MySQL에서 'a' = 'a '가 true로 평가된다?
• 이종립

DB 알못의 어떤 리서치
목차(이 링크는 목차를 링크합니다)
- 목차(이 링크는 목차를 링크합니다)
- 개요
- 다른 DB도 조사해 보자
- 레퍼런스를 찾아 확인하자
- PostgreSQL은 왜?
- PostgreSQL 조사
- 요약 및 감상
- 후기
- 링크 모음
- 참고 문헌
개요
안녕하세요 기계인간 이종립입니다. FC플랫폼개발팀에서 배민찬 백엔드를 개발하고 있습니다.
DB알못인 저는 업무 중에 우연히 MySQL에서 'a' = 'a '의 결과가 1로 나오는 이상한 현상을 발견하게 되었습니다.
특수한 조건에서만 발생하는 버그일까요?
또는 버그가 아닌데 내가 잘못 생각하고 있는 것인지, 다른 DB에서도 같은 일이 일어나는지 궁금해졌습니다.
그래서 다른 DB도 조사해보기로 했습니다.
차이점을 발견할 수 있다면 알아둘 만한 정보가 될 거라는 생각도 들었고요.
다른 DB도 조사해 보자
- Live SQL 18.1.2, running Oracle Database 18c Enterprise Edition - 18.1.0.0.0 (https://livesql.oracle.com 에서 테스트)
- MySQL 5.6 (http://sqlfiddle.com/ 에서 테스트)
| 테스트 | SQL | Oracle result | MySQL result |
|---|---|---|---|
| 정상 작동 확인 | select 'eq' from dual where 1 = 1 | eq | eq |
| 정상 작동 확인 | select 'eq' from dual where 1 = 0 | no data found | |
| like와 비교 | select 'eq' from dual where 'a' like 'a' | eq | eq |
| like와 비교 | select 'eq' from dual where 'a' like 'a ' | no data found | |
| = 작동 비교 | select 'eq' from dual where 'a' = 'a' | eq | eq |
| = 작동 비교 | select 'eq' from dual where 'a' = 'a ' | eq | eq |
- PostgreSQL 9.6, SQLite(WebSQL) (http://sqlfiddle.com/ 에서 테스트)
| 테스트 | SQL | PostgreSQL result | SQLite result |
|---|---|---|---|
| 정상 작동 확인 | select 1 = 1 | true | 1 |
| 정상 작동 확인 | select 1 = 0 | false | 0 |
| like와 비교 | select 'a' like 'a' | true | 1 |
| like와 비교 | select 'a' like 'a ' | false | 0 |
| = 작동 비교 | select 'a' = 'a' | true | 1 |
| = 작동 비교 | select 'a' = 'a ' | false | 0 |
- MS SQL Server 2017 (http://sqlfiddle.com/ 에서 테스트)
| 테스트 | SQL | SQL Server result |
|---|---|---|
| 정상 작동 확인 | with dual(dummy) as (select 'x') select 'eq' from dual where 1=1 | eq |
| 정상 작동 확인 | with dual(dummy) as (select 'x') select 'eq' from dual where 1=0 | |
| like와 비교 | with dual(dummy) as (select 'x') select 'eq' from dual where 'a' like 'a' | eq |
| like와 비교 | with dual(dummy) as (select 'x') select 'eq' from dual where 'a' like 'a ' | |
| = 작동 비교 | with dual(dummy) as (select 'x') select 'eq' from dual where 'a' = 'a' | eq |
| = 작동 비교 | with dual(dummy) as (select 'x') select 'eq' from dual where 'a' = 'a ' | eq |
종합
종합해보니 다음과 같은 결과를 얻을 수 있었습니다.
제가 조사한 결과 중에서는 PostgreSQL 과 SQLite 만 'a'와 'a '를 다른 값으로 평가하는군요.
| 조건 | Oracle | MySQL | PostgreSQL | SQLite | SQL Server | 모두 같은 결과인가? |
|---|---|---|---|---|---|---|
| 1 = 1 | true | true | true | true | true | 같다 |
| 1 = 0 | false | false | false | false | false | 같다 |
| 'a' like 'a' | true | true | true | true | true | 같다 |
| 'a' like 'a ' | false | false | false | false | false | 같다 |
| 'a' = 'a' | true | true | true | true | true | 같다 |
| 'a' = 'a ' | true | true | false | false | true | 다르다 |
레퍼런스를 찾아 확인하자
여러 DB를 확인했더니 그렇게 돌아가더라 하고 끝나면 안 되겠죠?
레퍼런스 문서를 찾아보기로 했습니다.
MySQL 레퍼런스 매뉴얼을 찾아보자
MySQL 5.6 Reference Manual을 확인해보니 버그가 아닙니다.
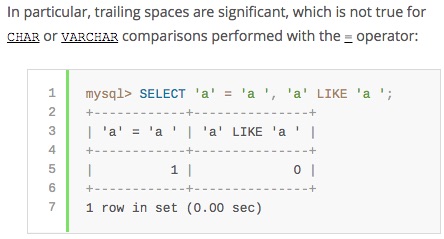
이럴 수가……. DB알못은 그저 혼란스러울 뿐입니다.
책을 찾아보자
혼란스럽던 차에 마침 개발실 서가에 가보니 “SQL 전문가 가이드”라는 책이 꽂혀 있습니다.
표지에 “국가공인 2013 Edition” 이라 인쇄되어 있으니 일단 국가를 믿고 참고해 보도록 합니다.
한참 책을 뒤지다 보니 159쪽에서 CHAR를 비교하는 일에 대한 내용을 발견할 수 있었습니다.
CHAR에서는 문자열을 비교할 때 공백(BLANK)을 채워서 비교하는 방법을 사용한다. 공백 채우기 비교에서는 우선 짧은 쪽의 끝에 공백을 추가하여 2개의 데이터가 같은 길이가 되도록 한다. 그리고 앞에서부터 한 문자씩 비교한다. 그렇기 때문에 끝의 공백만 다른 문자열은 같다고 판단된다. 그에 반해 VARCHAR 유형에서는 맨 처음부터 한 문자씩 비교하고 공백도 하나의 문자로 취급하므로 끝의 공백이 다르면 다른 문자로 판단한다.
오호 드디어 알겠습니다.
비교하려는 두 문자열의 길이가 다른 경우, 짧은 쪽에 공백을 이어붙여 길이를 똑같이 만든 다음 비교하기 때문에 발생하는 일이었습니다.
이런 식이라면 'a'와 'a '를 비교해도 'a '와 'a '를 비교하는 것과 똑같을 수밖에 없겠네요.
그런데 왜 이렇게 하는 것일까요? 그냥 길이가 다르면 FALSE 라고 하면 안 되는 이유라도 있는 것일까요?
길이를 왜 조정하는 것일까?
MySQL 때문에 시작한 일이었으니 일단 MySQL 레퍼런스 문서를 좀 더 찾아봤습니다.
다음 문장이 눈에 띄는군요.
When CHAR values are stored, they are right-padded with spaces to the specified length.
When CHAR values are retrieved, trailing spaces are removed unless the PAD_CHAR_TO_FULL_LENGTH SQL mode is enabled.
- CHAR 값을 저장할 때는, 정의된 길이를 맞추기 위해 오른쪽에 공백(들)을 붙입니다.
- CHAR 값을 가져올 때는, 따라붙인 공백은 제거합니다.
- (PAD_CHAR_TO_FULL_LENGTH 모드가 비활성화된 경우)
그리고 여기에서도 같은 문제를 언급하는 예제가 있습니다.
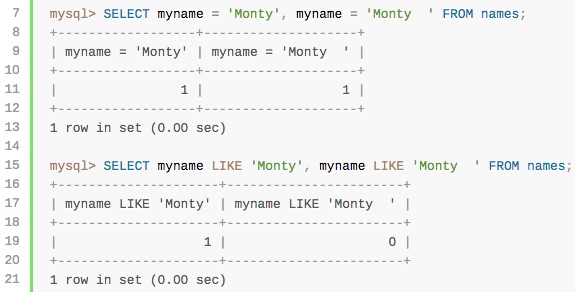
다음과 같은 테이블도 있네요.
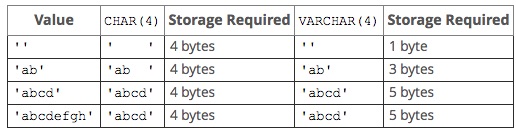
CHAR(4) 컬럼에 'ab'를 저장하면 'ab__'처럼 된다는 말이군요. (이제부터는 가독성을 위해 공백 대신 _ 를 쓰겠습니다.)
CHAR는 VARCHAR 처럼 가변 길이가 아니기 때문에, 길이를 맞추기 위해 컬럼 정의에 따라 우측에 공백이 추가되어 보관됩니다.
그렇다면 CHAR(4)에 저장한 'ab'와 CHAR(6)에 저장한 'ab'를 정확히 비교하려면 두 가지 방법이 있을 것입니다.
- 두 문자열의 오른쪽 공백을 모두 지우고 비교한다.
- 짧은 쪽 문자열에 공백을 추가해 긴 쪽과 길이를 맞추고 비교한다.
만약 이런 방법을 사용하지 않는다면 'ab__'와 'ab____'를 비교하는 셈이 됩니다.
즉, 저장하기 전엔 'ab'로 똑같았던 값을 저장된 값을 가져와 비교하면 무조건 FALSE가 나오는 황당한 일이 벌어집니다.
| CHAR(4) | CHAR(6) | 비교 결과 | |
|---|---|---|---|
| 원본 문자열 | 'ab' | 'ab' | |
| 저장된 문자열 | 'ab__' | 'ab____' | |
| NO PAD 방식 비교 | 'ab__' | 'ab____' | FALSE |
| PAD 방식 비교 | 'ab____' | 'ab____' | TRUE |
좀 이상하게 느껴지긴 해도 짧은 쪽에 PAD를 추가해 'ab____'로 바꾼 다음 비교하는 것이 납득이 갑니다.
이렇게 하지 않으면 길이가 다른 모든 타입의 컬럼에 저장된 문자열을 비교하는 것이 불가능할 것입니다.
FALSE만 나오게 되겠죠.
짧은 쪽에 맞추기 위해 긴 쪽의 문자를 지우면 알고리즘이 지저분할 테니, 공백 PAD를 붙이는 심플한 방법 쪽을 선택했을 거라는 생각도 듭니다.
CHAR 문자열을 저장하는 방식 때문에 PAD를 사용한 비교가 도입된 것이라는 추측이 드는군요.
SQL-92 도 찾아보자
그러나 멋대로 결론 내리기 전에 먼저 문자열 저장과 비교에 대한 표준을 찾아보는 것이 순서일 것 같습니다.
SQL 표준을 명시하는 SQL-92에서 space로 검색해서 하나하나 찾다 보니 234쪽에서 다음과 같은 문단을 찾을 수 있었습니다.
데이터를 저장할 때의 일반 규칙 중 하나입니다.
c) If the data type of T is fixed-length character string with
length in characters L and the length in characters M of V
is less than L, then the first M characters of T are set to V
and the last L-M characters of T are set to <space>s.
이게 한 문장이라니……. 침착하게 읽고 정리해보니 다음과 같은 내용이었습니다.
- 고정된 길이 L로 정의된 데이터 타입 T가 있다.
- 길이가 V인 문자열 M이 있다.
- 문자열 길이 V는 L 보다 작다.
- 문자열 M의 V개 만큼의 문자들인 T는 그대로 저장(set)한다.
- 그러면 데이터 타입 T에는 L - M 개의 빈 자리가 남는데, 빈 자리는 space로 채운다.
만약 문자열이 정의된 길이보다 짧을 경우 오른쪽을 space로 채운다는 말이로군요. 이 방식이 표준이 맞네요.
그렇다면 이번에는 비교에 대한 표준을 찾아볼 차례인 것 같습니다.
위에서 조사했을 때에는 Oracle, MySQL, SQL Server 와 PostgreSQL, SQLite의 결과가 모두 같지는 않았습니다.
문자열 비교에 대해 표준을 지키지 않는 DB가 있다는 말일까요?
역시 SQL-92에서 comparison으로 일일이 찾아보니 208쪽에서 찾아냈습니다.
3) The comparison of two character strings is determined as follows:
a) If the length in characters of X is not equal to the length
in characters of Y, then the shorter string is effectively
replaced, for the purposes of comparison, with a copy of
itself that has been extended to the length of the longer
string by concatenation on the right of one or more pad char-
acters, where the pad character is chosen based on CS. If
CS has the NO PAD attribute, then the pad character is an
implementation-dependent character different from any char-
acter in the character set of X and Y that collates less
than any string under CS. Otherwise, the pad character is a
<space>.
찬찬히 읽어보니 다음과 같은 정보를 알 수 있었습니다.
- 두 문자열을 비교할 때 X의 길이가 Y의 길이와 다르다면
- 짧은 쪽의 문자열은 비교 목적 상의 효율을 위해(effectively) 교체될 수 있다.
- 짧은 쪽의 문자열을 복사하고 pad 문자를 이어붙여, 긴 쪽의 문자열과 같은 길이를 가진 문자열을 만든다.
- PAD 문자는 space로 한다.
아하. 국가공인 책에 나왔던 'a' = 'a '를 'a ' = 'a '로 만들어 비교하는 방식이 표준이 맞는군요.
그리고 effectively라는 표현은 아마도 비교 알고리즘의 효율성이 아니라 각기 길이가 다른 여러 타입을 비교하는 관점에서의 효율을 말하는 것 같습니다.
만약 알고리즘상의 효율이라면 PADDING을 하지 않고 그냥 왼쪽 글자부터 비교했을 테니까요.
그렇다면 이제 PostgreSQL 과 SQLite 에서 'a' = 'a ' 가 FALSE로 평가되도록 구현한 이유가 궁금해지는군요.
그리고 PostgreSQL이 CHAR를 저장하는 방식도 뭔가 표준과 다를 수 있다는 생각이 듭니다.
PostgreSQL은 왜?
그런데 아무래도 저 혼자서만 궁금증을 느낀 것은 아닌 모양입니다.
운이 좋았는지 Albe Laurenz라는 분이 2013년 01월 17일에 PostgreSQL 개발자들에게 보낸 이메일을 발견할 수 있었습니다.
That would effectively mean that 'a'='a ' is TRUE for
all character string types.
Of the DBMS I tested, Microsoft SQL Server and MySQL gave me
that very result, while PostgreSQL and Oracle gave me FALSE.
Does anybody know if we deviate from the standard on purpose
in this case?
편지의 내용을 요약하자면 다음과 같습니다. (이메일도 편지니까 편지라고 하고 싶습니다.)
- SQL 표준을 읽어보면 'a' = 'a ' 가 TRUE여야 한다.
- 테스트해보니까 SQL Server와 MySQL은 표준과 같이 TRUE를 리턴한다.
- 그런데 PostgreSQL과 Oracle은
FALSE를 리턴하더라. - 표준대로 구현하지 않은 이유를 알고 싶습니다.
오 제 궁금증과 일치하는 질문이네요.
그렇다면 이 편지에 대한 PostgreSQL 측의 답장도 읽어봐야 할 것 같습니다.
답장을 한 사람은 컴퓨터 과학자이자 PostgreSQL 개발팀의 멤버인 Tom Lane입니다.
The PAD case is specifying the way that CHAR(n) comparison should work.
(We don't expose the PAD/NO PAD distinction in any other way than
CHAR vs VARCHAR/TEXT types.)
AFAICS, the NO PAD case is ignorable BS: they are basically specifying
implementation not semantics there, and in a way that is totally
brain-dead. There isn't necessarily any such character as the one they
blithely posit. Moreover, the whole description seems to assume that
string comparison is single-pass left-to-right, which has little to do
with any modern collation specification. We just rely on strcmp to
decide that shorter strings are "less" than longer ones, which is the
point of this spec AFAICT.
Note that we don't actually do CHAR(n) comparison like that either,
but instead choose to strip trailing spaces before the comparison.
In any case, the most significant word in that whole paragraph is
"effectively", which means you can do it however you want as long
as you get an equivalent comparison result.
> That would effectively mean that 'a'='a ' is TRUE for
> all character string types.
In the PAD case, yes. Else no.
> Of the DBMS I tested, Microsoft SQL Server and MySQL gave me
> that very result, while PostgreSQL and Oracle gave me FALSE.
This probably has more to do with what these systems think the
data type of an undecorated literal is, than with whether they do
trailing-space-insensitive comparison all the time.
Tom Lane의 편지의 내용을 요약하자면 다음과 같습니다.
- PAD 방식은 CHAR(n) 끼리의 비교가 돌아가게 만들기 위한 것이다.
- CHAR와 VARCHAR/TEXT 사이의 문제라면 몰라도 PAD/NO PAD 방식에 대해 논쟁하고 싶지는 않다.
- PAD/NO PAD 방식은 굳이 Basic Spec을 따를 필요가 없다고 본다.
- 표준은 기본적인 사항을 기재했을 뿐이며 그 이상의 의미는 없다.
- 똑똑한 방법도 아니다. (실제로는 brain-dead 라는 강한 표현을 씀)
- 표준의 의도는 그냥 왼쪽에서 오른쪽으로 문자열을 검사하라는 것으로 추정된다.
- 우리는 그냥 strcmp를 써서 짧은 문자열이 긴 문자열보다 짧다는 것만 알아낼 뿐이다.
- 우리는 문자열 비교를 위해 뒤쪽 공백을 제거한다.
- 표준 문서에 있는 “effectively”라는 단어의 의미는 같은 비교 결과가 나온다면 원하는 방식으로 구현해도 된다는 말이다.
- 그리고 'a' = 'a '는 PAD 방식을 쓴다면 모든 문자열 타입에서 TRUE가 되고, 그 외의 경우라면
FALSE가 된다. - 이 문제는 문자열 비교와 trailing space의 관계보다는, 비인정(undecorated) 문자의 데이터 타입을 시스템이 어떻게 고려하는지와 더 깊은 관련이 있는 문제라고 본다.
영어 실력이 딸려서 더 어렵게 느껴집니다. 그러나 적어도 표준이나 아니냐의 이분법적인 관점으로 접근하는 것이 곤란하다는 생각이 드네요.
그리고 시스템의 측면에서 문자를 바라보는 시각도 제시해주는군요.
아마도 이런 생각이 PostgreSQL의 비교 방식에도 영향을 준 모양입니다.
PostgreSQL 조사
그런데 아직 저장 방식과 PAD / NO PAD의 관계에 대해 아직 뚜렷하게 이해하지 못한 것 같은 느낌이 듭니다.
그래서 일단 다음과 같이 간단한 테이블을 MySQL과 PostgreSQL에 하나씩 만들고 레코드 하나를 입력했습니다.
CREATE TABLE guest (
vc1 varchar(10) DEFAULT '',
vc2 varchar(20) DEFAULT '',
c1 char(30) DEFAULT '',
c2 char(40) DEFAULT ''
)
insert into guest (vc1, vc2, c1, c2)
values ('test', 'test ', 'test', 'test ');
참고로 vc2와 c2는 'test__'로 같은 입력값이며, 오른쪽 공백이 두 개입니다.
그리고 다음과 같이 테스트를 수행해 보았습니다.
CHAR / VARCHAR 저장 길이 테스트
| 테스트 1 | SQL | MySQL | PostgreSQL |
|---|---|---|---|
| 테스트 1.1 | select length(c1), length(c2) from guest; | 30, 40 | 4, 4 |
| 테스트 1.2 | select length('test'), length('test ') from guest; | 4, 6 | 4, 6 |
| 테스트 1.3 | select length(vc1), length(vc2) from guest; | 4, 6 | 4, 6 |
테스트 1.1의 결과를 보면 MySQL과 PostgreSQL의 결과가 다릅니다.
- MySQL에서
'test '로 입력한 c2의 길이가 40으로 나오는 것을 보면- MySQL은 CHAR를 저장할 때 오른쪽에 공백 PAD를 추가한다는 것을 알 수 있습니다.
- PostgreSQL에서
'test '로 입력한 c2의 길이가 4로 나오는 것을 보면- PostgreSQL은 CHAR를 저장할 때 오른쪽의 공백 PAD를 삭제하고 있다는 것을 알 수 있습니다.
또한, 테스트1.2의 결과를 보면
- 저장하지 않은 CHAR의 PAD는 삭제하지 않는다는 사실을 알 수 있습니다.
- 타입이 정의되지 않았기 때문이겠죠.
한편 테스트 1.3의 결과를 보면 VARCHAR는 입력값을 그대로 저장하고 있습니다.
VARCHAR와 CHAR를 비교해보면 의미 있는 결과를 얻을 수 있을 것 같네요.
VARCHAR / CHAR 비교 테스트
| 테스트 2 | SQL | MySQL | PostgreSQL |
|---|---|---|---|
| 테스트 2.1 | select count(*) from guest where vc1 = c1 | 1 | 1 |
| 테스트 2.2 | select count(*) from guest where vc1 = c2 | 1 |
1 |
| 테스트 2.3 | select count(*) from guest where vc2 = c1 | 1 | 1 |
| 테스트 2.4 | select count(*) from guest where vc2 = c2 | 1 |
1 |
| 테스트 2.5 | select count(*) from guest where c1 = c2; | 1 | 1 |
| 테스트 2.6 | select count(*) from guest where vc1 = vc2; | 1 | 0 |
이 테스트 결과를 보니 Tom Lane의 말이 좀 더 와닿는군요.
- 테스트 2.2와 2.4를 보면
- 길이가 다른 값들을 비교했는데도, MySQL과 PostgreSQL이 똑같은 결과를 출력합니다.
- 즉 PostgreSQL이
'test'로 입력했던 값과'test '로 입력했던 값에 대해 같은 문자열이라고 리턴한 것입니다.
물론 PostgreSQL은 저장할 때 오른쪽 공백을 없애고, MySQL은 저장할 때 오른쪽 공백을 추가했겠지만, 결과는 똑같습니다.
- 테스트 2.6을 보면
- MySQL은 길이가 다른 두 VARCHAR 값이 같다고 합니다. VARCHAR 타입에도 PAD 방식을 사용하는 모양입니다.
- PostgreSQL은 다르다는 결과가 나왔습니다. PAD를 제거하는 방식은 VARCHAR에는 사용하지 않는 모양입니다.
VARCHAR / 타입이 정의되지 않은 CHAR 비교 테스트
다음 테스트는 VARCHAR와 타입이 정의되지 않은 CHAR의 비교입니다.
| 테스트 3 | SQL | MySQL | PostgreSQL |
|---|---|---|---|
| 테스트 3.1 | select count(*) from guest where vc1 = 'test' | 1 | 1 |
| 테스트 3.2 | select count(*) from guest where vc1 = 'test ' | 1 | 0 |
테스트 3.2를 보면
- MySQL은 VARCHAR와 CHAR를 비교할 때에도 PAD를 추가해 비교하고 있는 것으로 보입니다.
- PostgreSQL은 타입이 정의되지 않은 CHAR는 공백을 삭제하거나 추가하지 않는 듯합니다.
마지막 테스트 - 공백을 이어붙이면 어떨까?
| 테스트 3 | SQL | MySQL | PostgreSQL |
|---|---|---|---|
| 테스트 3.1 | select count(*) from guest where c1 = c2; | 1 | 1 |
| 테스트 3.2 | select count(*) FROM guest WHERE c1 || ' ' = c2; | 0 | 0 |
| 테스트 3.3 | select count(*) from guest where vc1 = vc2; | 1 | 0 |
| 테스트 3.4 | select count(*) FROM guest WHERE vc1 || ' ' = vc2; | 0 | 0 |
테스트 3.1과 3.3은 위에서 수행했던 테스트를 다시 한 것입니다.
테스트 3.2와 3.4가 공백을 이어붙이는 경우인데, MySQL에서도 이어 붙이는 경우에 대해서는 PADDING을 하지 않는군요.
요약 및 감상
- MySQL은 CHAR와 VARCHAR 모두 PAD 방식으로 비교한다.
- PostgreSQL은 CHAR를 저장할 때, PAD를 추가하는 방식이 아니라 제거하는 방식으로 저장한다.
- 그 결과, 저장된 CHAR를 기준으로 보면 PADDING을 사용한 방식과 같은 결과를 내놓는다.
- 타입을 정의하지 않은 CHAR의 비교에 대해서 PAD를 사용할지 말지는 DB마다 다를 수 있다.
- PADDING 방식의 원인은 CHAR 타입을 저장하는 방식과 관련이 있는 것으로 추측된다.
어쩌다보니 MySQL과 PostgreSQL의 비교로 끝이 났습니다.
그러나 어느쪽이 더 표준을 잘 지키고 어느 쪽이 더 바람직하다는 결론은 아닙니다.
다만, 개인적으로는 PostgreSQL이 문자열 비교에 대해 제가 갖고 있던 상식과 일치하는 느낌이라 종전보다 강한 호감을 갖게 되었습니다.
개념의 혼동을 최소화할 수 있는 선택을 선호하기 때문입니다.
후기
사실 이 글은 제가 2016년 6월에 우아한형제들 사내 위키에 쓰다 만 글을 토대로 새로 작성한 것입니다.
원본은 각 DB 비교하는 부분까지 있었으니 분량이 3배 이상 늘었네요.
모든 테스트는 2018년 2월 25일에 다시 수행하였으며, 2016년의 DB2 테스트 결과는 삭제하였습니다.
예전에 DB2를 테스트했던 웹 사이트에서 DB2를 선택하는 옵션이 사라졌기 때문입니다.
대신, 2016년에 “다음에 알아보기로” 했었던 PostgreSQL의 이야기를 조사할 수 있어서 매우 기쁘고 재미있었습니다.
긴 글 읽어주셔서 감사합니다.
의견과 격려를 주신 최광훈님, 최윤석님, 김정환님께도 감사를 드립니다.
그리고 마지막으로, 이렇게 어려운 DB를 관리해주시는 세상의 모든 DBA님들께 존경과 감사를 드립니다.
링크 모음
- 테스트
- 문서
- PostgreSQL 관련
- SQLite 관련
참고 문헌
- 서강수, The Guide for SQL Professional SQL 전문가 가이드 : 2013 Edition, 서울시 : 한국데이터베이스진흥원, 2013년 6월 17일 초판 발행
EOB