.environment
Enter a value:
variable의 값을 입력해 달라고 요구합니다. 여기서 dev를 입력하면…
Terraform will perform the following actions:
# aws_sqs_queue.ec2_monitor must be replaced
-/+ resource "aws_sqs_queue" "ec2_monitor" {
~ name = "ec2-monitor" -> "dev-ec2-monitor" # forces replacement
redrive_policy = jsonencode(
{
deadLetterTargetArn = "arn:aws:sqs:ap-northeast-2:123456789012:ec2-monitor-dlq"
maxReceiveCount = 3
}
)
~ tags = {
+ "Module" = "ec2_monitor"
- "Team" = "engineers" -> null
+ "Type" = "queue"
}
}
[...]
제가 입력한 값이 aws_sqs_queue.ec2_monitor.name의 일부로 들어가는 것을 보실 수 있습니다.
또한 apply가 끝나면…
Apply complete! Resources: 1 added, 1 changed, 1 destroyed.
Outputs:
ec2_monitor_queue_arn = arn:aws:sqs:ap-northeast-2:123456789012:dev-ec2-monitor
output으로 지정한 값이 출력되는 것을 볼 수 있습니다.
이로 미루어 보아 variable은 입력, output은 출력의 역할을 한다는 것을 알 수 있습니다.
또한 locals는 지역 변수와 비슷하게 모듈 내에서 재사용할 값을 정의하는데,
주로 모듈 내 리소스에 공통 태그를 지정할 때 유용하게 사용합니다.
위 세 개념이 이해되셨다면 더 난감한 문법을 보여드리려고 합니다.
아래 코드에는 세 개의 data block이 있는데요. 각각의 용도가 무엇일지 짐작되시나요?
data "aws_availability_zones" "available" {
state = "available"
}
data "aws_arn" "db_instance" {
arn = "arn:aws:rds:ap-northeast-2:123456789012:db:mysql-db"
}
data "terraform_remote_state" "ec2_monitor" {
backend = "s3"
config = {
region = "ap-northeast-2"
bucket = "terraform-state"
key = "dev/ec2_monitor/terraform.tfstate"
dynamodb_table = "terraform-state-lock"
role_arn = "[...]"
}
}
resource "aws_instance" "foo" {
[...]
user_data = "...${data.terraform_remote_state.ec2_monitor.ec2_monitor_queue_arn}..."
}
처음 이 문법을 봤을 때 저는 멍해졌는데요. 같은 data block이라도 정보의 출처가 다르고,
그 결과 각각의 용도가 달라진다는 컨셉을 이해하지 못해서였습니다.
위에서부터 하나씩 설명드리면…
aws_availability_zones는 AWS region에 존재하는 가용 영역을 가져옵니다.
즉 provider에서 값을 가져오기 위해 사용됩니다. aws_region 등이 비슷한 용도를 가지고 있고요.
aws_arn은 ARN을 파싱하기 위해서 사용됩니다.
즉 사용자가 제공한 정보를 가공하기 위해 사용됩니다. 이런 용도로는 aws_iam_policy_document가 대표적입니다.
terraform_remote_state는 remote state에서 다른 모듈의 정보를 가져오기 위해 사용됩니다.
remote state에 대한 자세한 내용은 분량상 설명드리기 어렵지만,,
코드만 보면 원격 저장소(AWS S3 버킷 등)에 있는 파일을 읽어온다는 것을 눈치채셨을 듯합니다.
요컨대 data block이 정보를 가져오는 출처는 무척 다양하고,
그 결과 provider 상태 가져오기, ARN 파싱, JSON 구성, 다른 모듈의 output값 접근 등
수많은 용도로 data block이 사용되고 있습니다.
개인적으로는 이 부분을 캐치하고 나서 Terraform 코드가 이해되기 시작했던 것 같습니다.
순환 참조
처음 리소스를 구성하다 보면 순환 참조(Cycle) 때문에 막히는 경우를 종종 만나게 됩니다.
가령 SQS Queue에 아래처럼 Policy를 추가하려고 하면, 무리 없이 될 것 같지만…
resource "aws_sqs_queue" "ec2_monitor" {
name = "${var.environment}-ec2-monitor"
policy = data.aws_iam_policy_document.queue_policy_doc.json
tags = merge(local.tags, {
Type = "normal"
})
}
data "aws_iam_policy_document" "queue_policy_doc" {
statement {
effect = "Allow"
principals {
type = "Service"
identifiers = ["events.amazonaws.com"]
}
actions = [
"sqs:SendMessage",
]
resources = [
aws_sqs_queue.ec2_monitor.arn
]
[...]
}
}
실제로 terraform apply를 하면 Cycle Error가 발생합니다. 무엇이 문제일까요?
Error: Cycle: data.aws_iam_policy_document.queue_policy_doc, aws_sqs_queue.ec2_monitor
코드를 다시 보면, SQS Queue는 생성 시점에 queue_policy_doc의 json을 policy 속성으로 넘겨받아야 하는데,
queue_policy_doc은 아직 생성되지도 않은 SQS Queue의 ARN을 참조하고 있습니다.
이렇게 서로가 서로를 참조하는 상황이 발생하면 Terraform은 어느 쪽을 먼저 생성할지 결정할 수 없게 됩니다.
하지만 SQS Policy에서 해당 SQS Queue의 ARN을 명시한다는 컨셉 자체는 문제가 없는 부분인데요.
이렇듯 멀쩡한 인프라 구성이 순환 참조에 걸리게 되면, 잘 모르는 입장에서는 당황하기 쉬운 것 같습니다.
저희 팀도 처음에는 SQS Queue의 ARN을 직접 만들어내는 방식으로 어렵사리 순환 참조를 회피했는데요.
(자세한 설명은 생략하겠습니다)
알고 보니 Terraform에서 순환 참조 회피용으로 aws_sqs_queue_policy를 제공하고 있었습니다.
resource "aws_sqs_queue" "ec2_monitor" {
name = "${var.environment}-ec2-monitor"
# policy 속성을 별도의 리소스로 뺍니다.
}
resource "aws_sqs_queue_policy" "ec2_monitor_queue_policy" {
queue_url = aws_sqs_queue.ec2_monitor.id
policy = data.aws_iam_policy_document.ec2_monitor_queue_policy_doc.json
}
data "aws_iam_policy_document" "queue_policy_doc" {
statement {
[...]
resources = [
aws_sqs_queue.ec2_monitor.arn
]
[...]
}
}
어차피 순환 참조 아니야? 라는 생각이 드실 수도 있겠습니다만, aws_sqs_queue_policy 하나를 넣는 것만으로도
‘SQS Queue 생성 -> queue_policy_doc 구성 -> SQS Policy 추가’의 플로우를 탈 수 있어 선후 관계가 정리됩니다.
그 결과 훨씬 간단하게 순환 참조를 회피할 수 있었습니다.

요컨대 순환 참조를 만나셨으면 먼저 문서를 보고 해결책이 있는지 확인하시는 것을 추천드립니다.
콘솔에서 자동 생성되는 리소스들
간혹 AWS 콘솔에서 작업했던 경험으로 ‘이거면 되겠지’ 하고 인프라 구성을 끝내면, 작동하지 않을 수가 있는데요.
콘솔에서 작업할 때 자동 생성되었던 리소스를 Terraform 코드에 반영하지 못해 발생하는 문제일 수도 있습니다.
가령 AWS의 특정 이벤트를 SQS Queue로 받기 위해 CloudWatch Event Rule을 아래처럼 만들었습니다. 작동할까요?
resource "aws_cloudwatch_event_rule" "ec2_state_to_sqs" {
name = "ec2-state-to-sqs"
description = "Capture State Change from EC2 Instance."
event_pattern = <<PATTERN
[...]
PATTERN
}
resource "aws_cloudwatch_event_target" "sqs" {
rule = aws_cloudwatch_event_rule.ec2_state_to_sqs.id
arn = aws_sqs_queue.ec2_monitor.arn
}
resource "aws_sqs_queue" "ec2_monitor" {
[...]
}
아무 문제 없을 것 같지만,, Event Rule에서 SQS Queue로 이벤트를 발송하려면
엄연히 SQS Policy를 생성하여 Event Rule이 접근할 수 있도록 권한을 부여해 주어야 합니다.
(위에서 순환 참조를 해결하기 위해 그렇게 노력한 이유이기도 합니다 🧐)
하지만 콘솔에서 Event Rule을 직접 생성하면 SQS Policy를 만들어 줄 필요가 없는데요.
아래처럼 Target으로 SQS Queue를 지정하면…
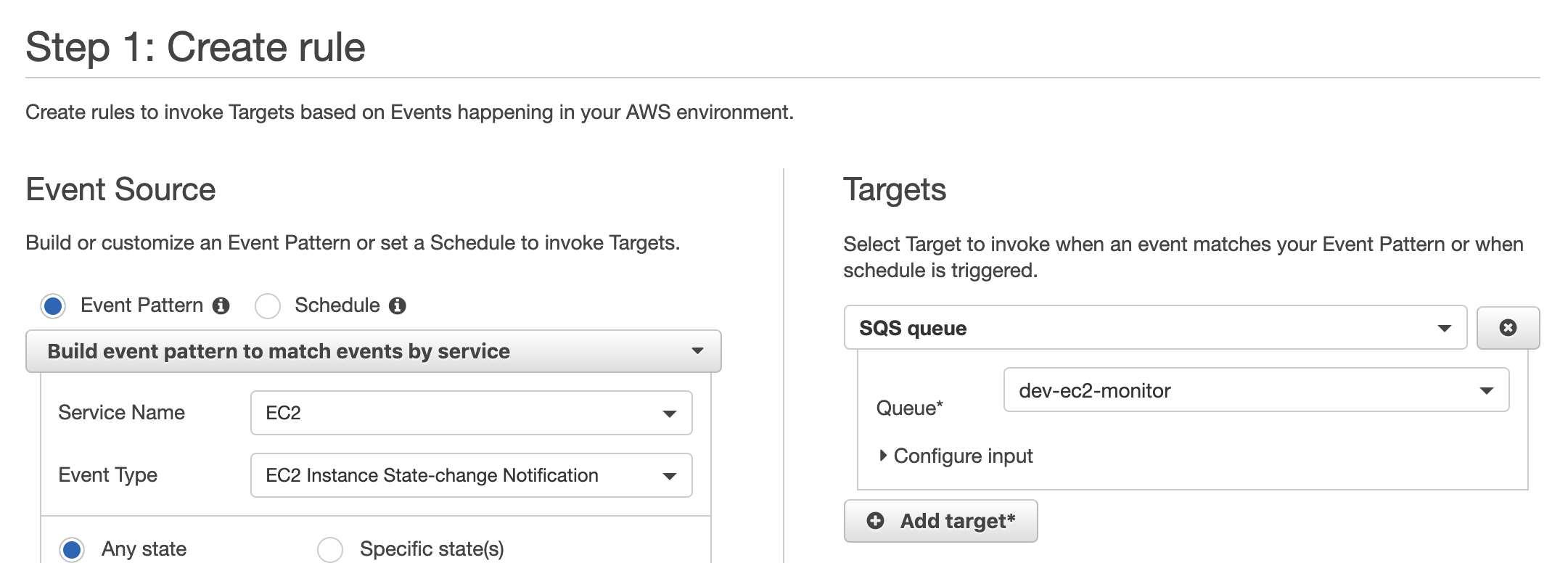
콘솔이 SQS Policy를 자동 생성해 주기 때문입니다.
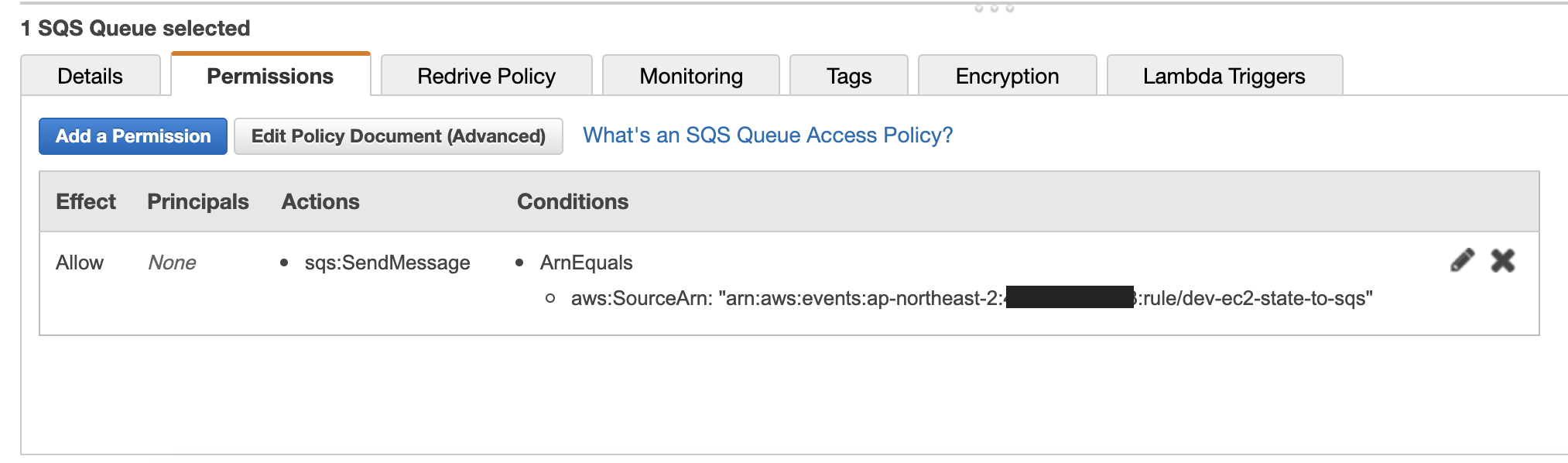
여기서 SQS Policy의 존재 자체를 모른다면 헤맬 수밖에 없게 됩니다. 구성은 했는데 Event가 한 개도 안 오는 답답함…!
따라서 기존 인프라 구성을 Terraform으로 옮기실 때에는, 자동 생성되는 리소스들도 꼼꼼하게 챙겨주셔야 합니다.
원하는 게 없다면…?
실제로 저희 팀에서 사용하는 서비스 중 하나는 Terraform resource에 존재하지 않아 수동으로 구성할 수밖에 없었는데요.
지금 이 순간에도 terraform-provider-aws에는 추가되지 못한 리소스들이 코드화의 꿈을 꾸고 있습니다.
추가되길 바라는 마음으로, 팀원분들과 함께 +1를 남기고 왔습니다.
더 나은 Terraform 사용을 위한 과제
이렇게 열심히 함정을 뛰어 넘었지만 마지막 함정은 못 넘었네요…
해결하지 못한 과제들도 있습니다.
가령 한동안 Terraform 코드에 변경 사항이 쌓였는데도 제때 적용되지 않아서,
코드 일부만 바꾸었는데도 terraform plan을 돌리면 어마어마한 변경 사항이 나오는 경우도 있었습니다.
공통 태그를 바꾸면 모든 리소스에 변경 사항이 전파되기도 하고,
SQS Queue나 Load Balancer 같은 리소스들은 이름이 변경되면 삭제 후 재생성해야 하기 때문에 곤란한 적도 있었고요.
# aws_sqs_queue.ec2_monitor must be replaced
-/+ resource "aws_sqs_queue" "ec2_monitor" {
~ name = "dev-ec2-monitor" -> "ec2-monitor" # forces replacement
[...]
}
또한 지금은 서비스가 런칭하지 않았기 때문에 다들 거침없이 terraform apply를 하고 있지만,
추후 운영 중인 인프라를 변경하기 위한 플로우도 세워야 할 것 같습니다.
이때 terraform plan을 사용하면 인프라 변경 사항을 바로 예측할 수 있기 때문에,
코드 리뷰어가 큰 도움을 받을 수 있을 거라고 생각됩니다.
실제로 저희 팀 내에서 Terraform 코드를 리뷰할 때 terraform plan을 활용하기도 했었고요.

Terraform 적용 소감
아직 팀 내의 모든 개발자가 Terraform에 익숙하지는 않지만,
테라포밍 작업을 맡아보신 분들은 하나같이 이렇게 말합니다. 광고 같네요
콘솔로 돌아갈 수 없을 것 같아요.
클릭클릭과 복붙에서 오는 스트레스를 벗어나, 효율적으로 인프라를 생성할 수 있다는 데에 반하게 되는 것 같아요.
인프라 구성할 일이 생기면 우선 Terraform으로 자동화가 가능한지를 궁금해 하게 됩니다.
다만 진입장벽이 있다는 것을 부정하기는 어려운데요.
어떻게 하면 함께 진입장벽을 넘을 수 있을지는 고민인 부분입니다.
그런 점에서 저희 조직은 출시&운영 이후에도 기술 블로그로 풀어놓을 얘기가 많을 듯한데요.
뒤이어 올라오게 될 글, 그리고 저희 조직을 비롯해 각자가 새로운 도메인을 개척하고 있는
신사업부문 개발자들의 기술 블로그 글에도 많은 관심을 부탁드립니다. :)
감사합니다.
