병아리 개발자의 걸음마 한 발짝 (feat. 파일럿 프로젝트)
• 최태현

지원서에서 발췌한 내용
…
나름대로 제일 좋은 방법이라고 생각했던 해결책이 경험 많은 개발자분들이 보시기에는 어떤지, 시니어 개발자분들은 문제가 생겼을 때 어떻게 접근하고 어떻게 해결하는지 등도 항상 궁금해 왔습니다.
…
파일럿 프로젝트를 하며 조심스레 내린 코드리뷰의 정의
코드리뷰란,
나름대로 제일 좋은 방법이라고 생각했던 해결책이
제일 좋은 방법이 아닐 수 있다는 것을 깨닫게 되는 고된 시간동시에,
새로운 시각과 생각하지 못했던 방향을 접하며
우아한 개발자가 되기 위해 한층 더 성장할 수 있는 소중한 시간
들어가며
안녕하세요! 정산시스템 팀에 병아리 신입 개발자로 입사한 최태현입니다.

입사 후, 한 달 반 정도 신입 개발자의 팀 적응을 위한 파일럿 프로젝트를 진행했습니다.
정산 어드민 페이지를 처음부터 끝까지 만들며 새롭게 배우게 된 것들, 그리고 그 과정에서 느낀 점들을 공유해 드리려고 합니다!
많은 분들께 너무 당연한 내용일 수 있겠지만, 주니어 개발자의 귀여운 걸음마 한 발짝 이라고 봐주시면 감사드리겠습니다!
1,2주차 : 이때까진 잘 만든줄 알았다…
1, 2주차 과제로는 간단한 정산 어드민 페이지의 화면과 서버를 구현해야 했습니다.
이때 구현해야 하는 필수 기능과 필수 기술, 몇 가지 선택 조건은 아래와 같았습니다.
- 필수 기능
- 회원 기능
- 업주 관리 기능
- 매출 관리 기능
- 지급 관리 기능
- 필수 기술
- 객체지향적인 코드
- 클린 코드
- 단위 테스트, 통합 테스트
- RESTful API
- Spring Boot 2.x
- JPA
- Gradle
- Lombok
- Git & Github, Git Flow
- Jira
- H2
- 선택 조건
- Querydsl
- Sprnig Security
- Spring REST Docs
주어진 시간 내에 필수 기술을 사용하여 필수 기능을 모두 구현하고,
처음 보는 Querydsl이나 Spring REST Docs를 적용해보기도 했습니다.
그렇게 10일여가 훌쩍 지나게 되고….
두근두근 대망의 첫 코드리뷰시간!

코드리뷰의 정의에 알맞게 고되며 소중한 시간이었습니다 ㅎㅎ
정말 정말 많은 피드백을 받았는데요, 많은 피드백을 크게 두 가지 카테고리로 정리해 보았습니다.
운영을 해보면!
두 카테고리 중 첫 번째는 운영과 관련된 피드백입니다!
먼저 Entity와 관련된 내용입니다.
As-Is
@Getter
@NoArgsConstructor(access = AccessLevel.PROTECTED)
@Entity
public class Sales extends DateTimeEntity { // (1)
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
@ManyToOne(fetch = FetchType.LAZY, optional = false) // (2)
@JoinColumn(name = "owner_id", nullable = false)
private Owner owner;
@OneToMany(mappedBy = "sales", cascade = CascadeType.ALL, orphanRemoval = true)
private List<SalesDetail> salesDetailList = new ArrayList<>();
// (3)
@Column(name = "item", length = 15, nullable = false)
private String item;
private long totalSales;
private long settlement;
private boolean paid;
// (4)
private LocalDateTime deletedDateTime;
/* 빌더와 public method 생략 */
}
- 엔티티의 생성 시점과 변경 시점을 JPA Auto Auditing으로 추적하기 위해
@CreatedDate와@LastModifiedDate를 사용했습니다.- 두 어노테이션을 가지고 있는 칼럼은
DateTimeEntity에 넣어두었고,@MappedSuperclass를 활용하여 모든 엔티티에 공통적으로 적용하도록 했습니다. (혹시나 JPA Auto Auditing 적용이 궁금하시다면 여기에서 잘 알려줘요 ㅎㅎ) - 하지만 이렇게 하니 “YYYY-MM-DD ~ YYYY-MM-DD의 매출 정보”와 같은 요구사항을 테스트 할 수 없었습니다!
- Auto Auditing 기능을 사용하면 해당 칼럼은 수정할 수 없었기 때문입니다.
- 실제로 리뷰 당시 관련 요구사항 테스트 코드는 작성되지 않은 상태였습니다.
- 두 어노테이션을 가지고 있는 칼럼은
- 코드 리뷰에서 나온 질문 1)
optional옵션은 왜 넣으셨나요? - 코드 리뷰에서 나온 질문 2)
length는 왜 15로 넣으셨나요? - Soft delete를 하기 위해
deletedDateTime이라는 column을 만들었습니다.deletedDateTime이 null이면 삭제되지 않은 Sales, null이 아니면 삭제된 Sales로 간주되도록 했습니다
To-Be
@Getter
@NoArgsConstructor(access = AccessLevel.PROTECTED)
@Entity
public class Sales extends DateTimeEntity {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
@ManyToOne(fetch = FetchType.LAZY) // (2)
@JoinColumn(name = "owner_id", nullable = false)
private Owner owner;
@OneToMany(mappedBy = "sales", cascade = CascadeType.ALL, orphanRemoval = true)
private List<SalesDetail> salesDetailList = new ArrayList<>();
// (3)
@Column(name = "item", nullable = false)
private String item;
private long totalSales;
private long settlement;
// (1)
@Column(nullable = false)
private LocalDateTime occurDateTime;
// (4)
}
- 비즈니스 로직에서 필요한 column은 별도로 만들어 처리하는 것이 좋다는 피드백을 받았습니다.
- 비즈니스 로직에 JPA가 자동 생성해주는 column을 사용할 수는 없으니까요.
- 새로운 column을 추가해 줌으로써 테스트 코드도 작성할 수 있게 되었습니다
- 습관처럼 사용했던 옵션을 다시 적용하다보니
optional = false를 사용한 정확한 이유에 대해 답하기 어려웠습니다.- 피드백 이후 다시 찾아본 결과,
optional은 연관관계를 맺는 객체가 null이어도 되는지, null이면 안되는지는 설정하는 옵션이었습니다. - 옵션 하나라도 다시 한 번 꼼꼼하게 확인해봐야 겠다는 생각을 할 수 있었습니다!
- 피드백 이후 다시 찾아본 결과,
- 15라는 문자열 길이 제한을 둔 이유는 딱히 없었습니다.
- 하지만 이렇게 문자열 길이에 제한을 주게 되면 추후 길이 제한을 확장하거나 제거하게 되었을 때 수천만, 수억건의 데이터가 들어 있는 테이블의 스키마를 변경해야 합니다.
- 데이터가 많을 수록 적용되는 시간은 (끔직할거에요…)
- 그렇기 때문에 처음에 문자열 길이 제한은 넉넉하게 하는 것이 좋다는 피드백을 받았습니다.
deletedDateTime은 2가지 역할을 하고 있었습니다.- 해당 데이터가 삭제되었는지, 삭제되지 않았는지를 판별하고
- 삭제된 시간을 기록하고 있었습니다.
- 이 2가지 역할은 서로 분리하는 것이 좋다는 피드백을 들었습니다.
- 또한, null은 index에 사용할 수 없기 때문에 null이 들어가는 column으로 FLAG 역할을 하는 것보다 DeletedSales와 같은 별도의 테이블을 만들어 삭제된 Sales를 쌓는것이 좋다는 피드백을 들었습니다.
Controller와 관련해서 받았던 피드백도 있었습니다.
As-Is
@RestController
@RequestMapping(value = Route.auth) // (1)
@RequiredArgsConstructor
public class AuthController {
private final AuthService authService;
@RequestMapping(value = "/signup", method = RequestMethod.POST) // (1)
public boolean signup(@RequestBody SignupRequestDto signupRequestDto) { // (2)
...
return true;
}
}
- 클래스 레벨의
@RequestMapping과 메소드 레벨의@RequestMapping으로 구분하여 URL을 써 놓으면 IDE로 특정 API를 검색하기 어렵다는 피드백을 받았습니다.- 만약, /api/v2/user/signup 이라는 Full URL을 적어 두었다면 IDE로 문자열을 검색해 해당 API를 처리하는 메소드로 바로 찾아갈 수 있겠죠!
- 또한, 모든 메소드들에
@RequestMapping이라는 같은 어노테이션이 있어 HTTP method를 한 눈에 보기 어려울 수 있다는 피드백도 있었습니다.
- API의 응답값으로 성공 여부에 대한 true / false를 반환하려 했습니다.
- 하지만 실패하는 경우에는 unchecked exception을 터뜨리도록 되어 있어 성공하면 무조건 HTTP Status 200이 반환되는 상황이었습니다.
// unchecked exception 예시
User user = userRepository.getUser(name);
if (user != null) {
throw UserNotExistsException(String.format("User [name=%s] does not exist", name));
}
To-Be
@RestController
@RequiredArgsConstructor
public class AuthController {
private final AuthService authService;
@PostMapping("/api/v1/auth/signup") // (1)
public void signUp(@RequestBody SignupRequestDto signupRequestDto) { // (2)
...
}
}
- 클래스 레벨의
@RequestMapping을 제거하고 method에 Full URL을 써주었습니다.- 이렇게 되면 특정 API에서 에러가 났을 때도 Full URL 검색을 이용해 수 많은 API중 특정 API를 바로 찾을 수 있다는 장점이 있습니다.
- 또한
@PostMapping이나@GetMapping과 같이 HTTP method를 바로 알 수 있도록 해주었습니다.
- HTTP Status만으로도 성공 여부를 전달할 수 있어 boolean을 반환하지 않도록 변경했습니다.
유지보수가 쉬운 코드!
두 번째 카테고리는 객체지향입니다.
피드백을 받기 전의 코드는 대부분 절차지향적이었습니다.
Spring Boot의 Controller, Service, Repository, Entity, DTO의 역할을 작게나마 구분하고 있었지만, 이들을 각각의 객체로 생각하고 로직이 적절히 분산되었다기보단 Service에서 대부분의 변환이나 가공을 처리하고 있었습니다.
예를 들어, 매출 정보 다수를 가공해야 하는 기능이 있다면, Repository에서 List<Sales>를 Service로 반환하여 Service에서 모든 계산과 가공을 하고 DTO를 만들고 있었습니다.
또 다른 예로 Entity를 만들 때도, Controller에서 DTO를 열어 각 필드를 Service로 넘겨주면 Service가 Entity를 직접 만들어 저장하고 있었습니다.
// Controller
@RequestMapping(value = "", method = RequestMethod.POST)
public boolean createSales(@RequestBody SalesCreateRequestDto salesCreateRequestDto) {
String ownerName = salesCreateRequestDto.getOwnerName();
String item = salesCreateRequestDto.getItem();
long totalSales = salesCreateRequestDto.calculateTotalSales();
long totalPayment = salesCreateRequestDto.calculateTotalPayment();
Map<PaymentMethodType, Long> salesDetailMap = salesCreateRequestDto.getSalesDetailMap();
salesService.createSales(ownerName, item, totalSales, totalPayment, salesDetailMap);
return true;
}
// Service
@Transactional
public void createSales(String ownerName, String item, long totalSales, long settlement,
Map<PaymentMethodType, Long> salesDetailMap) {
// 1. Get Owner
Owner owner = ownerService.getOwner(ownerName);
// 2. Create sales
Sales newSales = Sales.builder()
.owner(owner)
.salesDetailList(createSalesDetailList(salesDetailMap))
.item(item)
.totalSales(totalSales)
.settlement(settlement)
.build();
salesRepository.save(newSales);
}
이런 사태(?)를 보신 돌보미 님께서는 특약 처방으로 책 오브젝트를 추천해 주시며 3주차에 전체적인 리팩토링을 해보는 것이 어떻겠냐고 말씀해 주셨습니다.
(아아 책 하나까지 섬세하게 골라주시는 갓 돌보미님… 돌보미님에 대한 훈훈한 미담은 파도파도 계속 나오는데…)
3주차 : 들어는 봤었지, 객체지향!
사실 파일럿 프로젝트를 시작 하기 전에도 객체지향이라는 말을 많이 들어보았고, JAVA라는 언어가 OOP(Object Oriented Programming, 객체지향 프로그래밍)를 지향하는 것도 알고 있었습니다.
하지만
- 상속을 이용하면 코드를 재활용해서 깔끔해지고 객체지향적이지~
- 필드는 private으로 만들고 getter/setter만 만들면 좋은 캡슐화인걸?
라고만 생각했었습니다.
이런 저에게 돌보미님이 추천해주신 책 오브젝트는 저의 잘못된 생각을 완전히 바로 잡아 주었습니다.
당연히 책의 내용을 다 말씀드릴 수는 없지만, 상속과 캡슐화 그리고 객체지향에 대해서 오브젝트는 이렇게 말하고 있습니다.
(꼭 읽어보셨으면 좋겠습니다 너무 감명 깊게 읽은 책이에요!)
대부분의 사람들은 코드 재사용을 상속의 주된 목적이라고 생각하지만 이것은 오해다. 인터페이스를 재사용할 목적이 아니라 구현을 재사용할 목적으로 상속을 사용하면 변경에 취약한 코드를 낳게 될 확률이 높다. 코드 재사용을 위해서는 상속보다는 합성이 더 좋은 방법이다.
캡슐화의 목적은 변경하기 쉬운 객체를 만드는 것으로, 캡슐화란 “변할 수 있는 어떤 것이라도 감추는 것”이다. private필드와 getter / setter를 사용하는 것은 직접 객체의 내부에 접근할 수 없기 때문에 캡슐화의 원칙을 지키고 있는 것처럼 보인다. 하지만 안타깝게도 접근자와 수정자 메소드는 객체 내부의 상태에 대한 어떤 정보도 캡슐화 하지 못한다
훌륭한 객체지향 설계란 소프트웨어를 구성하는 모든 객체들이 자율적으로 행동하는 설계를 가리킨다. 협력을 수행하기 위해 적절한 객체에 적절한 책임을 할당하는 것이 핵심이다.
이 책을 보며 List<Sales>만 가지고 있는 일급 컬렉션을 만들어 List<Sales>에 대한 가공을 맡긴다는 발상을 할 수 있었고, DTO와 Entity가 1:1 대응이 된다면 각 객체에게 서로의 변환을 맡길 수 있다는 생각도 할 수 있었습니다.
또한, Controller에서 DTO를 연다는 것은 Controller 부터 DTO 변경에 취약해진다는 것을 깨달았습니다!
덕분에 [코드 1]은 아래와 같이 변하게 되었습니다.
// Controller
@PostMapping("/api/v1/admin/sales")
public void createSales(@RequestBody SalesCreateRequestDto salesCreateRequestDto) {
salesService.saveSales(salesCreateRequestDto);
}
// Service
@Transactional
public void saveSales(CreateSalesDto createSalesDto) {
Owner owner = ownerService.getOwner(createSalesDto.getOwnerName());
salesRepository.save(createSalesDto.toEntity(owner));
}
이 외에도 모든 메소드에 주석을 의무적으로 적으려 하거나
함수에서 여러 가지 일을 한 번에 처리하려 하는 것을
돌보님께서 추천해주신 또 다른 책을 참고하며 개선할 수 있었습니다
(고마워요 Clean Code!)
테스트 코드 피드백
3주차에는 테스트 코드에 대한 피드백도 이어졌습니다.
아래 코드를 예시로 들어 보이겠습니다.
As-Is
@Test
@Transactional // (1)
public void createSalesTest() throws Exception {
// given
// (2) (3)
SalesCreateRequestDto salesCreateRequestDto = TestUtil.createSalesCreateRequestDto("김철수",
TestUtil.createSalesDetailMap(1000, 1000, 1000, 0, 0));
// when
mockMvc.perform(post("/api/v1/admin/sales")
.header("Authorization", TestUtil.adminJWT)
.contentType(MediaType.APPLICATION_JSON)
.content(objectMapper.writeValueAsString(salesCreateRequestDto)))
.andDo(print())
.andExpect(status().isOk());
// then
Sales sales = salesRepository.findAll().get(0);
// (4)
assertThat(sales.getOwner().getName(), is("김철수"));
assertThat(sales.getTotalSales(), is(3000L));
assertThat(sales.getSettlement(), is(2000L));
assertThat(sales.getSalesDetailList().get(0).getAmount(), is(1000L));
assertThat(sales.getSalesDetailList().get(1).getAmount(), is(1000L));
assertThat(sales.getSalesDetailList().get(2).getAmount(), is(1000L));
assertThat(sales.getSalesDetailList().get(3).getAmount(), is(0L));
assertThat(sales.getSalesDetailList().get(4).getAmount(), is(0L));
}
@Transactional
먼저, 테스트 코드에서는 @Transactional을 제외하는 것이 좋다는 피드백을 받았습니다. (1번 주석)
- 테스트 코드에 @Transactional이 있으면 전파 효과 때문에 원하는 테스트가 정확히 검증되지 않을 수 있기 때문입니다.
- 예를 들어, @Transactional을 붙이지 않으면 영속성 컨텍스트의 dirty checking 기능이 작동하지 않게 됩니다.
- 그런데 실수로 엔티티를 업데이트하는 메소드에는 @Transactional을 붙이지 않고 이 메소드를 테스트 하는 코드에 @Transactional을 붙였다면 테스트를 통과하게 됩니다.
@Transcational을 테스트 코드에 넣었던 이유는 assertThat 문에 있는
sales.getOwner()에서 나오는 LazyInitializationException 해결하기 위해서였습니다.
LazyInitializationException이 나오는 이유는 이렇습니다.
- 테스트 코드에 @Transactional이 없다면, 영속성 컨텍스트가 @Transactional이 있는 service 메소드 호출이 끝날 때 종료되고
- Sales 객체에 연관관계로 존재하는 Owner 객체는 LAZY fetch 전략이기 때문에 Proxy 객체 입니다
- 따라서 실제로 Owner를 get하게 될 때 원래는 영속성 컨텍스트가 조회 쿼리를 한 번 더 날려 진짜 객체를 가져와야 하는데 영속성 컨텍스트가 존재하지 않아 LazyInitializationException가 나오게 됩니다.
이때 @Transactional을 대체할 수 있는 방법은 2가지가 있습니다.
- Lazy fetch 전략을 Eager fetch 전략으로 변경한다
- fetch join을 사용한다
저는 fetch join을 사용했습니다!
Clean Test Code
또한, 클린 테스트 코드 작성법에 대한 피드백도 받았습니다.
현재 TestUtil이라는 클래스는 테스트에 필요한 각종 DTO나 Entity를 만들어 주고 있습니다. (2번 주석)
- 이렇게 되면 Entity가 늘어날 수록
TestUtil이라는 클래스는 너무 거대해지게 되고, TestUtil이라는 이름 자체도 애매해집니다.- 따라서 Entity 별로
SalesCreator혹은SalesDtoCreator와 같은 유틸성 클래스를 만드는 것이 좋습니다.
- 따라서 Entity 별로
매출에 대한 결제 수단별 세부 정보를 표현하는 방법(createSalesDetailMap(1000, 1000, 1000, 0, 0))이 한 눈에 알아보기 어렵습니다. (3번 주석)
- 따라서 결제 수단별로 결제 금액이 얼마인지 조금 더 명확하게 확인할 필요가 있습니다.
assertThat을 길게 반복적으로 사용하는 것보다는 assertSales와 같은 메소드를 만들어 다른 테스트에서도 함께 사용하는 것이 좋습니다. (4번 주석)
[코드 2]에 fetch join을 적용해 @Transactional을 제거하고 조금 더 클린하게 바꾸면 이렇습니다!
To-Be
@Test
public void createSalesTest() throws Exception {
// given
String expectedOwnerName = "김철수";
List<PaymentMethodAmountPair> expectedSalesDetail =
Array.asList(PaymentMethodAmountPair.of(PaymentMethodType.CARD, 1000L),
PaymentMethodAmountPair.of(PaymentMethodType.PHONE, 1000L),
PaymentMethodAmountPair.of(PaymentMethodType.COUPON, 1000L))
SalesCreateRequestDto salesCreateRequestDto =
SalesDtoCreator.createRequest(expectedOwnerName, expectedSalesDetail);
// when
mockMvc.perform(post("/api/v1/admin/sales")
.header("Authorization", adminJWT)
.contentType(MediaType.APPLICATION_JSON)
.content(objectMapper.writeValueAsString(salesCreateRequestDto)))
.andDo(print())
.andExpect(status().isOk());
// then
Sales salesFromDB = salesRepository.findAll().get(0);
Sales sales = salesRepository.getSalesFetch(salesFromDB.getId());
assertSales(sales, expectedOwnerName, expectedSalesDetail);
}
추가적인 피드백~
이 외에도,
- Spring REST Docs 생성용 mocking 테스트와 실제 Controller부터 시작되는 통합 테스트는 분리하는 것이 좋다
- service 계층은 mocking하는 테스트도 있으면 좋지만, 이보다는 service 메소드의
@Transcational시작 ~ 끝 을 테스트 하는 것이 우선순위가 높다
등등의 피드백을 받았습니다!
4주차 : multi-project가 도입된다면?
3주차 기록에서 저는 이렇게 말씀드렸습니다.
Entity가 DTO를 만들도록 변경했다
하지만 이는 3주차까지 단일 프로젝트였기 때문에 발견하지 못했던 문제였습니다.
단일 프로젝트라도 Entity가 DTO를 만드는 것은 좋지 않습니다!
두근세근네근 4주차의 주제는 바로 멀티 프로젝트였습니다!
멀티 프로젝트로 바뀌게 되면은 Core 모듈에 있는 Entity는 API 모듈에 있는 DTO를 모르기 때문에 Entity가 DTO를 만들 수 없게 됩니다.

4주차에서도 단백질 보충제같은 피드백은 이어졌습니다!
멀티 프로젝트가 도입되면 프로젝트 root에 다양한 모듈들이 생길 수 있기 때문에 이름을 비슷하게 만들어 한 쪽으로 모는 것이 관리하기 용이하다 라는 작은 꿀팁부터 java-library 플러그인에서 제공하는 configuration, api와 implementation의 차이를 이용한 모듈별 의존성 설정까지~
많은 피드백을 듣고 더 나은 빌드 스크립트를 작성할 수 있었습니다!
// 프로젝트 루트 build script 중 일부
// 공통되어 설정할 수 있는 것, 플러그인 등은 하나로 모은다!
subprojects {
group "com.lannstark"
version "1.0.0"
apply plugin: 'java-library'
apply plugin: 'org.springframework.boot'
apply plugin: 'io.spring.dependency-management'
sourceCompatibility = 1.8
repositories {
mavenCentral()
}
dependencies {
// lombok과 spring-boot-starter-test 처럼 모든 모듈에서 사용하는 의존성 설정
implementation('org.projectlombok:lombok')
annotationProcessor('org.projectlombok:lombok')
implementation('org.springframework.boot:spring-boot-starter-test')
}
}
// core 모듈 build script 중 일부
bootJar { enabled = false }
jar { enabled = true }
dependencies {
runtimeOnly('com.h2database:h2')
// core 모듈을 사용하는 다른 모듈들이 JPA를 사용할 수 있도록 api로 설정
api('org.springframework.boot:spring-boot-starter-data-jpa')
runtime('mysql:mysql-connector-java')
}
또한 한 가지 놀라운 사실을 알게 되었는데요,
vue 기반 frontend를 build하면 나오는 static 파일을 jar 안에 넣어서 jar 파일 배포 한 번만으로 웹 애플리케이션을 구동할 수 있다는 것이었습니다!
이 사실을 알기 전 저는 frontend 파일을 빌드하여 Nginx를 이용해 배포했고,
Spring Boot 서버는 jar 파일로 만들어 별도로 배포하였습니다.
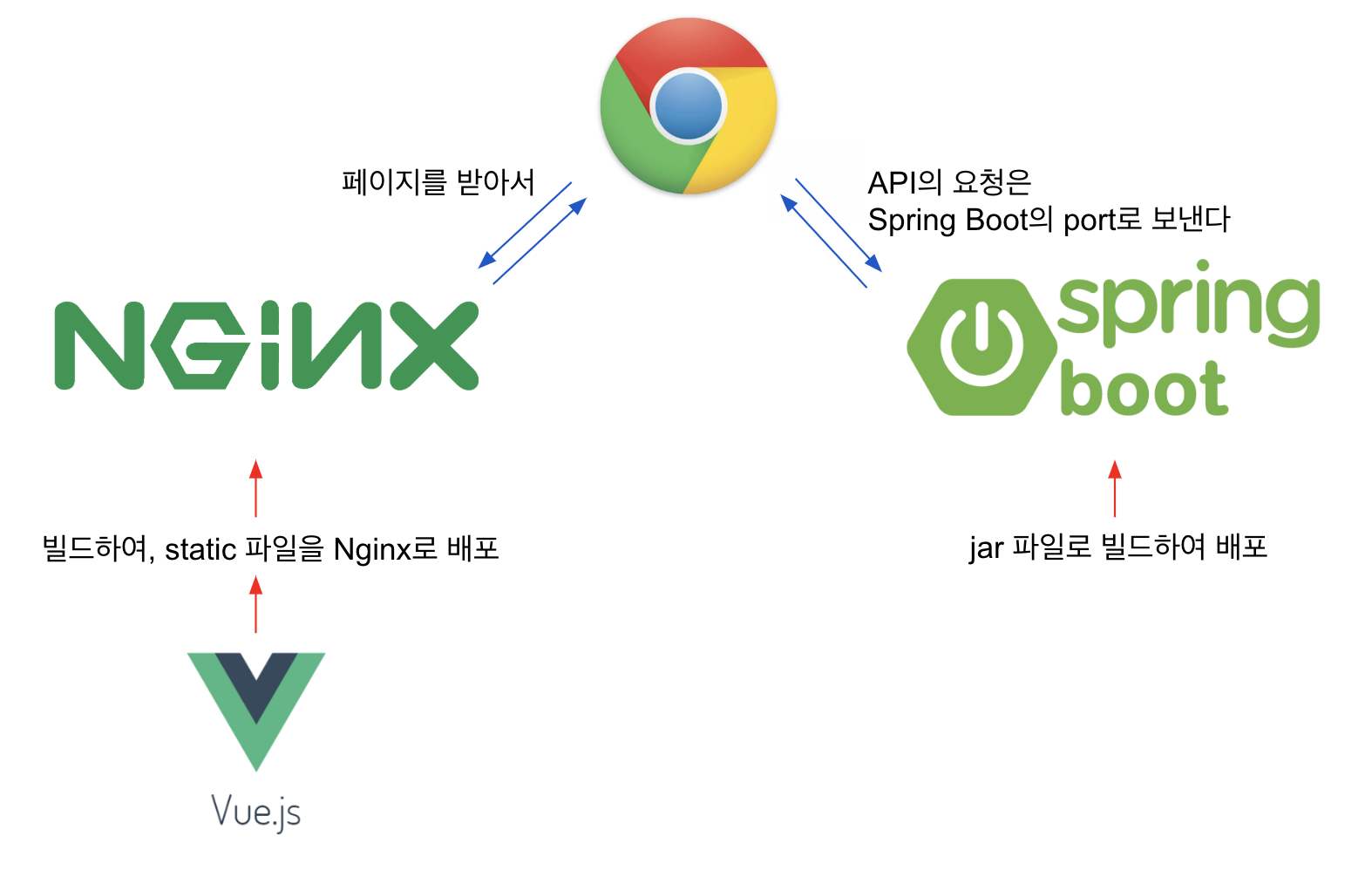
이 방법은 두 가지 문제점이 있습니다.
- 프론트엔드 배포와 백엔드 배포를 둘 다 고려해야 합니다.
- Nginx 설정도 해줘야 하고 프론트 배포 스크립트도 만들어야하고, 서버는 서버대로 배포 스크립트를 만들어야 하고…
- 이러한 번거로움이 있습니다.
- 또한 이슈가 발생하면 Nginx 설정과 서버 설정을 모두 확인해주어야 하죠.
- Nginx 설정도 해줘야 하고 프론트 배포 스크립트도 만들어야하고, 서버는 서버대로 배포 스크립트를 만들어야 하고…
- 서버에 CORS 설정을 해주어야 합니다.
- CORS 설정을 해주어야 한다는 번거로움도 있지만
- 잘못 설정할 경우 보안상 취약할 수 있다는 단점도 존재합니다.
이 두 가지 문제점은 static 파일을 jar 안에 넣어 한 번에 배포함으로써 해결할 수 있었던 것입니다!
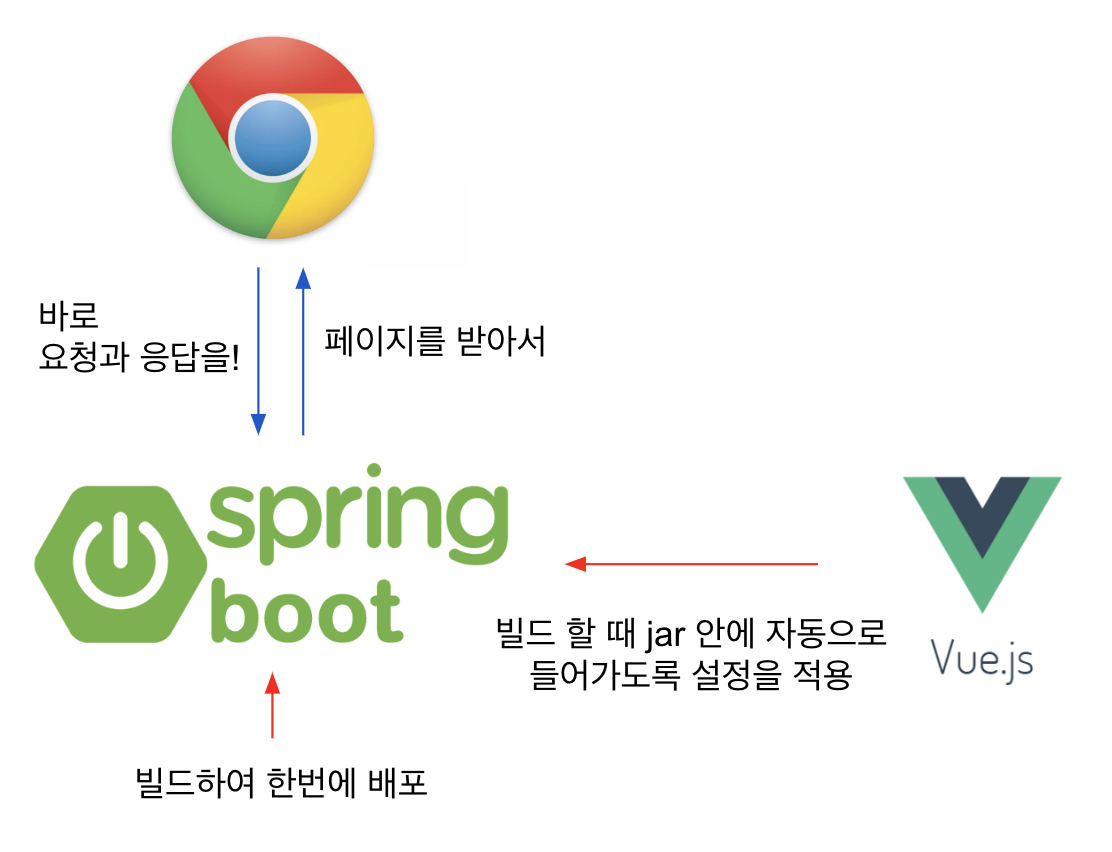

혹시나 저처럼 이 사실이 신기하신 분은 여기를 참고해 주세요!
5주차 : 대규모 데이터 처리를 위한 Batch, 그리고 Jenkins
5주차 과제는 대규모 데이터 처리를 위한 Batch와 Batch Test를 구현하고 Jenkins로 CI를 구축해 API를 배포할 수 있는 환경을 만드는 것이었습니다. 또한 Batch Job 역시 Jenkins를 이용해 관리해야 했습니다.
Batch와 Jenkins모두 처음 접해보는 병아리
과연 무사히 5주차를 넘길 수 있었을까요? (삐약…)
Batch Feedback
먼저, Batch 코드에 대한 피드백입니다!
As-Is
// Step 설정과 Reader 설정
// (1)
@Bean
@JobScope
public Step orderAmountByPaymentMethodStep() {
return stepBuilderFactory.get("orderAmountByPaymentMethodOnDateStep")
.<OrderAmountByPaymentMethodDto, OrderAmountByPaymentMethod>chunk(chunkSize)
.reader(orderAmountByPaymentMethodReader(null))
.processor(orderAmountByPaymentMethodProcessor(null))
.writer(orderAmountByPaymentMethodWriter())
.build();
}
@Bean
@StepScope
public JpaPagingItemReader<OrderAmountByPaymentMethodDto> orderAmountByPaymentMethodReader(
@Value("#{jobParameters[requestDate]}") String requestDate) { // (2)
JpaPagingItemReader<OrderAmountByPaymentMethodDto> reader = new JpaPagingItemReader<>();
Map<String, Object> parameters = new LinkedHashMap<>();
parameters.put("startDateTime", LocalDateTime.parse(requestDate + "T00:00:00"));
parameters.put("endDateTime", LocalDateTime.parse(requestDate + "T23:59:59"));
// (3)
reader.setEntityManagerFactory(entityManagerFactory);
// (4)
reader.setQueryString("SELECT NEW " +
"com.assignment.dto.OrderAmountByPaymentMethodDto(sd.paymentMethodType, SUM(sd.amount)) " +
"FROM SalesDetail AS sd " +
"WHERE sd.occurDateTime BETWEEN :startDateTime AND :endDateTime " +
"GROUP BY sd.paymentMethodType");
reader.setParameterValues(parameters);
// (5)
return reader;
}
// Processor와 Writer는 비교적 간단하여 생락 했습니다!
- Batch Job에 대해서는 이 Job이 하는 역할에 대해 주석을 자세히 적어주는 것이 좋다는 피드백을 들었습니다.
- 동료 개발자가 봤을 때 Job에 대해 한 눈에 알 수 있어야 하기 때문입니다.
- 특히나 실제로 돌고 있는 복잡한 배치가 수십개가 있다면 주석의 중요성은 더욱 커지겠죠!
- 날짜를 job parameter로 받는 것은 칭찬을 받았습니다! (어머 세상에 칭찬이라니)
- 날짜별로 Batch를 돌리는 경우 코드에
LocalDate.now()를 사용할 수 있는데, 그렇게 되면 외부에서 같은 조건을 주어도 다른 결과가 나올 수 있기 때문에 좋지 않습니다. - 특히 이슈가 발생해 과거의 특정 날짜를 돌려야 하는 경우가 있을 수도 있기 때문이죠.

칭찬을 병아리를 춤추게 만든다 ~ 삐약삐약
- 날짜별로 Batch를 돌리는 경우 코드에
JpaPagingItemReader의 필드가 많으므로 setter보다는 builder를 사용하는 것이 좋습니다.- JPQL을 사용하게 되면 Entity가 아닌 DTO로 projection을 할 때 패키지 명을 명시해주어야 합니다.
- 위의 코드에서는 패키지 명을 문자열에 넣어서 명시해주었죠. 이렇게 되면, DTO의 패키지 리팩토링이 어렵게 됩니다.
- 이럴 때
Class.getName()을 활용하면 패키지 명을 동적으로 넣어줄 수 있습니다!
- chunk size를 디폴트 page size와 같은 10으로 맞춰줬다고 하더라도, Reader에 명시적으로 chunk size로 값을 설정해주는 것이 좋습니다.
- 그래야 혹시 나중에 깜빡하고 chunk size만 바꾸는 사태를 미리 방지할 수 있기 때문입니다.
To-Be
@Bean
@StepScope
public JpaPagingItemReader<OrderAmountByPaymentMethodDto> orderAmountByPaymentMethodReader(
@Value("#{jobParameters[requestDate]}") String requestDate) {
Map<String, Object> parameters = new LinkedHashMap<>();
parameters.put("startDateTime", LocalDateTime.parse(requestDate + "T00:00:00"));
parameters.put("endDateTime", LocalDateTime.parse(requestDate + "T23:59:59"));
String queryString = String.format(
"SELECT NEW %s(sd.paymentMethodType, SUM(sd.amount)) " +
"FROM SalesDetail AS sd " +
"WHERE sd.occurDateTime BETWEEN :startDateTime AND :endDateTime " +
"GROUP BY sd.paymentMethodType", OrderAmountByPaymentMethodDto.class.getName());
JpaPagingItemReaderBuilder<OrderAmountByPaymentMethodDto> jpaPagingItemReaderBuilder = new JpaPagingItemReaderBuilder<>();
return jpaPagingItemReaderBuilder
.name("orderAmountByPaymentMethodOnDateReader")
.entityManagerFactory(entityManagerFactory)
.parameterValues(parameters)
.queryString(queryString)
.pageSize(chunkSize)
.build();
}
/* class.getName()은 패키지를 포함한다 */
@Test
public void classGetNameIncludePackage() {
String expected = "com.assignment.dto.OrderAmountByPaymentMethodDto";
String result = OrderAmountByPaymentMethodDto.class.getName();
assertThat(expected).isEqualTo(result);
}
조금더 괜찮아 졌나요??
Batch Test Code Feedback
Batch를 테스트한 코드도 피드백을 받았습니다. 몇 가지 예시는 이렇습니다!
- job parameter가 특정한 포맷을 요구한다면, 가능한 포맷과 불가능한 포맷에 대한 테스트 코드도 있어야 한다
- Entity 값을 설정하고 DB에 저장한 후 Batch를 돌려 그 결과와 설정했던 Entity 값을 비교하는 것은 비교 대상이 틀렸다.
- Batch는 DB에 들어있는 값을 읽어와 가공하기 때문이다.
- Entity 값을 설정하고 DB에 저장한 후 Batch를 돌려 나온 결과와, “DB를 통해 가져온 Entity”를 비교하는 것이 맞다.
- FAILED를 의도한 테스트는 단지 batchStatus만 검증하는 것이 아니라 실제로 jobExecution 안에 들어 있는 실패 사유를 가져와 의도한 실패가 일어났는지 확인해야 한다.
혹시 Batch에 대해 더 알고 싶으신 분은 이 시리즈를 참고하시면 좋습니다!
Jenkins Feedback
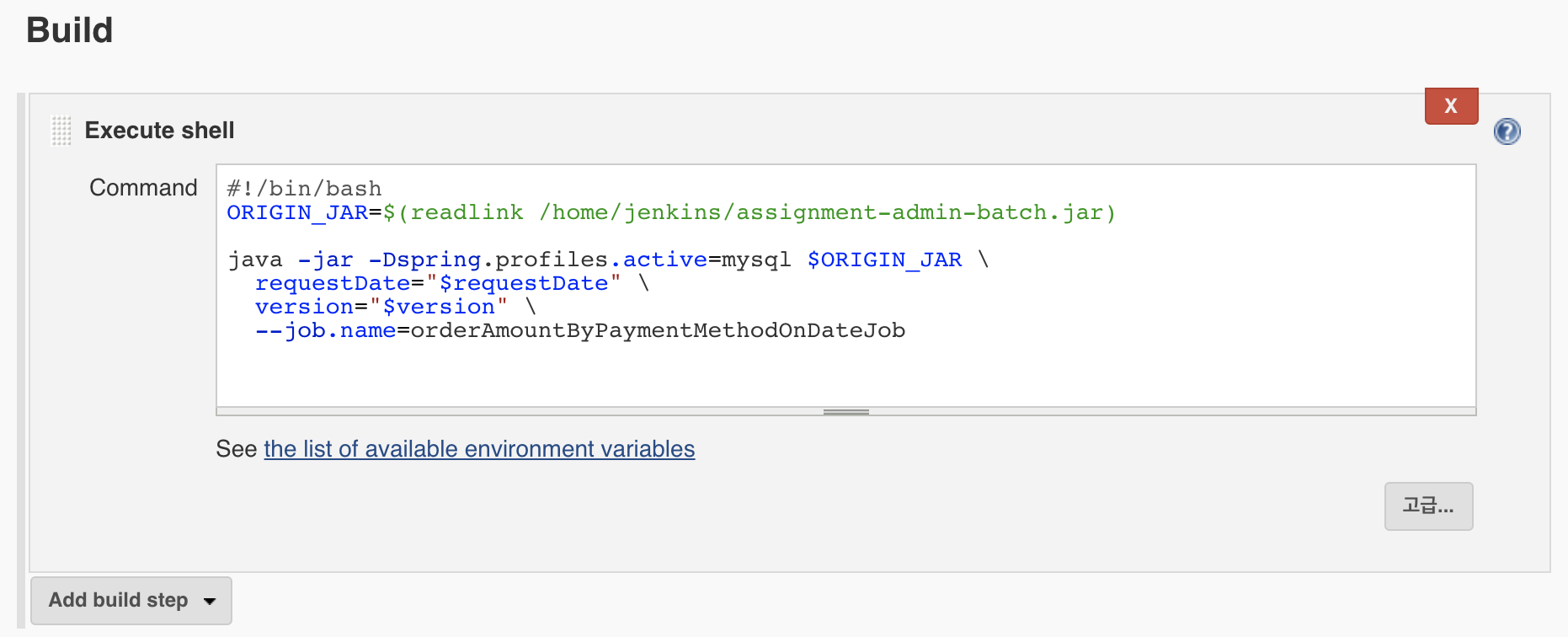
젠킨스를 구축하는 여러 방법이 있겠지만 저는 로컬에 docker를 띄우고 ngrok을 이용해서 github webhook을 걸었습니다!
피드백을 받기 전 젠킨스에서 실행하던 CI 쉘 스크립트와 배치 실행 쉘 스크립트는 이랬습니다.
As-Is
# CI 스크립트
./gradlew clean
./gradlew build -x test
# 배치 실행 스크립트
java -jar /var/lib/jenkins/workspace/job-name/batch-module/build/libs/batch-1.0.jar --spring.profiles.active=mysql parameter1=$parameter1
역시역시 잠실역 유동인구보다 더 많은 피드백을 받을 수 있었습니다

- API 모듈과 Batch 모듈은 별도의 Jenkins Job을 만들어야 했습니다. 둘은 성격이 다르기 때문인데요,
- API는 Jenkins Job이 끝나더라도 실행되어 24시간 돌아가야 해야했습니다.
- 반면, 배치는 돌아가고 있는 배치가 있다면 해당 jar 파일이 삭제되지 않고, 기존의 것을 사용하도록 해야 했습니다.
- 별도의 Jenkins Job을 만들고 pipeline을 이용해 둘을 한 번에 배포할 수 있게도 해 놓는다면 더 좋겠죠!
- CI에서 테스트는 빠질 수 없습니다.
- 하지만 위 스크립트에서는 -x 옵션으로 테스트를 빼버렸었죠.
- 이때 h2를 memory로 설정해두고 build 스크립트에 h2 실행 의존성을 적어둔다면, 어떤 환경에서라도 테스트를 할 수 있습니다!
# application.yml
spring:
datasource:
hikari:
jdbc-url: jdbc:h2:mem://localhost/~/db_name
- 실제 코드에서 사용하는 job parameter가 아니더라도 Jenkins에서는 version과 같은 parameter를 추가로 받는 것이 좋습니다.
- 그래야만 배치를 다시 돌릴 일이 있을 때 쉽게 대응할 수 있기 때문입니다.
- 끝에 스프링 --옵션과 job parameter를 한 번에 넣는 것보다는 -D옵션을 활용해 스프링 옵션은 앞으로 빼고 job parameter를 뒤에 넣는 것이 보기 편했습니다!
- 또한, 한 줄로 길게 만드는 것보다 \ 를 활용하여 한 눈에 보기 좋게 만드는 것이 좋았습니다!
- 운영에서는 더욱더 많은 파라미터가 필요하니까요.
이런 피드백을 반영한 스크립트는 이렇게 변했습니다.
To-Be
# API CI 스크립트
ARTIFACT_DIR=/home/jenkins
PROJECT_DIR=/var/lib/jenkins/workspace/assignment-api-deploy
MODULE_NAME=assignment-admin-api
ARTIFACT=$ARTIFACT_DIR/$MODULE_NAME.jar
mkdir -p $ARTIFACT_DIR
./gradlew $MODULE_NAME:clean :$MODULE_NAME:build
JAR_FILES=$(ls $PROJECT_DIR/$MODULE_NAME/build/libs)
cp $PROJECT_DIR/$MODULE_NAME/build/libs/$JAR_FILES $ARTIFACT
if [ -n "$(pgrep -f "java -jar $ARTIFACT")" ]; then
echo "Terminating existed ..."
pkill -f "java -jar $ARTIFACT"
fi
BUILD_ID=dontKillMe nohup java -jar \
-Dspring.profiles.active=mysql -Dserver.port=9090 \
$ARTIFACT &
# Batch CI 스크립트
ARTIFACT_DIR=/home/jenkins
ARCHIVE_DIR=/home/jenkins/archive
PROJECT_DIR=/var/lib/jenkins/workspace/assignment-batch-deploy
MODULE_NAME=assignment-admin-batch
mkdir -p $ARTIFACT_DIR
./gradlew :$MODULE_NAME:clean :$MODULE_NAME:build
JAR_FILES=$(ls $PROJECT_DIR/$MODULE_NAME/build/libs -r)
JAR_FILE="$( echo $JAR_FILES | awk '{split($0, JARS, " "); print JARS[1]}' )"
cp $PROJECT_DIR/$MODULE_NAME/build/libs/$JAR_FILE $ARCHIVE_DIR
ln -s -f $ARCHIVE_DIR/$JAR_FILE $ARTIFACT_DIR/$MODULE_NAME.jar
소고
길고긴 파일럿 프로젝트의 회고가 끝이 났습니다.
긴 시간이었던 만큼 느낀점도 많은데요, 파일럿 프로젝트에 대한 소고(小考, 작은 생각)도 함께 적어볼까 합니다 ㅎㅎ

함께 해주는 팀
한 달 반이라는 긴 시간 동안 한 명(?)의 병아리 개발자가 팀에 적응하고 새로운 기술을 익힐 수 있도록 배려해주신 모든 팀원분들께 감사하다는 말씀을 꼭 전하고 싶습니다!
특히 돌보미분께서는 “질문을 하나만 여쭤봐도 될까요?”라고 말씀드리고 다섯 개를 여쭤봐도 친절하게 알려주시더군요 크으.. 또, 코드 리뷰 시간이 다가오기 전에 미리 github을 보시며 리뷰할 내용을 찾기도 하시고 제가 몇 시간을 해도 풀리지 않는 문제가 있으면 직접 디버깅을 도와주시기도 했습니다! 크으.. 업무적으로 가져야할 마인드나 좋은 자세에 대해서도 많이 알려주셨습니다! 크으..
다른 개발자분들도 리뷰 시간마다 제가 더 배울 수 있도록 각자의 지식과 경험을 녹여 좋은 피드백을 많이 주셨습니다. 언제든지 질문을 해도 자세하게 알려주시고, 제가 참고할 수 있는 자료들을 직접 찾아 주시기도 했습니다! 크으..
저희 팀에는 개발자분들 뿐만이 아니라, 기획자분들도 계십니다! 제가 파일럿 프로젝트를 진행하는 동안 틈틈이 “파일럿 프로젝트는 잘 되고 계세요?”, “팀 적응에 어려운 건 없으세요?”라고 신경 써 주시는 모습에 마음이 너무 따뜻해 지더라고요. ㅎㅎ 팀의 역할과 기능, Jira & Confluence 사용법을 따로 시간 내어 알려주시기도 했습니다! 모두 감사합니다 :)
(아 저희 팀원분들 중 한 분은 틈만 나면 커피나 음료수를 사주시려고 하시던데, 자꾸 그러시면 부담되고 오예입니다 ㅎㅎ)
파일럿 프로젝트를 진행하며 아직까지 도움받기만 한 듯 하지만, 저 역시 어서 도움을 드리고 싶다는 생각을 했습니다!
그 작은 일환으로, 주말이나 짜투리 시간을 이용해 공부한 내용을 팀내 위키로 공유하려고 합니다.
저희 팀 개발자분들은 다 아시는 내용일 수 있지만, 사람의 기억력이 무한하지 않으니 ㅎㅎ 제가 꾸준히 정리해둔 글들이 언젠가 도움이 되었으면 좋겠습니다.

몰랐던 것을 알게되었다는 기쁨
파일럿 프로젝트를 진행하며 알았던 것보단 몰랐던 것이 더 많았고, 해본 것보단 안해본 것들이 더 많았습니다.
하지만 무언가를 처음 배우고 적용할 때마다 “아 이렇게 하면 이런 문제를 해결 할 수 있구나~” 또는 “아 이런 접근이면 더 우아한 해결책을 만들 수 있구나~” 라는 설레는 생각에 항상 재밌고 행복했습니다.
매일 조금씩 조금씩 성장하는 기분
오늘 보다 내일 더 나은 내가 있을 것 같은 기분
그 기분이 너무 좋았습니다.
앞으로도 처음 해보는 시도는 계속될 것 입니다. 그때마다 새로운 것을 배워 기쁘고 감사한 마음으로 성장하고 싶습니다.
아참, 이렇게 새롭게 익힌 기술과 지식은 궁극적으로 ‘고객 창출’과 ‘고객 만족’으로 이어질 수 있도록 노력하겠습니다 ㅎㅎ
앞으로의 목표
저희 회사에서는 개발자 멘토링 제도가 운영되고 있습니다. 주니어 개발자들의 고민을 시니어 개발자 분들이 함께 고민해주고 조언해주는 좋은 제도인데요, 제 멘토님께서는 최근 멘토링 시간에 이런 조언을 해주셨습니다.
주니어 때 놓칠 수 있는 것 중 하나는 ‘큰 그림’을 보는 것이다.
사실 처음 주어지는 업무는 이미 만들어진 시스템의 일부를 유지보수 하거나 기능을 추가하는 업무이다.
그렇기 때문에 큰 그림을 놓칠 수가 있는데,
더 우아한 개발자가 되기 위해서는 ‘큰 그림’을 보며 작은 것을 바꾸더라도 ‘큰 그림’에 어울리게 바꾸어야 한다.
그래야만 더 좋은 ‘큰 그림’을 그릴 수 있다.
이런 금같은 조언을 실천(?) 하기 위해서 자투리 시간을 이용해 저희 팀의 큰 그림을 보는 시간을 의식적으로 가지려고 합니다!
현재 설계되어 있는 도메인 모델을 위키로 정리하며 그 모델이 왜 그렇게 설계되었는지 팀 내 시니어 분들께 여쭤본다거나, 현재 구성되어 있는 인프라 환경을 그려보고 토이 프로젝트로 비슷한 환경을 구축하며 그 과정을 위키로 공유한다거나 등등
이렇게 노력하면 언젠가 팀 내의 ‘큰 그림’을 볼 수 있게 되지 않을까 싶습니다!!
앞으로도 재밌는 나날이 이어질 것 같아요 ㅎㅎ

긴 글 읽어주셔서 감사합니다! :)