검색을 위한 데이터 다루기
• 정철

안녕하세요. 우아한형제들 검색개발팀 정철입니다.
배달의민족 검색시스템에서 검색에 사용되는 데이터를 적재하면서 경험했던 어려움과 해결했던 방법을 공유하고자 합니다.
검색시스템이란?
먹고 싶은 음식을 찾는 첫 단계
배달의민족에서 검색시스템은 주문하고 싶은 가게 또는 메뉴를 빠르게 찾을 수 있도록 도와주는 여러 기능을 개발하고 있습니다.
- 검색 기능
- 인기검색어
- 1인분, 채식 등의 테마 지면 리스팅
배달 빠른 순, 배달팁 낮은 순과 같은 정렬과최소주문금액, 쿠폰, 예약등의 필터 기능
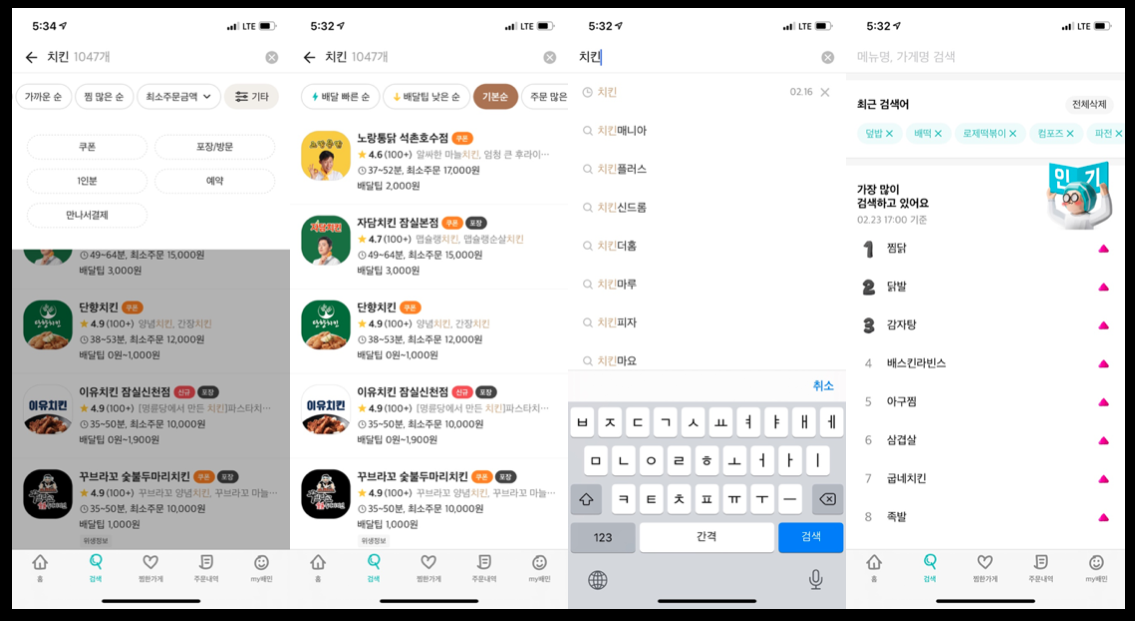 검색개발팀이 제공하는 서비스
검색개발팀이 제공하는 서비스
단순하다고 생각될 수 있는 시스템이지만 실시간으로 가게에 대한 정보를 동기화하기 위해서 십여개의 외부시스템으로부터 실시간 정보를 저장해야 하며, 시간, 위치를 기반으로 복잡한 수식으로 가게의 여러정보를 계산해야하는 복잡한 시스템입니다.
추가되는 서비스, 늘어나는 과부하
검색시스템은 위의 소개했던 것과 같은 서비스를 제공하기 위해서 광고, 메뉴, 리뷰, 통계… 등 십여 개의 데이터를 aws의 SQS를 사용하여 수신하고 이를 검색엔진 Elasticseach에 저장하고 있습니다.
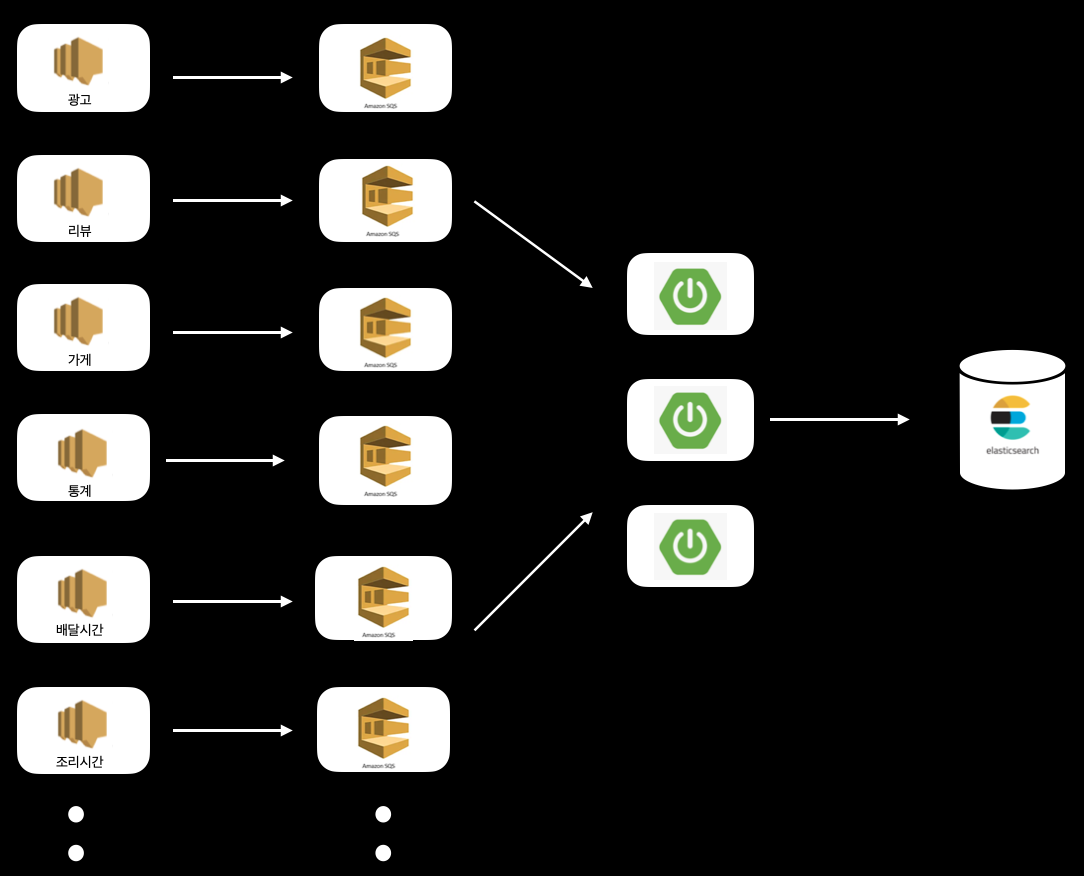 데이터 수신 구조
데이터 수신 구조
초기 시스템 설계 시 들어오는 데이터의 양이 그렇게 많지 않았고 예측 가능했기 때문에 개별적으로 들어오는 이벤트를 건바이건으로 update request를 만들어서 반영하였습니다.
// 가게 이벤트 수신
@SqsListener(value = "shopSqs", deletionPolicy = NEVER)
public void tagsUpdateListen(@Payload ShopChangeEvent shopChangeEvent, Acknowledgment acknowledgment) {
shopElasticsearch.update(createUpdateRequest(shopChangeEvent));
}
...
// 리뷰 이벤트 수신
@SqsListener(value = "reviewSqs", deletionPolicy = NEVER)
public void tagsUpdateListen(@Payload ReviewChangeEvent reviewChangeEvent, Acknowledgment acknowledgment) {
shopElasticsearch.update(createUpdateRequest(reviewChangeEvent));
}
POST baemin-search/_update/1234567
{
"doc": {
"shopName": "배민의 맛집가게",
"address": "송파구 방이동 44-2"
}
}
하지만 가게가 증가함에 따라 가게가 오픈하는 시간대나 주문이 많아서 메뉴 품절 등의 상황이 많이 발생하는 경우에는 이벤트를 많이 수신하게 되었고 그에 따라 모든 부담이 Elasticsearch에 집중되면서 Elasticsearch Writer Thread Pool이 가득 차서 request가 rejected 되는 문제와 Disk I/O 문제로 cpu 수치가 기하급수적으로 상승하는 문제가 발생하였습니다.
이런 상황 속에 현재 상태를 유지하기도 어려워졌고 더불어 배달 빠른 순, 배달팁 낮은 순정렬/필터와 같이 사용자에게 편의를 줄 수 있는 여러 feature를 저희 시스템 문제로 개발이 지연되는 문제가 발생하였습니다.
원인 분석
문제 1. 잦은 변경에 의한 Disk I/O 이슈
Elasticsearch의 Index는 Lucene 기반의 작은 segment 파일로 구성되어 있습니다. 이 segment는 검색 요청을 빠르게 처리하기 위해서 여러 개로 생성이 되어있습니다. 하지만 이 segment는 속도, 성능, 동시성 이슈, 압축 등의 이유로 immutable 한 속성을 가지고 있기 때문에 Index에 대한 업데이트 요청이 오게 되면 기존 segment에 mark만 하고 새로운 segment를 생성하여 데이터를 기록하는 동작을 진행합니다.
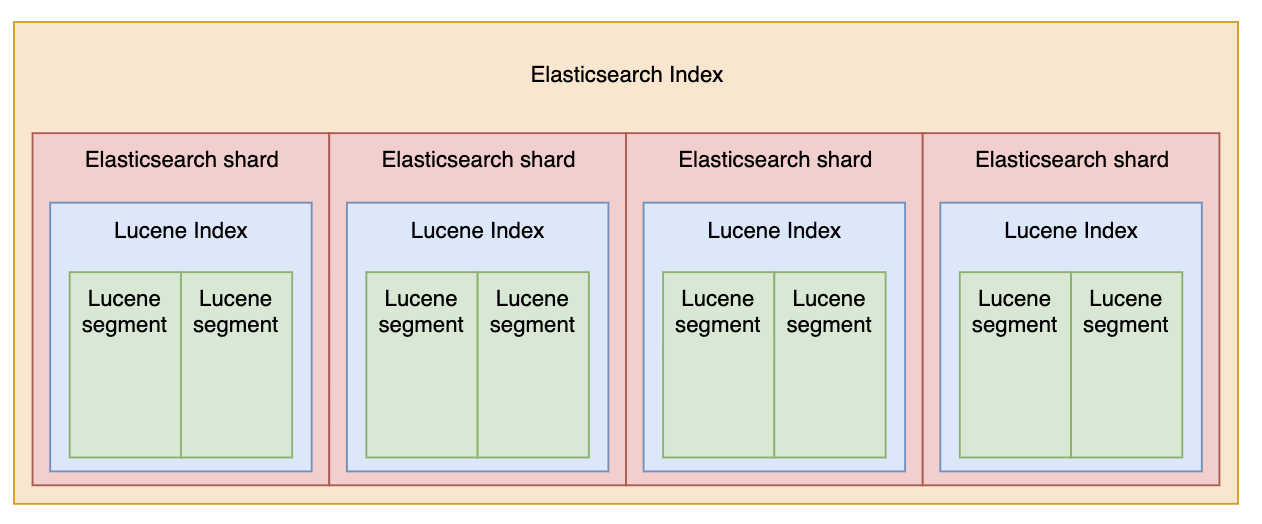 이미지 출처 구글
이미지 출처 구글
저희에 문제는 바로 여기에 있었습니다. 잦은 업데이트로 인해 다량의 segment가 생성되면서 Disk I/O가 증가하게 되었고 그 결과 cpu가 동반 상승했으며, 삭제 대상 segment를 지우고 단편화 해소를 위해 동작하는 force merge 시에도 부하가 발생하는 문제가 확인되었습니다.
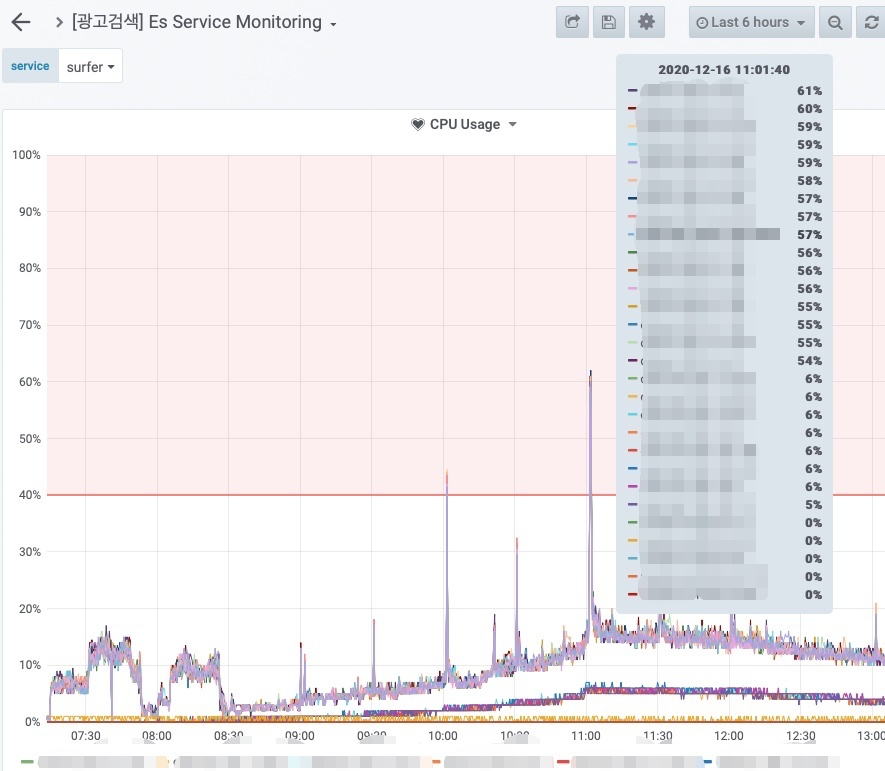 문제의 cpu 상태
문제의 cpu 상태
문제 2. 건바이건 요청으로 인한 thread pool 초과
가게에 해당하는 속성 변경 이벤트가 몰리는 시간대에는 최대 수십만 건 이상의 이벤트가 발생합니다. 이 이벤트를 건바이건으로 업데이트를 하면서 Elasticsearch의 write thread pool을 모두 점유하고 queue까지 가득 차게 되면서 일부 이벤트가 정상적으로 업데이트 되지 못하고 rejected 되는 경우가 빈번하게 발생하였습니다.
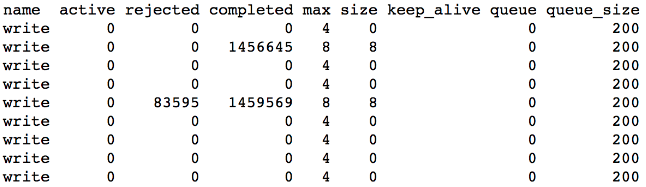 rejected request 개수
rejected request 개수
정답은 언제나 기본에 있다
To optimize insert speed, combine many small operations into a single large operation. Ideally, you make a single connection, send the data for many new rows at once, and delay all index updates and consistency checking until the very end.
출처 : https://dev.mysql.com/doc/refman/8.0/en/insert-optimization.html
insert 성능을 높이기 위해서는 작은 여러 연산을 큰 하나의 연산으로 만들어라.라는 말을 위의 mysql doc에서 볼 수 있듯이 그렇게 배웠고 그렇게 개발을 진행했었습니다.
Elasticsearch 또한 같은 개념을 가지고 있으며 단건 request 수행 보다 Bulk request의 효능이 큰 것은 여러 벤치마킹을 통해서도 입증이 되었습니다.
그럼 우리도 이 문제를 해결하기 위해 bulk로 동작을 시키는 방법을 적용해보기로 했습니다. 하지만 언제나 문제는 쉽게 해결되지 않듯이 역시 문제가 있었습니다. 검색의 현재 구조는 모든 이벤트를 별도의 sqs를 listen 하여 받고 있기 때문에 서로 다른 sqs에서 데이터를 받아서 처리하기에는 무리가 있었습니다.
그러다 Elasticsearch의 resthighlevelclient java api에서 Bulk processor 라는 기능을 사용하여 request를 모아서 업데이트하는 기능을 발견하게 되었습니다. Bulk Processor는 하나의 독립적인 프로세스를 실행시키고 request를 buffer에 모아서 정해진 시간, 크기 등에 맞게 Elasticsearch에 데이터를 Bulk request를 만들어서 flush하도록 동작하고 있습니다.
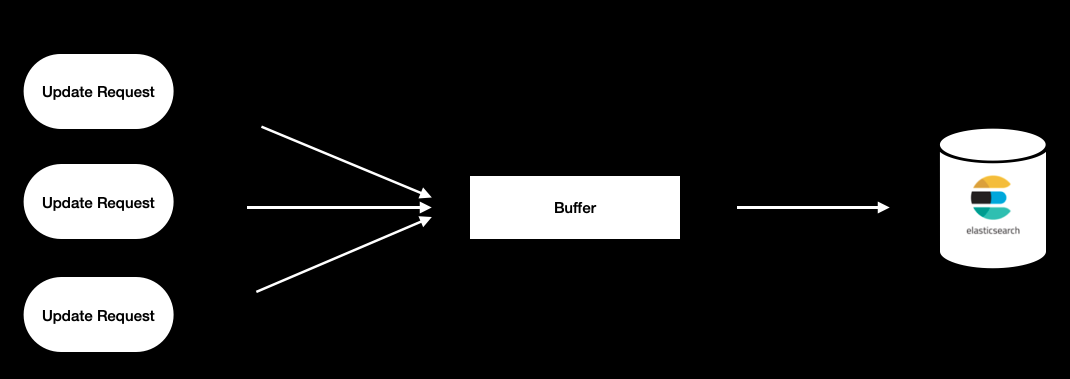 Bulk processor 구조
Bulk processor 구조
이걸 사용해서 저희의 문제를 풀어보기로 했으며 있는 그대로 사용하지 않고 조금 더 나은 성능을 만들기 위해 튜닝도 함께 진행했습니다.
튜닝 1.
기존 Bulk processor는 DocWriteRequest를 담는 List를 가지고 있는 BulkRequest라는 Buffer용 객체를 사용하여 데이터를 담고 시간, 사이즈 등의 flush 타이밍이 되면 해당 버퍼를 BulkProcessorHandler를 통해 전달하고 Elasticsearch에 Bulk request를 요청하는 구조로 되어있습니다.
// BulkRequest (Buffer 역할을 하는 객체)
public class BulkRequest extends ActionRequest implements CompositeIndicesRequest, WriteRequest<BulkRequest> {
private static final int REQUEST_OVERHEAD = 50;
/**
* Requests that are part of this request. It is only possible to add things that are both {@link ActionRequest}s and
* {@link WriteRequest}s to this but java doesn't support syntax to declare that everything in the array has both types so we declare
* the one with the least casts.
*/
final List<DocWriteRequest<?>> requests = new ArrayList<>();
..
..
..
/**
* Adds a list of requests to be executed. Either index or delete requests.
*/
public BulkRequest add(DocWriteRequest<?>... requests) {
for (DocWriteRequest<?> request : requests) {
add(request, null);
}
return this;
}
}
// BufferProcessor add메소드를 통해 BulkRequest에 request를 만들어서 담는 부분
bulkProcessor.add(new IndexRequest("twitter", "_doc", "1").source(/* your doc here */));
bulkProcessor.add(new DeleteRequest("twitter", "_doc", "2"));
// BulkProcessor Handler
public void execute(BulkRequest bulkRequest, long executionId) {
Runnable toRelease = () -> {};
boolean bulkRequestSetupSuccessful = false;
try {
listener.beforeBulk(executionId, bulkRequest);
semaphore.acquire();
toRelease = semaphore::release;
CountDownLatch latch = new CountDownLatch(1);
retry.withBackoff(consumer, bulkRequest, new ActionListener<BulkResponse>() {
@Override
public void onResponse(BulkResponse response) {
try {
listener.afterBulk(executionId, bulkRequest, response);
} finally {
semaphore.release();
latch.countDown();
}
}
@Override
public void onFailure(Exception e) {
try {
listener.afterBulk(executionId, bulkRequest, e);
} finally {
semaphore.release();
latch.countDown();
}
}
});
bulkRequestSetupSuccessful = true;
if (concurrentRequests == 0) {
latch.await();
}
} catch (InterruptedException e) {
Thread.currentThread().interrupt();
logger.info(() -> new ParameterizedMessage("Bulk request {} has been cancelled.", executionId), e);
listener.afterBulk(executionId, bulkRequest, e);
} catch (Exception e) {
logger.warn(() -> new ParameterizedMessage("Failed to execute bulk request {}.", executionId), e);
listener.afterBulk(executionId, bulkRequest, e);
} finally {
if (bulkRequestSetupSuccessful == false) { // if we fail on client.bulk() release the semaphore
toRelease.run();
}
}
}
저희는 이 부분에서 수신한 이벤트를 Bulk processor에 add 할 때 Update request를 만들어서 buffer에 밀어 넣는 부분이 번거로웠고 같은 index에 동일한 Update Request 규칙을 만들때도 모든 이벤트 수신부분에 일괄 적용하기 어려웠습니다. 그래서 buffer 역할을 하는 BulkRequest를 걷어내고 Update Request를 만들기 위한 Shop이라는 객체를 만들고 이 객체들을 담을 수 있는 Map으로 대체하였습니다
각 이벤트 수신위치에서는 Bulk Processor에 add 할 때 각 이벤트별 변경 부분만 전달할 수 있도록 별도의 객체(ShopMenu, ShopReview..)들을 구성하였고, 이 값들을 전달받은 Bulk processor는 Shop객체로 전환하여 buffer에 저장을 하도록 구성하였습니다.(이 부분 코드 및 활용은 튜닝2에서 다룰 예정) 그리고 별도의 serializer 정책을 적용해서 flush 주기에 BulkProcessorHandler에 데이터를 전달하여 필요한 부분만 업데이트 될 수 있도록 BulkRequest를 생성하는 등의 작업을 진행하였습니다.
Bulk processor 도입으로 인한 효과를 이론적으로 생각했던 부분이었고 테스트를 통해 검증도 해봤지만 실제 운영에서도 어느 정도 효과가 발생될지 궁금했었습니다. 기대감을 가지고 운영에서 확인해봤습니다.
운영 데이터 기준 이벤트 수신 건수는 총 9,261,187개 였습니다.
Bulk processor 도입전에는 모든 이벤트를 단건으로 처리하였기 때문에 총 update request는 이벤트 수신건수와 동일하게 9,261,185개 였습니다.
Bulk processor 도입후에는 update request를 모아 Bulk request를 만들면서 request건수는 233,949건 발생하였습니다.
도입 전 : 9,261,185건
도입 후 : 233,949건
Elasticsearch에 요청하는 request 건수가 총 97.5% 감소하였습니다. 이로 인해 write thread pool 감소로 많은 이벤트 수신 시 발생하던 rejected가 해소되었고, bulk로 단일 요청 대비 응답 대기 시간 및 네트워크 부하 감소 효과를 받았습니다.
튜닝 2.
튜닝 1에서 얻은 효과도 좋았지만 조금 더 성능을 올려보고 싶었습니다. Bulk request가 single request보다 효능은 있지만 Bulk의 사이즈가 커질수록 오히려 Elasticsearch에 부담을 줄 수 있기 때문에 Bulk에 담기는 request를 더 줄여보고 싶었습니다.
데이터를 가만히 보니 검색에서 사용하는 모든 데이터는 shopId를 기준으로 업데이트 쿼리가 만들어졌습니다. 그럼 request를 add 하는 순간에 동일한 가게에 대한 request가 존재하면 변경되는 부분만 기존 request에 넣어주면 되겠다는 생각을 가지게 되었습니다.
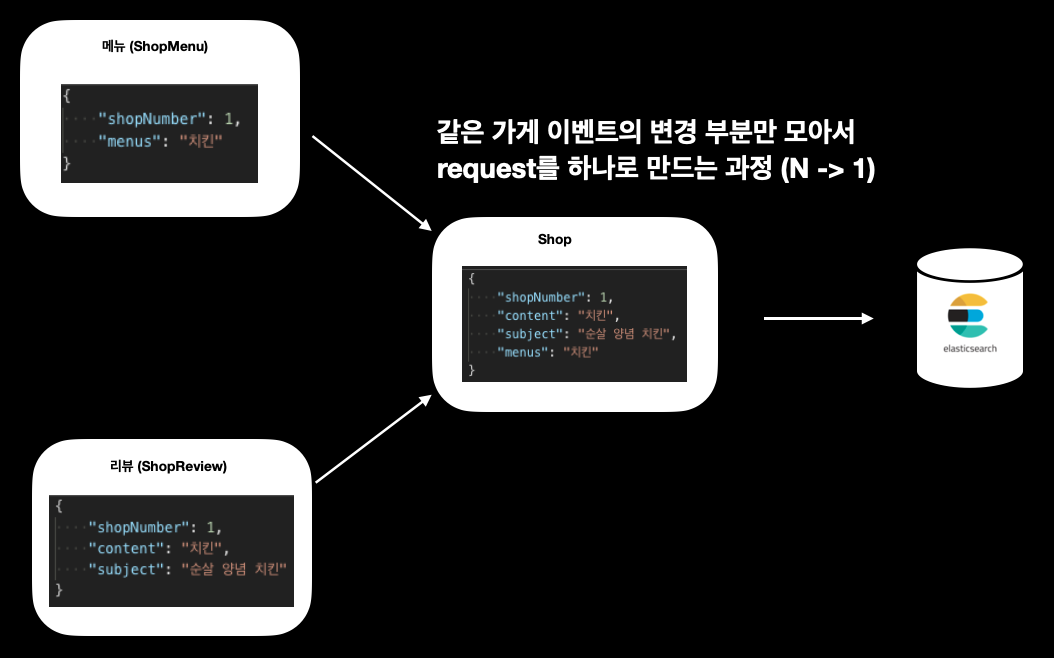 가게 중심으로 request 단일화 과정
가게 중심으로 request 단일화 과정
그래서 다음과 같이 Bulk processor에 buffer역할을 하는 map의 키를 shopId로 부여하고 value를 Shop 객체로 부여를 하였고 각 이벤트를 통해 들어오는 요청을 하나의 Shop으로 묶어서 Bulk request를 만들도록 진행하였습니다.
# 실제 코드는 더 복잡하여 예시 코드를 기재합니다.
/**
* data는 유연하게 받을 수 있도록 제네릭을 사용하였고, 실제 검색에서는 Shop객체를 받고 있다.
* acknowledgments는 수신된 이벤트들에 대한 정상 처리 여부에 따라 sqs에 ack 처리를 하기 위해 보관
*/
@Getter
@Setter
@NoArgsConstructor
public class BulkData<T extends IndexDomain> {
private T data;
private Set<Acknowledgment> acknowledgments;
@Builder
public BulkData(T data, Set<Acknowledgment> acknowledgments) {
this.data = data;
this.acknowledgments = acknowledgments;
}
}
@Getter
@Setter
public class Shop extends IndexDomain {
private Long shopNumber;
private List<Menu> menus;
private String content;
private String subject;
@Builder
public Shop(Long shopNumber, List<Menu> menus, String content, String subject) {
this.shopNumber = shopNumber;
this.menus = menus;
this.content = content;
this.subject = subject;
}
}
// 이벤트 변경정보를 가지는 객체의 공통 추상 클래스
public abstract class ShopUpdatableDomain extends UpdatableDomain<Shop> {
@Override
public Shop convert() {
Shop shop = Shop.builder().build();
convert(shop);
return shop;
}
}
// 메뉴 변경정보를 가지고 있는 ShopMenu
@Getter
@Setter
@NoArguments
public class ShopMenu extends ShopUpdatableDomain {
private Long shopNumber;
private List<Menu> menus;
@Builder
public ShopMenu(Long shopNumber, List<Menu> menus) {
this.shopNumber = shopNumber;
this.menus = menus;
}
@Override
public void convert(Shop shop) {
shop.setShopNumber(shopNumber);
shop.setMenus(menus);
}
}
// 리뷰 변경정보를 가지고 있는 ShopReview
@Getter
@Setter
@NoArguments
public class ShopReview extends ShopUpdatableDomain {
private Long shopNumber;
private String content;
private String subject;
@Builder
public ShopReview(Long shopNumber, String content, String subject) {
this.shopNumber = shopNumber;
this.content = content;
this.subject = subject;
}
@Override
public void convert(Shop shop) {
shop.setShopNumber(shopNumber);
shop.setContent(content);
shop.setSubject(subject);
}
}
// 이벤트 수신과 Bulk processor에 이벤트 내용 전달
@SqsListener(value = "menu-sqs", deletionPolicy = NEVER)
public void shopMenuV3UpdateListen(@Payload ShopMenuEvent eventDto, Acknowledgment acknowledgment) {
bulkProcessor.add(BulkProcessorBucket.<ShopMenu>builder()
.data(ShopMenu.builder()
.shopNumber(eventDto.getShopId())
.menus(eventDto.getMenus())
.build())
.build());
}
...
@SqsListener(value = "reviewSqs", deletionPolicy = NEVER)
public void tagsUpdateListen(@Payload ReviewChangeEvent reviewChangeEvent, Acknowledgment acknowledgment) {
bulkProcessor.add(BulkProcessorBucket.<ShopReview>builder()
.data(ShopReview.builder()
.shopNumber(eventDto.getShopId())
.content(eventDto.getContent())
.subject(eventDto.getSubject())
.build())
.build());
}
// bulk processor add 코드
@Slf4j
public class BulkProcessor<S extends IndexDomain> implements Closeable {
private Map<String, BulkData<S>> datas;
...
..
...
private synchronized void addData(BulkProcessorBucket request) {
String id = request.getData().idValue();
// bulk buffer안에 동일한 가게가 존재하는지 조회
if (this.datas.containsKey(id)) {
BulkData<S> bulkData = this.datas.get(id);
// 들어온 이벤트 데이터를 기존 shop 변경분 정보의 매핑
request.getData().convert(bulkData.getData());
return;
}
this.datas.put(id, BulkData.<S>builder()
.data((S) request.getData().convert())
.build());
}
...
..
.
}
해당 튜닝 포인트도 효과가 있었습니다. Bulk request를 만들어서 flush하는 주기에 같은 가게 아이디로 묶이는 이벤트 종류별 건수와 횟수에 대한 정보는 아래와 같이 적지 않은 수치를 볼 수 있었으며 실제로 이에 대한 효과도 볼 수 있었습니다.
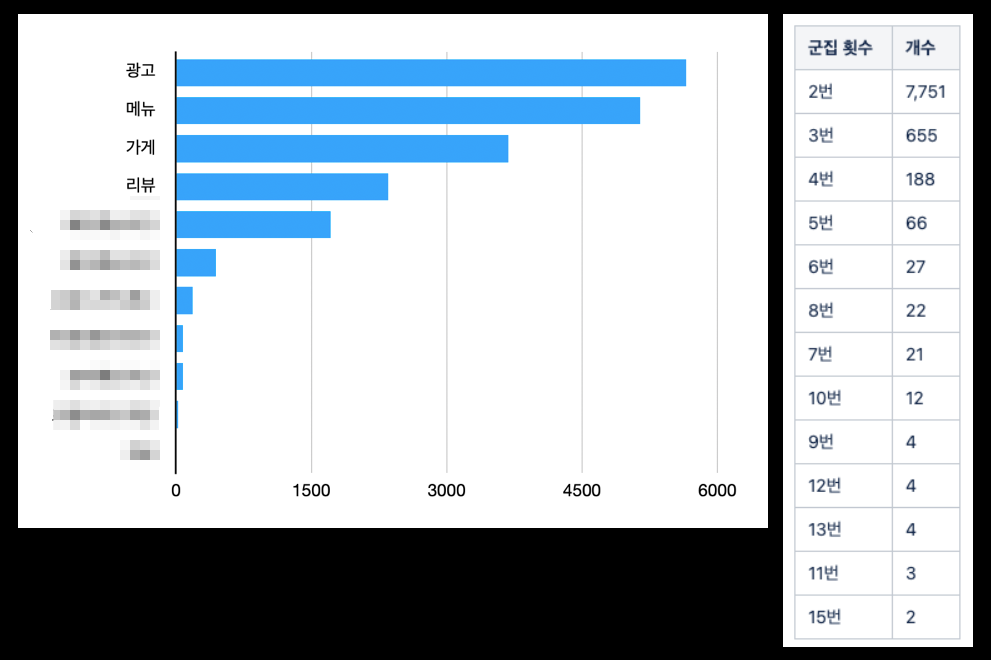 request 군집 지표
request 군집 지표
성능 테스트 및 실제 운영 리소스 변화
성능테스트 결과
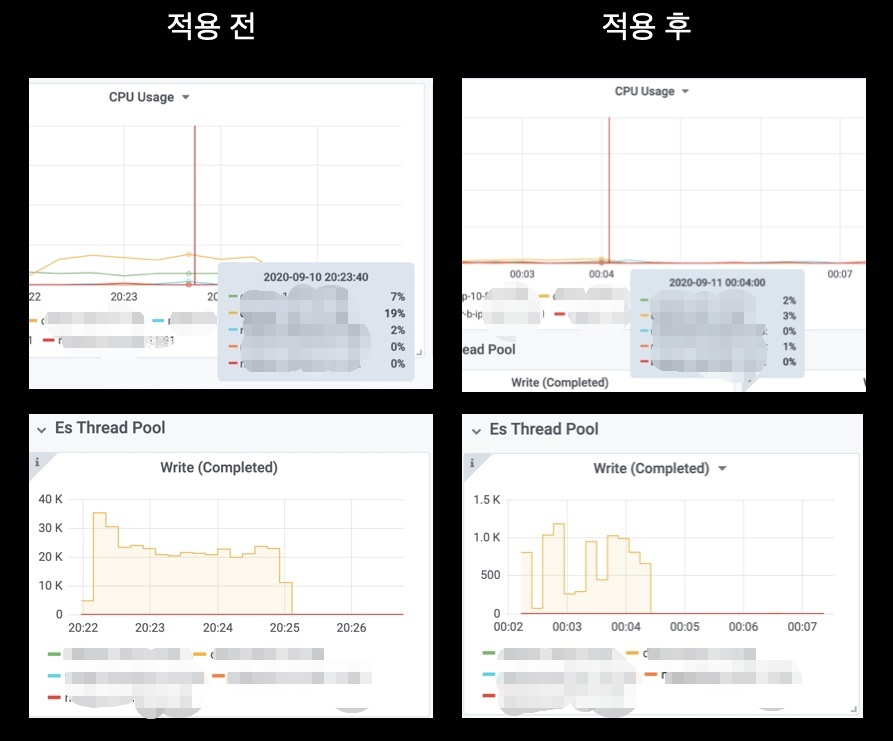 27만건 무작위 이벤트 테스트 결과
27만건 무작위 이벤트 테스트 결과
27만 건의 데이터를 무작위로 전송했고 리소스 변화량을 체크해봤습니다.
CPU 사용량은 15% 이상 감소되었고 request 단위가 작아지면서 write complete 수도 30배 정도 감소하는 효과를 얻었습니다.
운영 결과
실제 운영에 적용 결과 위의 처음 문제가 발생하던 시기에 피크시간 기준 61%를 육박하던 cpu가 비교 대상 기준 이벤트가 수십만건이 더 추가되었음에도 불구하고 최대 29%정도의 안정적인 상태를 유지하고 있습니다.
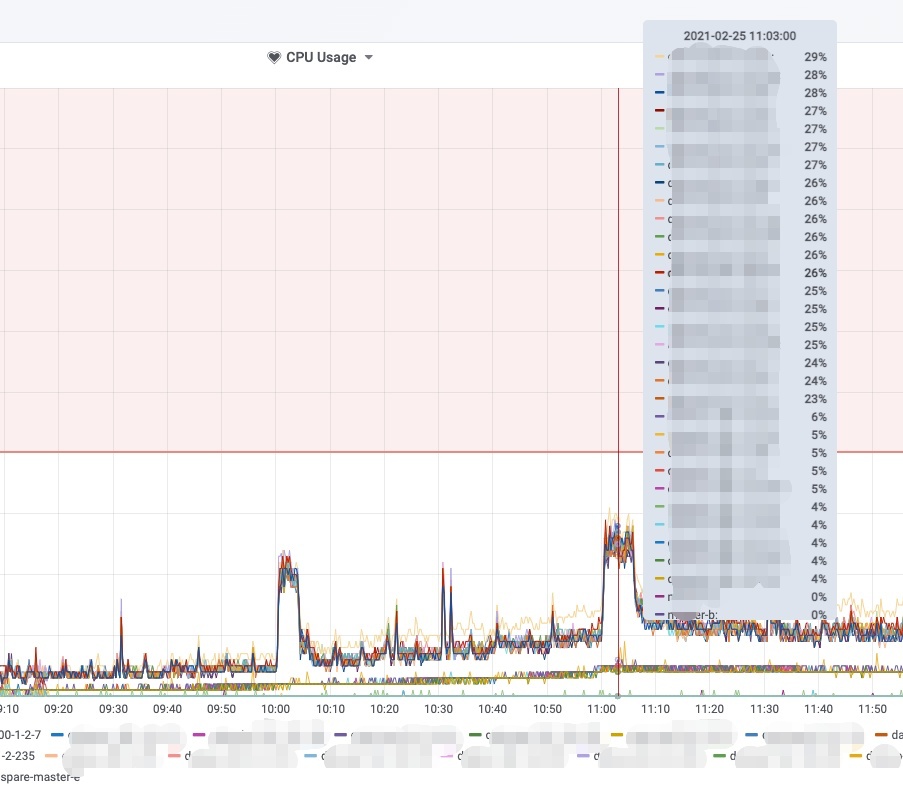 안정된 시스템
안정된 시스템
이 문제 해결로 배달 빠른 순, 배달팁 낮은 순과 같이 실시간성 데이터가 들어가야하는 서비스가 적용될 수 있었고 고객에게 더 좋은 가치를 드리는게 가능해졌습니다.
2021년에는 검색창이 하단으로 옮겨지고 인기 검색어 지면 등 많은 기능들이 추가되고 있습니다. 이 글을 읽고 모든 코드를 보고 싶거나, 검색개발팀에 관심이 생겼다면 [배민서비스실] 검색서비스 개발자 모집 에 많은 지원 부탁드립니다.
긴 글 읽어주셔서 감사드립니다.